Introduction to Pandas DataFrame.count()
Pandas Dataframe.count() is characterized as a technique that is utilized totally the quantity of non-NA cells for every section or column. It is additionally appropriate to work with the non-skimming information. Showing results brings about a way that is straightforward which is incredible expertise to have when working with datasets. A typical method to show data is by utilizing a graph with an axis.
Python is an extraordinary language for doing information investigation, fundamentally in light of the incredible environment of information-driven python bundles. Pandas is one of those bundles and makes bringing in and dissecting information a lot simpler.
The pandas DataFrame is a two-dimensional information structure. The information is orchestrated in lines and sections in an even manner. Both the segment and columns tomahawks are named. It can contain sections of various information types, and the size of the DataFrame can be changed (alterable).
Syntax and Parameters
Dataframe.count(level=None, numeric=False, axis=0)Where,
- the level represents the multiple indexing of the axis and if it is hierarchical, then the count() function inside the dataframe collapses and does not return back to the program.
- numeric represents the numeric values that are supported by the program such as integer, floating-point number, and Boolean values. It considers the false value as a default because it has to return to the dataframe whenever the level is specified.
- axis represents the rows and column analysis by the program. This axis parameter helps the count() function to describe which rows and columns to consider when the output is to be implemented by the program using Pandas. It is assigned as 0 to rows and 1 to columns.
How dataframe.count() function works in Pandas?
Now we see various examples on how dataframe.count() works in Pandas. Ordinal information is the place the factors have normal, requested classes, and the separations between the classifications are not known. For instance, if there were two individuals in a room and we said one was short and the other was tall we know there is a distinction, and we know the bearing of the distinction. In any case, we do not have a clue about the estimation of the separation, i.e. what number of inches taller one individual is from the other and that is how we calculate the values in Pandas.
Examples to Implement Pandas DataFrame.count()
Below are the examples mentioned:
Example #1
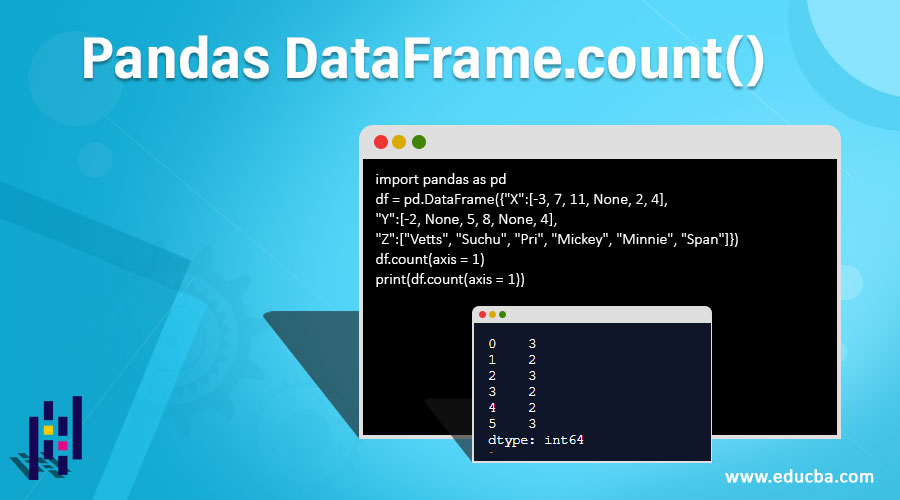
Using dataframe.count() to figure out the row axis values.
Code:
import pandas as pd
df = pd.DataFrame({"X":[-3, 7, 11, None, 2, 4],
"Y":[-2, None, 5, 8, None, 4],
"Z":["Vetts", "Suchu", "Pri", "Mickey", "Minnie", "Span"]})
df.count(axis = 0)
print(df.count(axis = 0))Output:
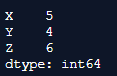
Explanation: In the above program, we first import the panda’s library and assign it as pd. Then, we define the dataframe and organize it as rows and columns however we want. After defining the dataframe, we use the df.count() function to calculate the number of values that are present in the rows and ignore all the null or NaN values. Axis=0 represents the rows and we indicate the program to count only the values in the rows of the dataframe. Hence, this command considers this count() function and gives the dataframe row output as shown in the above snapshot and returns back to the panda’s function.
Example #2
Using dataframe.count() to figure out the values in the columns.
Code:
import pandas as pd
df = pd.DataFrame({"X":[-3, 7, 11, None, 2, 4],
"Y":[-2, None, 5, 8, None, 4],
"Z":["Vetts", "Suchu", "Pri", "Mickey", "Minnie", "Span"]})
df.count(axis = 1)
print(df.count(axis = 1))Output:
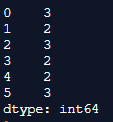
Explanation: In the above program, we write a similar type of code to figure out the column values. Here also first we import the pandas library and then create a dataframe with respective rows and columns. Once the dataframe is defined and created, we assign the count() function to find out the columns. As usual, the axis represents all the row and column parameters. So here we assign an axis to the value 1 so that it displays only the column values and it ignores all the other values which are assigned as none. Thus it has displayed all column values and has ignored row values. Hence, it finally displays the output as shown in the above snapshot.
Conclusion
Finally, I would like to conclude by saying that Pandas dataframe.count() is a function that helps us to analyze the values in the Python dataframe and helps us count all the number of rows and column values and give us a specific output. A count plot graph is a gathered bar outline diagram that permits us to show various bar diagram charts on a similar diagram dependent on the classifications that information is broken into. For this situation, we will utilize the two new ordinal scale esteem segments we just made. This helps the count() function in multiple indexing and returns back to the program without making it collapse.
Recommended Articles
We hope that this EDUCBA information on “Pandas DataFrame.count()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

