
Introduction to Spark Cluster
A platform to install Spark is called a cluster. Spark on a distributed model can be run with the help of a cluster. There are x number of workers and a master in a cluster. The one which forms the cluster divide and schedules resources in the host machine. Dividing resources across applications is the main and prime work of cluster managers. Acquires resources by working as an external service on the cluster. Work for the cluster manager is dispatched. The Pluggable cluster manager is supported by Spark. The executor process is handled in Spark by the cluster manager.
Syntax
The syntax for Apache Spark Cluster:
For the K-means data clustering algorithm, this is the implementation API.
org.apache.spark.mllib.clustering
How does Apache Spark Cluster work?
A cluster manager is divided into three types which support the Apache Spark system. They are listed below:
- Standalone Manager of Cluster
- YARN in Hadoop
- Mesos of Apache
Let us discuss each type one after the other.
1. Cluster Manager Standalone in Apache Spark system
This mode is in Spark and simply incorporates a cluster manager. This can run on Linux, Mac, Windows as it makes it easy to set up a cluster on Spark. In a clustered environment, this is often a simple way to run any Spark application.
2. Apache Mesos
By dynamic resource sharing and isolation, Mesos is handling the load of work in a distributed environment. In a large-scale cluster environment, this is helpful for deployment and management. The existing resource of machines and nodes in a cluster can be clubbed together by the Apache Mesos. As this is a node abstraction, this decreases, for different workloads, the overhead of allocating a specific machine. For Hadoop and bigdata clusters, it is a resource management platform. Apache Meso is used by companies like Twitter and Airbnb and is run on Mac and Linux. The reverse of virtualization is Apache Mesos. One physical resource in virtualization divides into many virtual resources. Many physical resources in Mesos are clubbed into a single virtual source.
3. YARN Hadoop
In the year 2012, YARN became the sub-project of Hadoop. It is also called MapReduce 2.0. Into different daemons, the YARN bifurcates the functionality of job scheduling and resource management. Pre-application Application master and Global resource manager (AM and GRM) are the goals to be achieved. An application is either an individual job or DAG of a graph.
4. Kubernetes
For automating deployment, it is an open-source system, for scaling and management of containerized applications.
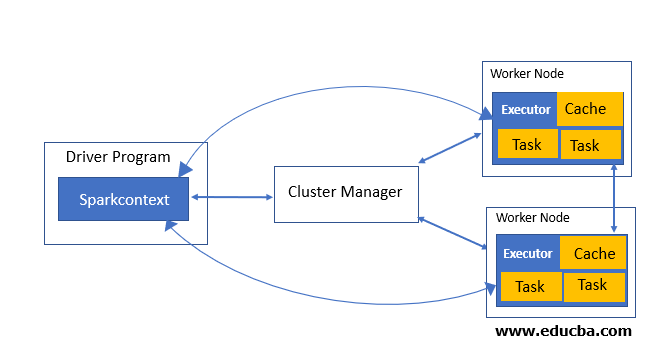
In coordination with the SparkContext object in the main program, (called the driver program), on the cluster, the Spark applications are run as the independent sets of processes. The above-mentioned cluster manager types are specifically used to run on the cluster. And they allocate the resource across all applications. Application is sent to code after being connected and the executors on nodes in the cluster are acquired which are the processes that run computations and also at the same time store the data for user application. After being sent to code they are sent to executors, which are defined by Python and Jar files and are passed to Spark context. And then, finally, all the tasks are sent to executors to run by the SparkContext.
Code:
public abstract class ClusteringColonCancerData {
protected void obtainClusters(){
// Set application name
String appName = "ClusteringExample";
// Initialize Spark configuration & context
SparkConf sparkConf = new SparkConf().setAppName(appName)
.setMaster("local[1]").set("spark.executor.memory", "1g");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
// Read data file from Hadoop file system.
String path = "hdfs://localhost:9000/user/konur/COLRECT.txt";
// Read the data file and return it as RDD of strings
JavaRDD<String> tempData = sc.textFile(path);
JavaRDD<Vector> data = tempData.map(mapFunction);
data.cache();
Enumeration<Integer> keysPoints = clusteredPoints.keys();
while (keysPoints.hasMoreElements()) {
Integer i = keysPoints.nextElement();
System.out.println("\nCluster " + i + " points:");
Hashtable<java.util.Vector<Integer>, Integer> dataPoints =
clusteredPoints
.get(i);
Enumeration<java.util.Vector<Integer>> keyVectors = dataPoints
.keys();
while (keyVectors.hasMoreElements()) {
java.util.Vector<Integer> pnt = keyVectors.nextElement();
System.out.println("[ 'stage group': " + pnt.get(0)
+ ", 'regional nodes positive': " + pnt.get(1) + "]"
+ " repeated " + dataPoints.get(pnt) + " time(s). ]");
}
}
Output:

Conclusion
To sum up, Spark helps to simplify the challenging and computationally intensive task of processing high volumes of real-time or archived data, both structured and unstructured, seamlessly integrating relevant complex capabilities such as machine learning and graph algorithms. Spark brings Big Data processing to the masses.
Recommended articles
This is a guide to Spark Cluster. Here we discuss an introduction to Spark Cluster, syntax and how does it work with different types in detail. You can also go through our other related articles to learn more –
