Updated March 31, 2023

Introduction of Pandas MultiIndex
Pandas Multiindex work makes a Dataframe with the degrees of the Multiindex as segments. Python is an incredible language for information examination because of the phenomenal biological system of information-driven python bundles. Pandas is one of those bundles and simplifies bringing and investigating information. As should be obvious in the yield, the capacity has developed the Dataframe utilizing the MultiIndex. Notice the record of the dataframe is developed utilizing the degrees of the MultiIndex.
Syntax and Parameters:
Multiindex.to_frame(index=True)Where,
- The index represents setting the file of the returned DataFrame as the first MultiIndex.
- It returns data that was present in the multi-index dataframe earlier.
How MultiIndex Work in Pandas?
Now we see various examples of How multiIndexing works in Pandas.
Example #1
Code:
import pandas as pd
mulx = pd.MultiIndex.from_tuples([(15, 'Fifteen'), (19, 'Nineteen'),
(19, 'Fifteen'), (19, 'Nineteen')], names =['Num', 'Char'])
print(mulx)Output:
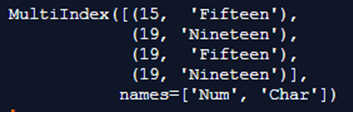
In the above program, we first import the panda’s library as pd, then use the multiindex function to create a dataframe of multiple indices, and then print the defined multiindex.
Example #2
Code:
import pandas as pd
mulx = pd.MultiIndex.from_tuples([(15, 'Fifteen'), (19, 'Nineteen'),
(19, 'Fifteen'), (19, 'Nineteen')], names =['Num', 'Char'])
mulx.to_frame(index = True)
print(mulx.to_frame(index = True) )Output:
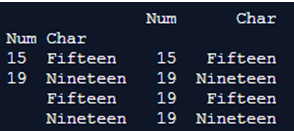
The above program is similar to the previous program in that we first import pandas as pd and then create a dataframe inside the multiindex function. Next, we add multiple indices to the dataframe. Then we put the index=true condition to return the values to the dataframe.
Example #3
Code:
import pandas as pd
mulx = pd.MultiIndex.from_tuples([(15, 'Fifteen'), (19, 'Nineteen'),
(19, 'Fifteen'), (19, 'Nineteen')], names =['Num', 'Char'])
mulx.to_frame(index = False)
print(mulx.to_frame(index = False) )Output:
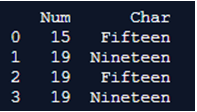
In the above program, we declare index=false so that the indices defined inside the multiindex function will be declared false. Hence, when we print the multiindex, it considers the false values and prints the output as shown in the above snapshot.
In case you mark the lines of your DataFrame, it is acceptable to name them importantly, assuming there is any chance of this happening. A decent method to consider this test requires a unique and significant identifier for each column. Look at the sections and check whether any match these rules. Notice that the data segment contains one-of-a-kind data, so it bodes well to name each line by the data segment. That is, you can make the data segment the record of the DataFrame utilizing the multiindex() strategy if inplace=True implies you are changing the DataFrame df inplace.
This can be marginally confounding because this says that df.columns are of type Index. This does not imply that the sections are the record of the DataFrame. The list of df is constantly given by the df.index. These ordering activities help take care of information as dataframes. These pandas’ capacities are helpful when we need to oversee huge amounts of information by changing it over it into dataframes. We would investigate these capacities’ sentence structure and instances to comprehend their use.
It is helpful to go past this and store higher-dimensional information, that is, information recorded by more than a couple of keys. While Pandas gives Panel and Panel4D objects that locally handle three-dimensional and four-dimensional information, an unmistakably increasingly common example is to utilize various leveled ordering (otherwise called multi-ordering) to join different file levels inside a solo record. Like this, higher-dimensional information can be minimalistic spoken to inside the natural one-dimensional Series and two-dimensional DataFrame objects.
Formation of MultiIndex objects, contemplations when ordering, cutting and registering measurements across duplicate filed information, and helpful schedules for changing over among straightforward and progressively recorded portrayals of your information which helps in the entire process of multiindexing functions and parameters.
Conclusion
Hence, I would like to conclude by stating that this was accomplished using collection by a solitary segment. I referenced, in passing, that you might need to amass by a few sections, in which case the subsequent pandas DataFrame winds up with a multi-list or progressive file. This post has acquainted you with various leveled lists (or multi-lists). You have perceived how they emerge as an expected outcome of needing a DataFrame list to mark the columns of your DataFrame particularly and genuinely. You have also perceived how they emerge when you assemble your information by numerous segments, summoning the split-apply-consolidation guideline. I trust that you mess around with progressive lists in your work.
Recommended Articles
We hope that this EDUCBA information on “Pandas MultiIndex” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

