Updated April 14, 2023
Introduction to Pandas std()
Pandasstd() function returns the test standard deviation over the mentioned hub. As a matter, of course, the standard deviations are standardized by N-1. It is a measure that is utilized to evaluate the measure of variety or scattering of a lot of information esteems. Python is an incredible language for doing information investigation, fundamentally as a result of the awesome environment of information driven python bundles. Pandas is one of those bundles and makes bringing in and breaking down information a lot simpler.
Syntax and Parameters
Syntax and parameters of pandas std() are:
Dataframe.std(skipna=None,axis=None,ddof=1,level=None,numeric_only=None, **kwargs)Where,
- skipna represents the row and column values. It excludes all the null values which are present in that particular row or column. If all the row and column values are null values, then the final value will be null only.
- axis represents the rows or columns. If axis=0, then row values are taken into consideration, and if axis=1, then column values are taken into consideration.
- ddof represents delta degrees of freedom which in turn means that the divisor will be taken into count during the calculations of a number of elements – degrees of freedom.
- level consists of all the axis which has multiple indices, then the count comes to a specific level, then the series is formed.
- numeric_only represents only numeric values that will be used. The numeric values can be integer values or floating-point values or Boolean values. But these values are not implemented in Series.
- Keyword arguments are the arguments that are returned back to the series and without these values, the program cannot be implemented.
- It returns the standard series or dataframe std().
How does std() Function Work in Pandas?
A DataFrame is a two-dimensional information structure in which the information is adjusted in an even structure for example in lines and segments. Pandas DataFrames make controlling your information simple. You can choose, supplant segments and pushes and even reshape your information. Now we see some examples of how this std() function works in Pandas dataframe.
Example #1 – Column Wise Standard Deviation
Code:
import numpy as np
import pandas as pd
data={'People':['Span','Vetts','Suchu','Deep','Appu','Swaru','Bubby','Sussanna','Anan','Patrick','Vidhi','Niki'],
'Marks1':[12,13,14,15,16,17,18,19,20,21,22,23],
'Marks2':[24,25,25,26,27,28,29,30,31,32,33,34],
'Marks3':[35,36,37,38,39,40,41,42,43,44,45,46]}
df = pd.DataFrame(data)
df.std(axis=0)
print(df.std(axis=0))Output:
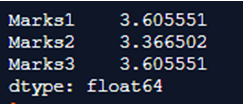
In the above program, we first import the pandas library and the NumPy library and then define the dataframe in the name of data. Then we use the std() function to call this data. The std() function gives the final standard deviation of all the marks of each row and each column and finally produces the output. It considers the axis variables to take into consideration each row or each column and finally return back to the code because the level it wanted to reach and simplify is already present and thus it produces the above output which is shown in the snapshot.
Example 2 – Row Wise Standard Deviation
Code:
import numpy as np
import pandas as pd
data={'People':['Span','Vetts','Suchu','Deep','Appu','Swaru','Bubby','Sussanna','Anan','Patrick','Vidhi','Niki'],
'Marks1':[12,13,14,15,16,17,18,19,20,21,22,23],
'Marks2':[24,25,25,26,27,28,29,30,31,32,33,34],
'Marks3':[35,36,37,38,39,40,41,42,43,44,45,46]}
df = pd.DataFrame(data)
df.std(axis=1)
print(df.std(axis=1))Output:
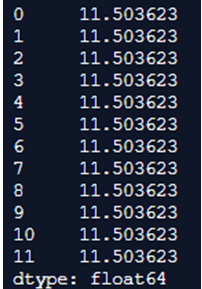
In the above program, we see only row-wise standard deviation. After importing pandas and NumPy libraries, we see that we will define the dataframe. Then we use std() function and we assign axis=1 to find the standard deviation of each row. Hence this processes the code and finally prints out the standard deviation of each row and produces the output.
With Standard Deviation, you can understand whether your information is near the normal or they are spread out over a wide range. For instance, if a business needs to decide whether the pay rates in one of his specialties appear to be reasonable for all workers, or if there is an extraordinary divergence, he can utilize standard deviation. To do that, he can locate the normal of the pay rates in that division and afterward figure the standard deviation. One situation could resemble the accompanying; He finds that the standard deviation is marginally higher than he expected, he looks at the information further and finds that while most representatives fall inside a comparative compensation section, four faithful workers who have been in the division for a long time or progressively, far longer than the others, are making unquestionably increasingly because of their life span with the organization.
Conclusion
Hence I would like to conclude by saying that Pandas is an open source python library that is based on the head of NumPy. It permits you to do a quick examination just as information cleaning and planning. A simple method to consider Pandas is by essentially taking a gander at it as Python’s rendition of Microsoft’s Excel. One amazing fact about Pandas is the way that it can function admirably with information from a wide assortment of sources, for example, Excel sheet, csv record, sql document or even a website page. The standard deviation function std() is a great way to process mathematical operations and we can calculate the row and column axis by using this function.
Recommended Articles
We hope that this EDUCBA information on “Pandas std()” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

