
बिग डेटा टेक्नोलॉजी क्या है?
जैसा कि हम जानते हैं, डेटा लगातार विकसित हो रहा है। डेटा की वृद्धि ने मानव मन को निकालने, विश्लेषण करने और उससे निपटने के लिए चुनौती दी है। ऐसा इसलिए है क्योंकि डेटा से निपटने के पारंपरिक तरीके इस बड़े डेटा का समर्थन करने में विफल हो रहे हैं। बिग डेटा आमतौर पर तीन अवधारणाओं द्वारा वर्णित किया जाता है: वॉल्यूम, विविधता और वेग।
डेटा अब हर कंपनी की सबसे महत्वपूर्ण संपत्ति बन गया है। इस बड़े डेटा का विश्लेषण करने से कंपनी को अपने ग्राहक के व्यवहार का विश्लेषण करने में मदद मिलती है और डेटा से जुड़े निर्णयों से जुड़ी प्रासंगिक चीजों की भविष्यवाणी करने से संगठन को और अधिक भरोसेमंद कदम उठाने और मजबूत रणनीति बनाने में मदद मिलती है।
आज के युग में किस गति के साथ डेटा बढ़ रहा है, यह जानकर, बिग डेटा निकट भविष्य में काम करने के लिए एक विशाल क्षेत्र होगा। सभी छात्रों, फ्रेशर्स, पेशेवरों को उभरती हुई बिग डेटा तकनीकों के साथ खुद को अपडेट रखने की आवश्यकता होगी । अपने आप को अप टू डेट रखने से किसी के पेशेवर रास्ते में एक शानदार और सफल करियर आएगा।
बिग डेटा टेक्नोलॉजी
यहाँ मैं इस पर एक स्पष्ट व्याख्या के साथ कुछ बिग डेटा तकनीकों को सूचीबद्ध कर रहा हूँ, जिससे आपको आगामी रुझानों और प्रौद्योगिकी के बारे में पता चल सके:
-
अपाचे स्पार्क:
यह एक तेज़ बिग डेटा प्रोसेसिंग इंजन है । यह डेटा के लिए वास्तविक समय प्रसंस्करण को ध्यान में रखते हुए बनाया गया है । मशीन लर्निंग की इसकी समृद्ध लाइब्रेरी एआई और एमएल के अंतरिक्ष में काम करने के लिए अच्छा है। यह डेटा को समानांतर और क्लस्टर किए गए कंप्यूटर पर संसाधित करता है। स्पार्क द्वारा उपयोग किया जाने वाला मूल डेटा प्रकार RDD है (लचीला वितरित डेटा सेट)
-
NoSQL डेटाबेस:
यह गैर-संबंधपरक डेटाबेस है जो डेटा का त्वरित भंडारण और पुनः प्राप्ति प्रदान करता है। सभी प्रकार के डेटा जैसे संरचित, अर्ध-संरचित, असंरचित और बहुरूपी डेटा से निपटने की इसकी क्षमता अद्वितीय है। कोई SQL डेटाबेस निम्न प्रकार के नहीं हैं:
- दस्तावेज़ डेटाबेस : यह दस्तावेज़ों के रूप में डेटा संग्रहीत करता है जिसमें कई अलग-अलग कुंजी-मूल्य जोड़े हो सकते हैं।
- ग्राफ़ स्टोर : यह डेटा संग्रहीत करता है जो आमतौर पर सोशल मीडिया डेटा जैसे नेटवर्क के रूप में संग्रहीत होता है।
- की-वैल्यू स्टोर : ये सबसे सरल NoSQL डेटाबेस हैं । डेटाबेस में प्रत्येक और प्रत्येक आइटम को उसके नाम के साथ एक विशेषता नाम (या ‘कुंजी’) के रूप में संग्रहीत किया जाता है।
- वाइड-कॉलम स्टोर : यह डेटाबेस पंक्ति-आधारित प्रारूप के बजाय स्तंभ प्रारूप में डेटा संग्रहीत करता है। कैसंड्रा और HBase इसके अच्छे उदाहरण हैं।
-
अपाचे काफ्का:
काफ्का एक वितरित घटना स्ट्रीमिंग मंच है जो हर दिन बहुत सारी घटनाओं को संभालता है। जैसा कि यह तेज़ और स्केलेबल है, यह वास्तविक समय स्ट्रीमिंग डेटा पाइपलाइनों के निर्माण में सहायक है जो सिस्टम या एप्लिकेशन के बीच डेटा को मज़बूती से प्राप्त करते हैं।
-
अपाचे ऊज़ी:
यह Hadoop नौकरियों का प्रबंधन करने के लिए वर्कफ़्लो शेड्यूलर सिस्टम है। इन वर्कफ़्लो नौकरियों को क्रियाओं के लिए निर्देशित एसाइक्निकल ग्राफ़ (DAGs) के रूप में निर्धारित किया गया है।
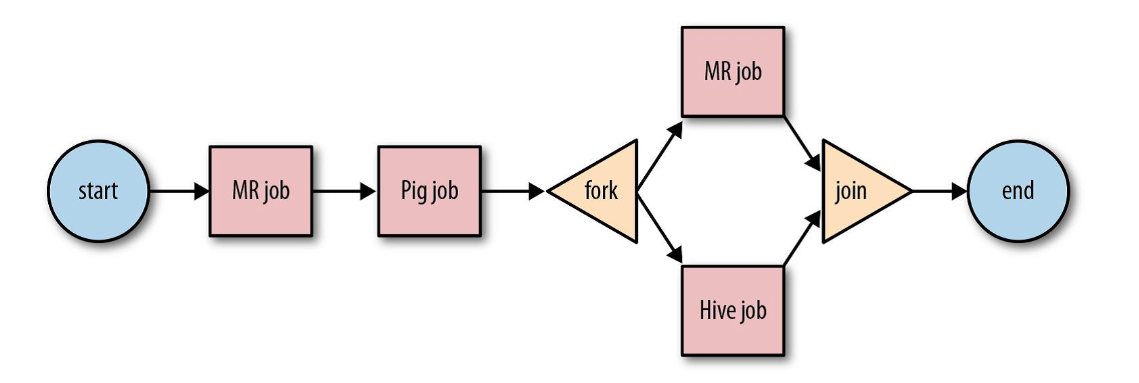
स्रोत: Google
बिग डेटा गतिविधियों के लिए इसका स्केलेबल और संगठित समाधान।
-
अपाचे एयरफ्लो:
यह एक प्लेटफॉर्म है जो वर्कफ़्लो को शेड्यूल और मॉनिटर करता है। स्मार्ट शेड्यूलिंग परियोजना को कुशलतापूर्वक निष्पादित करने में अंत में मदद करता है। विफलता के एक उदाहरण के दौरान एयरफ्लो में डीएजी उदाहरण को फिर से चलाने की क्षमता होती है। इसका समृद्ध उपयोगकर्ता इंटरफ़ेस विभिन्न चरणों में चल रही पाइपलाइनों की कल्पना करना आसान बनाता है जो उत्पादन, प्रगति की निगरानी, और जरूरत पड़ने पर समस्याओं का निवारण करते हैं।
-
अपाचे बीम:
यह डेटा प्रसंस्करण पाइपलाइनों को परिभाषित करने और निष्पादित करने के लिए एक एकीकृत मॉडल है, जिसमें ईटीएल और निरंतर स्ट्रीमिंग शामिल हैं। अपाचे बीम फ्रेमवर्क आपके एप्लिकेशन लॉजिक और बिग डेटा इकोसिस्टम के बीच एक अमूर्तता प्रदान करता है, क्योंकि इसमें कोई एपीआई मौजूद नहीं है जो कि सभी फ्रेमवर्क जैसे कि हडोप, स्पार्क आदि को बांधता है।
-
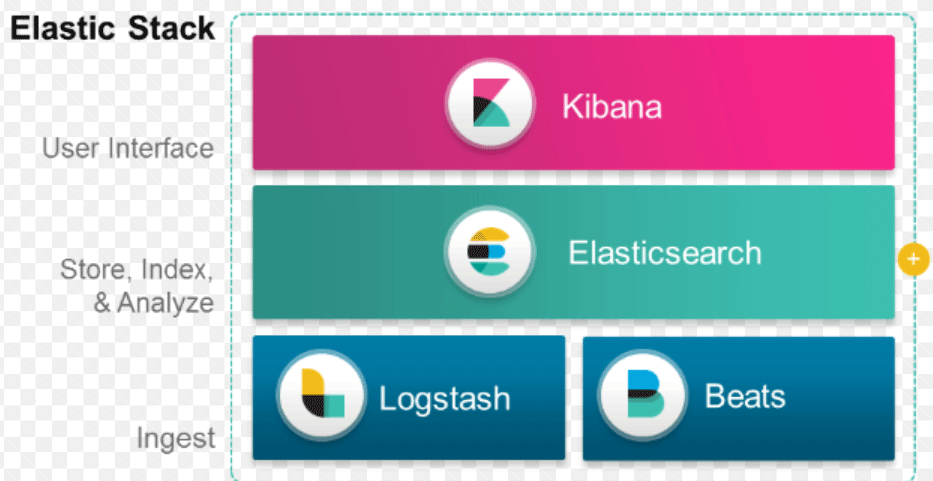
एल्क स्टैक:
ELK को एलेस्टिक्स खोज, लॉगस्टैश और किबाना के लिए जाना जाता है।
इलास्टिसर्च एक स्कीमा-कम डेटाबेस (जो हर एक क्षेत्र को अनुक्रमित करता है) जिसमें शक्तिशाली खोज क्षमताएं होती हैं और आसानी से मापनीय होती हैं।
लॉगस्टैश एक ईटीएल उपकरण है जो हमें एलिटिक्स खोज में घटनाओं को लाने, बदलने और स्टोर करने की अनुमति देता है।
किबाना एलेस्टिक्स खोज के लिए एक डैशबोर्डिंग उपकरण है, जहां आप संग्रहीत सभी डेटा का विश्लेषण कर सकते हैं। किबाना से निकाले गए एक्शन योग्य अंतर्दृष्टि एक संगठन के लिए रणनीति बनाने में मदद करती है। परिवर्तनों को पकड़ने से लेकर भविष्यवाणी करने तक, किबाना हमेशा बहुत उपयोगी साबित हुई है।
-
डोकर और कुबेरनेत:
ये उभरती हुई प्रौद्योगिकियां हैं जो लिनक्स कंटेनरों में चलने वाले अनुप्रयोगों में मदद करती हैं। डॉकर उपकरण का एक खुला स्रोत संग्रह है जो आपकी मदद करता है “बिल्ड, शिप, और रन एनी ऐप, एनीवेयर”।
कुबेरनेट भी एक खुला स्रोत कंटेनर / ऑर्केस्ट्रेशन प्लेटफॉर्म है, जिससे बड़ी संख्या में कंटेनर एक साथ काम कर सकते हैं। यह अंततः परिचालन बोझ को कम करता है।
-
TensorFlow:
यह एक ओपन-सोर्स मशीन लर्निंग लाइब्रेरी है जिसका उपयोग डीप लर्निंग मॉडल को डिज़ाइन करने, बनाने और प्रशिक्षित करने के लिए किया जाता है। सभी संगणनाएँ TensorFlow में डेटा प्रवाह ग्राफ़ के साथ की जाती हैं। रेखांकन में नोड्स और किनारे शामिल हैं। नोड्स गणितीय संचालन का प्रतिनिधित्व करते हैं, जबकि किनारों डेटा का प्रतिनिधित्व करते हैं।
TensorFlow अनुसंधान और उत्पादन के लिए सहायक है। इसे ध्यान में रखते हुए बनाया गया है, ताकि यह कई सीपीयू या जीपीयू और यहां तक कि मोबाइल ऑपरेटिंग सिस्टम पर चल सके। इसे पायथन, C ++, R, और Java में लागू किया जा सकता है।
-
प्रेस्टो:
प्रेस्टो फेसबुक द्वारा विकसित एक खुला स्रोत एसक्यूएल इंजन है, जो डेटा के पेटाबाइट्स को संभालने में सक्षम है। हाइव के विपरीत, प्रेस्टो MapReduce तकनीक पर निर्भर नहीं करता है और इसलिए डेटा प्राप्त करने में तेज है। इसकी वास्तुकला और इंटरफ़ेस अन्य फ़ाइल सिस्टम के साथ बातचीत करने के लिए काफी आसान है।
कम विलंबता, और आसान इंटरैक्टिव क्वेरी के कारण, आजकल बड़े डेटा को संभालने के लिए यह बहुत लोकप्रिय हो रहा है।
-
पॉलीबेस:
पॉलीबेस पीडीडब्ल्यू (समानांतर डेटा वेयरहाउस) में संग्रहीत डेटा से एक्सेस करने के लिए SQL सर्वर के शीर्ष पर काम करता है । PDW संबंधपरक डेटा की किसी भी मात्रा के प्रसंस्करण के लिए बनाया गया है और Hadoop के साथ एकीकरण प्रदान करता है।
-
हाइव:
हाइव बड़े डेटासेट पर डेटा क्वेरी और डेटा विश्लेषण के लिए उपयोग किया जाने वाला एक प्लेटफ़ॉर्म है। यह HiveQL नामक SQL जैसी क्वेरी भाषा प्रदान करता है, जो आंतरिक रूप से MapReduce में परिवर्तित हो जाती है और फिर संसाधित हो जाती है।
डेटा के तेजी से विकास और बड़े डेटा प्रौद्योगिकी के विश्लेषण के लिए संगठन के विशाल प्रयास ने बाजार में कई परिपक्व प्रौद्योगिकियों को लाया है कि उन्हें जानना बहुत बड़ा लाभ है। आजकल, बिग डेटा टेक्नोलॉजी परिचालन दक्षता में वृद्धि और प्रासंगिक व्यवहार की भविष्यवाणी करके, कई व्यावसायिक आवश्यकताओं और समस्याओं को संबोधित कर रही है। बड़े डेटा में एक करियर और इससे संबंधित तकनीक व्यक्ति के साथ-साथ व्यवसायों के लिए अवसरों के कई द्वार खोल सकती है।
इसके बाद, बिग डेटा तकनीकों को अपनाने के लिए इसका उच्च समय है।
अनुशंसित लेख
यह बिग डेटा टेक्नोलॉजी के लिए एक गाइड रहा है । यहाँ हमने कुछ बिग डेटा तकनीकों जैसे Hive, Apache Kafka, Apache Beam, ELK Stack, आदि पर चर्चा की है। आप अधिक जानने के लिए निम्न लेख को भी देख सकते हैं –
