Introduction to PL/SQL Functions
Oracle Corporation’s procedural extension for SQL serves PL/SQL, which stands for Procedural Language/Structured Query Language, and the Oracle relational database. PL/SQL functions are named PL/SQL blocks capable of accepting parameters and returning values. Client applications, SQL queries, or other PL/SQL blocks can invoke them, encapsulating specific tasks or calculations. You can also call a function from anywhere within its scope in the program, including within Boolean expressions and assignment statements, to assign the return value to a variable.
Table of Contents:
Syntax:
CREATE [OR REPLACE] FUNCTION function_name
[ (parameter1 datatype [, parameter2 datatype, ...]) ]
RETURN return_datatype
IS
-- Declaration section (optional)
BEGIN
-- Execution section
RETURN return_value;
END function_name;
/Components:
- function_name: Name of the PL/SQL function.
- parameter1, parameter2, etc.: Parameters accepted by the function.
- Datatype: Data type of each parameter.
- return_datatype: Data type of the value returned by the function.
- return_value: Value returned by the function.
Example:
For example, to calculate the area of a rectangle:
CREATE OR REPLACE FUNCTION calculate_area(length NUMBER, width NUMBER)
RETURN NUMBER
IS
area NUMBER;
BEGIN
area := length * width;
RETURN area;
END calculate_area;
/
DECLARE
length_value NUMBER := 5;
width_value NUMBER := 10;
area_result NUMBER;
BEGIN
area_result := calculate_area(length_value, width_value);
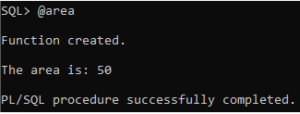
DBMS_OUTPUT.PUT_LINE('The area is: ' || area_result);
END;
/Output:
Explanation:
- The function `calculate_area` computes the area of a rectangle with a given length and width.
- An anonymous block initializes length and width values and calls the function.
- The function calculates the area by multiplying length and width and returns the result.
- The anonymous block assigns the returned area value to a variable and prints it.
- This PL/SQL code showcases the utilization of functions for calculations within a database environment.
Benefits:
- Modularity: Functions enable modular programming by encapsulating specific logic or calculations.
- Code Reusability: Functions are reusable across various SQL queries and PL/SQL blocks.
- Performance: Well-designed functions can enhance query performance by minimizing redundant code execution.
Return Types in PL/SQL Function
PL/SQL functions’ return types determine the data type of the value returned by the function. PL/SQL supports various scalar and composite data types as return types, providing flexibility in function design to meet diverse requirements.
1. Scalar Return Types
Scalar return types represent single values and include common data types such as:
- NUMBER: Numeric data type for integers or floating-point numbers.
- VARCHAR2: Variable-length character data type.
- DATE: Date and time data type.
- BOOLEAN: Boolean data type with values TRUE, FALSE, or NULL.
Example:
SET SERVEROUTPUT ON;
CREATE OR REPLACE FUNCTION convert_to_uppercase(input_string VARCHAR2)
RETURN VARCHAR2
IS
result_string VARCHAR2(100);
BEGIN
result_string := UPPER(input_string);
RETURN result_string;
END;
/
CREATE OR REPLACE PROCEDURE print_uppercase(input_string VARCHAR2)
IS
output_string VARCHAR2(100);
BEGIN
output_string := convert_to_uppercase(input_string);
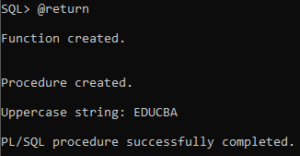
DBMS_OUTPUT.PUT_LINE('Uppercase string: ' || output_string);
END;
/
DECLARE
input_str VARCHAR2(100) := 'educba';
BEGIN
print_uppercase(input_str);
END;
/Output:
Explanation:
- The PL/SQL code comprises a function `convert_to_uppercase` converting input string to uppercase.
- A procedure `print_uppercase` uses the function to print the uppercase version of an input string.
- An anonymous block initializes a string variable `input_str` and calls `print_uppercase`.
- The program demonstrates string manipulation in Oracle using functions and procedures.
2. Composite Return Types
Composite return types allow functions to return complex data structures, such as:
- Record: A composite data type that can hold multiple values of different data types within a single structure.
- Table: A collection data type representing a set of rows and columns, similar to a database table.
Example:
-- Create a custom record type
CREATE OR REPLACE TYPE employee_record AS OBJECT (
employee_id NUMBER,
employee_name VARCHAR2(100),
employee_salary NUMBER
);
/
-- Create a function to return an employee record
CREATE OR REPLACE FUNCTION get_employee_details(employee_id NUMBER)
RETURN employee_record
IS
emp_rec employee_record;
BEGIN
-- Simulating data retrieval
emp_rec := employee_record(employee_id, 'Franklin Clintonn', 70000);
RETURN emp_rec;
END;
/
-- Create a procedure to print employee details
CREATE OR REPLACE PROCEDURE print_employee_details(employee_id NUMBER)
IS
emp_info employee_record;
BEGIN
emp_info := get_employee_details(employee_id);
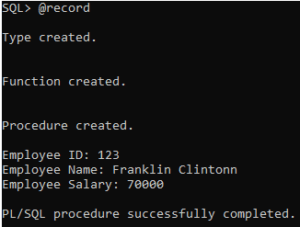
DBMS_OUTPUT.PUT_LINE('Employee ID: ' || emp_info.employee_id);
DBMS_OUTPUT.PUT_LINE('Employee Name: ' || emp_info.employee_name);
DBMS_OUTPUT.PUT_LINE('Employee Salary: ' || emp_info.employee_salary);
-- Print other details as needed
END;
/
-- Enable output
SET SERVEROUTPUT ON;
-- Call the procedure
BEGIN
print_employee_details(123);
END;
/Output:
You can directly invoke functions with scalar return types within SQL queries or PL/SQL blocks. Similarly, functions returning composite types can be utilized, with their returned values accessed akin to table columns.
Explanation:
- Custom Record Type: Defined `employee_record` with attributes.
- Function `get_employee_details`: Returns employee details with simulated data.
- Procedure `print_employee_details`: Prints employee details using `DBMS_OUTPUT.PUT_LINE`.
- Enabled output: `SET SERVEROUTPUT ON;` to display output.
- Procedure Call: Invoked `print_employee_details` with an employee ID within an anonymous block.
Nested Functions in PL/SQL
Nested functions in PL/SQL involve defining and calling a function within the body of another function. This function facilitates code modularization and can be especially beneficial for encapsulating logic closely related to the main function but not required to be accessed externally.
Syntax:
CREATE OR REPLACE FUNCTION outer_function(parameters)
RETURN return_datatype
IS
-- Declaration section
...
BEGIN
-- Outer function logic
-- Nested function definition
FUNCTION nested_function(parameters)
RETURN return_datatype
IS
-- Declaration section
...
BEGIN
-- Nested function logic
...
END nested_function;
-- Outer function logic continued
...
END outer_function;
/Explanation:
- Outer Function: Defined a function `outer_function` with parameters and a specified return datatype using `CREATE OR REPLACE FUNCTION`.
- Nested Function: Declared a nested function `nested_function` within `outer_function`, with parameters and the same return datatype.
- Declaration Section: Both functions include a declaration section where local variables and nested function declarations are defined.
- Logic Sections: Each function implements the functionality in its logic section.
- End: Concluded the functions using `END` and `END nested_function;` for the outer and nested functions, respectively.
Example:
SET SERVEROUTPUT ON;
CREATE OR REPLACE FUNCTION factorial(n NUMBER) RETURN NUMBER IS
-- Nested function to calculate the factorial recursively
FUNCTION recursive_factorial(num NUMBER) RETURN NUMBER IS
BEGIN
IF num <= 1 THEN
RETURN 1;
ELSE
RETURN num * recursive_factorial(num - 1);
END IF;
END recursive_factorial;
-- Main body of outer function
BEGIN
-- Call the nested function to calculate factorial
DBMS_OUTPUT.PUT_LINE('Factorial of ' || n || ' is: ' || recursive_factorial(n));
RETURN recursive_factorial(n);
END factorial;
/
-- Example usage:
DECLARE
result NUMBER;
BEGIN
result := factorial(5); -- Calculate factorial of 5
END;
/Output:
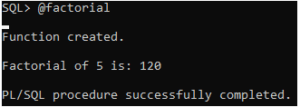
Nested functions enable improved code organization by encapsulating related logic within the context of the outer function.
Explanation:
- Function Definition: Created a function named `factorial` to calculate the factorial of a given number `n` using recursion.
- Nested Function: Declared a nested function `recursive_factorial` within `factorial` to compute the factorial recursively.
- Recursion Termination: The `recursive_factorial` function terminates when the input `num` is less than or equal to 1, returning 1.
- Recursive Calculation: If `num` is greater than 1, the function recursively multiplies `num` with the result of `recursive_factorial(num – 1)`.
- Output: Inside `factorial`, the input `n` factorial is calculated by calling `recursive_factorial(n)` and printed using `DBMS_OUTPUT.PUT_LINE`.
- Return Value: The `factorial` function returns the calculated factorial.
- Example Usage: Using the `factorial` function, calculate the factorial of 5 within an anonymous block and assign the result to a variable `result`.
Function Overloading in PL/SQL
In PL/SQL, function overloading permits the definition of multiple functions with identical names but distinct parameter lists within the same scope. Each function variant is identified by its unique parameter signature, enabling more flexible and intuitive usage of functions with diverse input requirements.
Syntax:
CREATE OR REPLACE FUNCTION function_name(parameter1 datatype1, parameter2 datatype2, ...)
RETURN return_datatype
IS
-- Function logic
BEGIN
-- Implementation
END function_name;
/Explanation:
- Function Definition: Created using CREATE OR REPLACE FUNCTION, specifying the function name, parameters with their datatypes, and the return datatype.
- Function Logic: The logic section within the BEGIN and END keywords defines the function’s implementation.
- Implementation: This is where you write the logic or calculations the function will perform using the provided parameters.
- Return Statement: Typically, the function ends with a RETURN statement to return a value of the specified return datatype.
Example:
-- Function to calculate the area of a rectangle
CREATE OR REPLACE FUNCTION calculate_rectangle_area(length NUMBER, width NUMBER)
RETURN NUMBER
IS
area NUMBER;
BEGIN
area := length * width;
RETURN area;
END calculate_rectangle_area;
/
-- Function to calculate the area of a circle
CREATE OR REPLACE FUNCTION calculate_circle_area(radius NUMBER)
RETURN NUMBER
IS
area NUMBER;
BEGIN
area := 3.14 * radius * radius;
RETURN area;
END calculate_circle_area;
/
-- PL/SQL block to demonstrate the usage and display output
DECLARE
rectangle_length NUMBER := 5;
rectangle_width NUMBER := 4;
circle_radius NUMBER := 3;
BEGIN
DBMS_OUTPUT.PUT_LINE('Area of rectangle: ' || calculate_rectangle_area(rectangle_length, rectangle_width));
DBMS_OUTPUT.PUT_LINE('Area of circle: ' || calculate_circle_area(circle_radius));
END;
/Output:
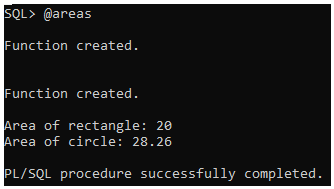
Explanation:
- calculate_rectangle_area: This function calculates the area of a rectangle using the formula length * width. It takes two parameters: length and width, both of datatype NUMBER. The calculated area is stored in a variable area and then returned.
- calculate_circle_area: This function calculates the area of a circle using the formula π * radius^2, where π is 3.14. It takes one parameter: radius of datatype NUMBER. The calculated area is stored in a variable area and then returned.
- Anonymous Block: This block initializes variables rectangle_length, rectangle_width, and circle_radius with numerical values. It then calls the two functions to calculate the areas of a rectangle and a circle, respectively. The results print DBMS_OUTPUT.PUT_LINE.
Benefits:
- Function overloading allows for creating functions with the same name but tailored to handle different scenarios, leading to a more intuitive interface for developers.
- Overloaded functions, sharing the same name but featuring distinct parameter lists, can improve code readability, particularly when handling related tasks.
Function Dependencies
Function dependencies in PL/SQL involve the connections between PL/SQL functions and other database objects like tables, views, types, and additional functions. Grasping these dependencies is critical for efficient database development, maintenance, and performance optimization.
Types of Dependencies:
- Data Dependencies: Functions might rely on data stored in tables or views, necessitating access to particular columns or records for their operation.
- Object Dependencies: Functions can rely on other database objects such as tables, views, types, and packages. The function’s data manipulation or computation logic may reference these objects.
- Cross Dependencies: Functions can exhibit cross-dependencies with other functions or procedures within the same schema or across schemas.
Managing Dependencies:
- Dependency Tracking: Database management tools commonly offer features to track dependencies between database objects. These tools can analyze code and identify dependencies, aiding in managing changes and ensuring data integrity.
- Dependency Injection: In some instances, dependencies can be dynamically injected into functions, offering increased flexibility and adaptability in the application architecture.
- Dependency Management Tools: Employing dependency management tools or version control systems facilitates tracking changes to database objects and their dependencies. These tools aid in maintaining consistency and fostering collaboration among developers.
Real-World Applications and Example
Case Study: Implementing Business Logic with Functions:
PL/SQL functions are frequently employed to encapsulate business logic within database systems. For instance, PL/SQL functions might be used in a banking application to calculate interest rates, verify account balances, or process transactions. Similarly, an e-commerce platform could utilize PL/SQL functions for pricing calculations, inventory management, and order processing tasks.
Example:
-- Creating the function
CREATE OR REPLACE FUNCTION calculateInterest(
loan_amount NUMBER,
interest_rate NUMBER,
loan_duration NUMBER
) RETURN NUMBER
IS
interest_amount NUMBER;
BEGIN
interest_amount := (loan_amount * interest_rate * loan_duration) / 100;
RETURN interest_amount;
END calculateInterest;
/
-- Example of how to use the function
DECLARE
loan_amount_input NUMBER := 10000;
interest_rate_input NUMBER := 5;
loan_duration_input NUMBER := 2;
interest_output NUMBER;
BEGIN
interest_output := calculateInterest(loan_amount_input, interest_rate_input, loan_duration_input);
DBMS_OUTPUT.PUT_LINE('Interest Amount: ' || interest_output);
END;
/Output:
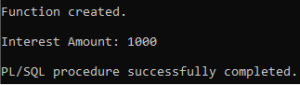
Common Use Cases for PL/SQL Functions
- Data Transformation: PL/SQL functions commonly serve to transform data, including tasks such as converting data types, formatting strings, or applying custom business rules.
- Validation and Data Integrity: Functions can enforce data integrity constraints and perform validation checks to ensure data quality and consistency.
- Calculation and Aggregation: PL/SQL functions are valuable for performing complex calculations and aggregations, such as computing summary statistics or generating reports.
- Security and Access Control: Functions like data encryption, authorization checks, and user authentication can be used to put security measures in place.
- Custom Business Logic: PL/SQL functions enable developers to implement custom business logic specific to their application requirements, providing flexibility and extensibility.
Performance Tuning for PL/SQL Functions
Improving the performance of PL/SQL functions entails optimizing their execution to enhance database query performance, minimize resource consumption, and boost overall system efficiency. By employing diverse techniques and adhering to best practices, developers can ensure that PL/SQL functions execute efficiently, meeting performance requirements and scalability needs.
Techniques:
- Query optimization: Ensure efficient SQL queries within PL/SQL functions by optimizing index usage, minimizing joins, and effectively utilizing WHERE clauses.
- Reduce Data Processing: Optimize data processing within PL/SQL functions by minimizing manipulations, utilizing built-in functions, and employing batch processing where applicable.
- Proper Exception Handling: Implement efficient exception handling mechanisms in PL/SQL functions to gracefully manage errors without sacrificing performance. Minimize the use of costly error-handling constructs to avoid introducing unnecessary overhead.
- Indexing Strategy: Analyze query execution plans and consider creating or modifying indexes judiciously to optimize query performance within PL/SQL functions, ensuring efficient utilization and avoiding unnecessary overhead.
- Code Review & Refactoring: Regularly review the PL/SQL function code and refactor it to optimize performance. Identify and remove redundant code, optimize loops, and streamline logic to enhance efficiency.
Advanced Concepts in PL/SQL
1. Exception Handling in Functions
Exception handling in PL/SQL functions involves managing errors that may occur during the function’s execution. Exception handling can include catching specific exceptions, such as division by zero or invalid input, and handling them gracefully within the function. Exception handling allows for more robust and reliable functions by providing a way to handle unexpected situations.
Example:
SELECT * FROM electronics_products WHERE price < ANY (SELECT price FROM electronics_products WHERE product_name IN ('Smartphone', 'Tablet'));
SET SERVEROUTPUT ON;
DECLARE
numerator NUMBER := &numerator_input; -- Input numerator value
denominator NUMBER := &denominator_input; -- Input denominator value
result NUMBER;
BEGIN
-- Division operation with exception handling
BEGIN
IF denominator = 0 THEN
RAISE_APPLICATION_ERROR(-20001, 'Denominator cannot be zero');
ELSE
result := numerator / denominator;
DBMS_OUTPUT.PUT_LINE('Result: ' || result);
END IF;
EXCEPTION
WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('An error occurred: ' || SQLERRM);
END;
END;
/Output:
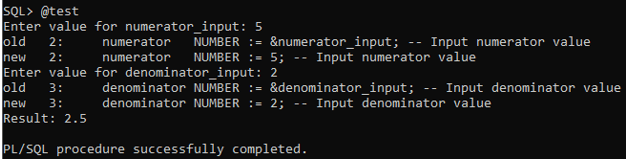
Explanation:
- The program declares variables numerator, denominator, and result.
- It begins the executable section, within an inner block:
- It checks if the denominator is zero.
- If the denominator is zero, it raises an application error.
- It handles exceptions printing error messages, if any.
- The program ends.
2. Pipelined Functions
Pipelined functions in PL/SQL offer a method to process and return data row-by-row, as opposed to returning all results at once. They are valuable for enhancing performance and reducing memory usage when handling large result sets. Additionally, pipelined functions can be utilized in SQL queries as if they were regular table functions, providing convenience for developers.
Example:
-- Enable server output for displaying PL/SQL output
SET SERVEROUTPUT ON;
-- Create a type for the result set
CREATE OR REPLACE TYPE number_list AS TABLE OF NUMBER;
/
-- Create a function that returns a nested table of numbers using PIPELINED
CREATE OR REPLACE FUNCTION generate_numbers(start_num IN NUMBER, end_num IN NUMBER) RETURN number_list PIPELINED IS
BEGIN
FOR i IN start_num..end_num LOOP
-- Generate numbers from start_num to end_num and pipe each number
PIPE ROW (i);
END LOOP;
-- Return the result set
RETURN;
END;
/
-- Test the pipelined function and print the output
DECLARE
-- Declare a variable to hold the result set
number_result number_list := number_list(); -- Initialize an empty nested table
-- Declare a counter
counter NUMBER := 0;
BEGIN
-- Call the pipelined function and store the result set in number_result
FOR num IN (SELECT * FROM TABLE(generate_numbers(1, 10))) LOOP
counter := counter + 1;
number_result.extend;
number_result(counter) := num.COLUMN_VALUE;
END LOOP;
-- Iterate over the result set and print each number
FOR i IN 1..number_result.COUNT LOOP
DBMS_OUTPUT.PUT_LINE('Number: ' || number_result(i));
END LOOP;
END;
/Output:
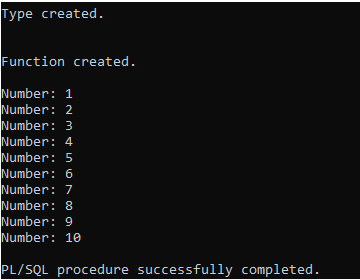
Explanation:
- Nested Table Type: Defined a type number_list to hold numbers.
- Pipelined Function: Created a function generate_numbers to generate a sequence of numbers using a FOR loop and piped each number into the result set.
- Testing: Declared a variable number_result to store the result set, fetched numbers from the pipelined function, and printed each number using DBMS_OUTPUT.PUT_LINE.
3. Inlined Functions
Inline functions also known as deterministic functions, never have any side effects and always yield the same result for the same input. They are commonly employed in SQL queries to execute calculations or transformations on data. Inline functions can enhance query performance by enabling optimizers to inline their code directly into the query execution plan.
Example:
CREATE OR REPLACE FUNCTION calculate_discount (price NUMBER) RETURN NUMBER
DETERMINISTIC
IS
discount_percentage NUMBER := 0.1;
BEGIN
RETURN price * discount_percentage;
END calculate_discount;
/
SELECT calculate_discount(100) AS discount FROM dual;Output:
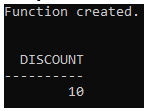
Explanation:
- Function Definition: Defines `calculate_discount` function to compute a 10% discount on the input price.
- Function Usage: Calls `calculate_discount(100)` to calculate the discount for a price of 100.
- Output: Displays the computed discount, which is 10.
Best Practices and Optimization Techniques
1. Optimizing Function Performance
- Utilize proper indexing on tables accessed within functions to optimize data retrieval.
- Minimize context switches between SQL and PL/SQL by employing bulk processing techniques such as BULK COLLECT and FORALL.
- Avoid unnecessary computations and loops, particularly within tight loops or recursive operations.
- Consider caching frequently accessed data in PL/SQL collections to reduce database round trips and improve overall performance.
2. Error Handling Strategies
- Use specific exception handling to catch and gracefully handle expected errors. It involves anticipating potential errors and using appropriate exception handlers to manage them without disrupting program execution.
- Log errors using built-in logging facilities such as DBMS_OUTPUT or autonomous transactions. It allows for recording error messages or relevant information for troubleshooting purposes.
- Implement a consistent error-handling framework throughout your PL/SQL codebase to ensure uniformity and maintainability. It involves defining standard exception-handling practices and adhering to them across all PL/SQL code modules.
3. Naming Conventions and Coding Standards
- Follow a consistent naming convention for functions, variables, and parameters. This involves using descriptive names that accurately convey the purpose of each element and adhere to established naming conventions.
- Use meaningful names for functions and variables to enhance understanding and maintainability. Avoid cryptic or ambiguous names that confuse other developers or yourself when revisiting the code.
- With respect to coding standards and guidelines established by your organization or industry. Consistency in coding style and structure promotes better collaboration among team members.
4. Testing and Debugging Functions
- Write comprehensive test cases to cover various scenarios and edge cases. This involves designing tests encompassing a wide range of inputs and conditions to ensure the functionality and reliability of the code.
- Utilize debugging tools like DBMS_OUTPUT, DBMS_DEBUG, or third-party Integrated Development Environments (IDEs). Debugging tools aid in identifying and resolving issues during the development and testing phases.
- Perform thorough code reviews and peer testing to identify issues early in development. Collaborative code reviews involve multiple developers examining the code for correctness, adherence to coding standards, and potential improvements, enhancing code quality and minimizing errors.
Conclusion
PL/SQL functions are Oracle’s extension blocks that accept parameters and return values. They serve various purposes, invoked by client applications, SQL queries, or other PL/SQL blocks, encapsulating specific tasks. Syntax entails defining the function name, parameters, return data type, and execution block. Benefits include modularity, code reusability, and performance enhancement. Return types comprise scalar (e.g., NUMBER, VARCHAR2) and composite types (e.g., record, table). Nested functions encapsulate related logic, while function overloading allows multiple functions with the same name but different parameter lists. Function dependencies, including data, object, and cross dependencies, are crucial for database development.
FAQs
1. How do I call a PL/SQL function from SQL queries or other PL/SQL blocks?
Answer: In SQL queries, calling a PL/SQL function involves using the function name followed by the required parameters. You can call a function within PL/SQL blocks like any other procedure or function.
2. Can PL/SQL functions have side effects?
Answer: Of course. PL/SQL functions may lead to side effects if they modify data or interact with the database in a manner that alters the system’s state. Taking precautions when designing functions is vital to prevent unintended side effects.
3. What are deterministic and non-deterministic functions in PL/SQL?
Answer: Deterministic functions consistently provide the same result for identical input parameters and remain independent of external factors. On the other hand, non-deterministic functions may yield different outcomes for the same input parameters, and external factors such as database state or system time can influence it.
4. Can PL/SQL functions be used in SQL queries within the WHERE clause?
Answer: Absolutely, PL/SQL functions can be integrated into SQL queries, particularly within the WHERE clause, to filter data based on the function’s return value. However, it’s essential to carefully assess the performance implications of incorporating functions in such contexts, as they might affect the overall query performance.
5. How do I handle errors and exceptions in PL/SQL functions?
Answer: You can manage error handling in PL/SQL functions through techniques such as the EXCEPTION block, RAISE_APPLICATION_ERROR procedure, or custom error handling logic. Implementing effective error handling ensures graceful handling of unexpected situations, thereby enhancing the overall robustness of the function.
Recommended Articles
We hope that this EDUCBA information on “PL/SQL Functions” was beneficial to you. For more information, you can view EDUCBA’s recommended articles.
