Updated April 17, 2023
Introduction to PySpark row
PYSPARK ROW is a class that represents the Data Frame as a record. We can create row objects in PySpark by certain parameters in PySpark. The row class extends the tuple, so the variable arguments are open while creating the row class. We can create a row object and can retrieve the data from the Row.
The row can be understood as an ordered collection of fields that can be accessed by index or by name. They can have an optional schema. The Row object creates an instance. We can merge Row instances into other row objects. A row can be used to create the objects of ROWS by using the arguments.
The syntax for Pyspark Row
The syntax for the ROW function is:-
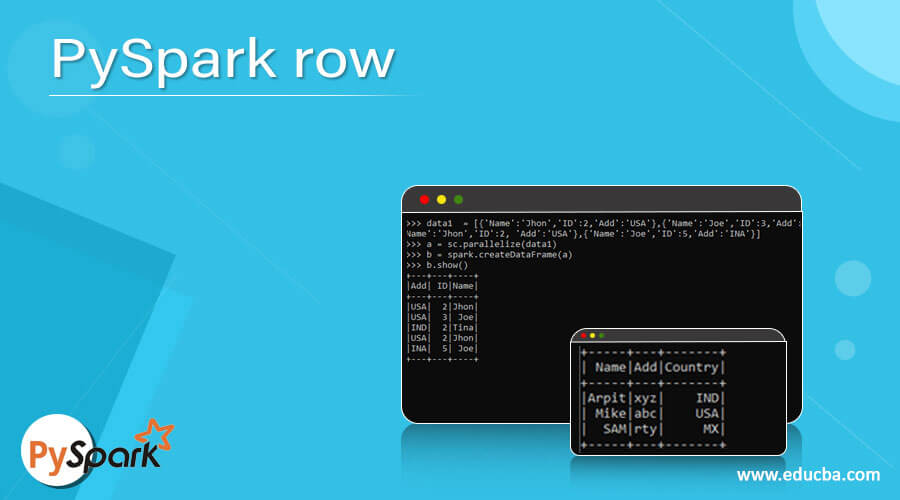
from pyspark.sql import Row
r=Row("Anand",30)The import function to be used from the PYSPARK SQL.
The Row Object to be made on with the parameters used.
Screenshot:
Working of Row in Pyspark
Let us see somehow the ROW operation works in PySpark:-
A Row class extends a Tuple, so it takes up a variable number of arguments as Tuple exhibits the property of. A Row Object is created from which we can derive the Row Data; with the Row Object, we have a collection of fields that can be accessed by name or index.
The Row() method creates a Row Object and stores the value inside that. They can also have an optional Schema. Once the ROW is created, the methods are used that derive the value based on the Index. The GetAs method is used to derive the Row with the index once the object is created.
It has a row Encoder that takes care of assigning the schema with the Row elements when a Data Frame is created from the Row Object.
Factory Methods are provided that are used to create a ROW object, such as apply creates it from the collection of elements, from SEQ, From a sequence of elements, etc. In this way, a ROW Object is created, and data is stored inside in PySpark.
Let’s check the creation and usage with some coding examples.
Example
Let us see some Example of how the PYSPARK ROW operation works:-
Let’s start by creating simple data in PySpark.
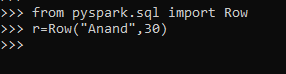
data1 = [{'Name':'Jhon','ID':2,'Add':'USA'},{'Name':'Joe','ID':3,'Add':'USA'},{'Name':'Tina','ID':2,'Add':'IND'},{'Name':'Jhon','ID':2, 'Add':'USA'},{'Name':'Joe','ID':5,'Add':'INA'}]A sample data is created with Name, ID and ADD as the field.
a = sc.parallelize(data1)RDD is created using sc.parallelize.
b = spark.createDataFrame(a)
b.show()Created Data Frame using Spark.createDataFrame.
Screenshot:
Let’s try that with the ROW Object now:
Let’s create a ROW Object. This can be done by using the ROW Method that takes up the parameter, and the ROW Object is created from that.
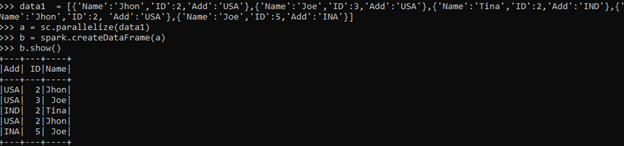
from pyspark.sql import Row
row=Row("Anand",30)
print(row[0] +","+str(row[1]))The import ROW from PySpark.SQL is used to import the ROW method, which takes up the argument for creating Row Object.
This is a simple method of creating a ROW Object.
Screenshot:
The same can also be done by using the named argument, i.e.:-
r = Row(name="Arpit",age = 23)
print(r.name)This can be used to calling it by the named argument type.
Screenshot:

The other method for creating a ROW Object can be using the custom class method. We just need to define that custom class, and the same can be used to invoking the row object.
Code:
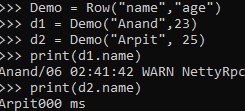
Demo = Row("name","age")
d1 = Demo("Anand",23)
d2 = Demo("Arpit", 25)
print(d1.name)
print(d2.name)Screenshot:
We can also make a data frame, RDD, out of Row Object, which can be used further for PySpark operation.
Lets us try making the data frame out of Row Object.
We will try doing it by creating the class object.
Code:
from pyspark.sql import Row
Demo_Class = Row("Name","Add","Country")
df_Data = [Demo_Class("Arpit","xyz","IND"),Demo_Class("Mike","abc","USA") , Demo_Class("SAM","rty","MX")]
df = spark.createDataFrame(df_Data)
df.show()Screenshot:
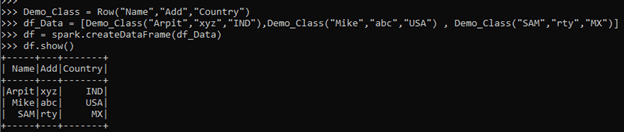
This creates a Data Frame from the ROW Object.
The column name is taken from the ROW Object
df.printSchema()This the schema defined for the Data Frame.
We can also make RDD from this Data Frame and use the RDD operations over there or simply make the RDD from the Row Objects.
Code:
a = df.rdd
a.collect()
[Row(Name='Arpit', Add='xyz', Country='IND'), Row(Name='Mike', Add='abc', Country='USA'), Row(Name='SAM', Add='rty', Country='MX')]This will make an RDD out of Data Frame, and we can do the operation over there.
Screenshot:

The same can be done by using the spark. sparkcontext.Parallelize method using the ROW Object within it.
rdd1 = spark.sparkContext.parallelize(df_Data)
rdd1.collect()
[Row(Name='Arpit', Add='xyz', Country='IND'), Row(Name='Mike', Add='abc', Country='USA'), Row(Name='SAM', Add='rty', Country='MX')]Here we can analyze that the results are the same for RDD.
Screenshot:
![]()
These are some of the Examples of ROW Function in PySpark.
Note:
- PySpark ROW extends Tuple allowing the variable number of arguments.
- ROW uses the Row() method to create Row Object.
- ROW can have an optional schema.
- ROW objects can be converted in RDD, Data Frame, Data Set that can be further used for PySpark Data operation.
- ROW can be created by many methods, as discussed above.
Conclusion
From the above article, we saw the use of Row Operation in PySpark. We tried to understand how the ROW method works in PySpark and what is used at the programming level from various examples and classification.
We also saw the internal working and the advantages of having a Row in PySpark Data Frame and its usage in various programming purpose. Also, the syntax and examples helped us to understand much precisely the function.
Recommended Articles
This is a guide to PySpark row. Here we discuss the use of Row Operation in PySpark with various examples and classification. You may also have a look at the following articles to learn more –

