Updated March 6, 2023

Introduction to Hive JDBC Driver
The Hive is a very vital service in the Hadoop ecosystem. The hive JDBC driver will provide the functionality to connect the external or internal (superset service) BI tools. It will help to analyse data, query on the data, and visualize the data. We can trigger the queries on the distributed data, i.e., the data which is store on the HDFS level. The JDBC driver will help to connect with the hive server2. There are two types of the driver available that is supported by the hive. The first type is the JDBC driver, and the second type is the ODBC driver. As per the project requirement or the business need, we need to choose any one of the connection types. But by default, we are using the JDBC connection in the Hadoop stack.
How does JDBC driver work in Hive?
As we have discussed, the hive will support the SQL functionality. We can trigger the SQL query on top of the distributed data. In the Hadoop stack, we are using the HDFS to store the distributed data. There are different ways that we can use the hive service. The different ways like HDP environment, CDH environment, and standalone hive environment, etc. To work with the Hive JDBC driver, first, we need to understand the hive architecture. In hive service, there are different components are available like hive server2, hive metastore, hive metadata, hive thrift server, hive gateway, or client.
Hive JDBC Driver: The JDBC driver is a very important part of the hive service. It will help to connect the hive client with the hive server.
Hive server2: Hive server 2 plays a very important role in the hive service. It will manage the overall hive service. It will keep complete track of all the hive components.
Hive metastore service: The hive metastore service will manage the metastore connection. It will manage it with the help of the hive database, which is available in the MySQL server, MariaDB, Postgres DB, etc. In this database, the hive is having the actual metadata.
Hive metadata: The hive metadata is the actual physical database that is associated with the hive service. To create the hive metadata, we need to select any of the database servers like MySQL server, MariaDB, Postgres DB, etc. It is having detailed information about the hive service.
Hive thrift server: In the hive service, the hive thrift server is an optional service. As per the requirement or the business need, we can install it on the Hadoop stack. The hive thrift server will help to submit the hive queries from the external environment. If any external software or the tool wants to trigger the hive jobs, then it with the help of the hive thrift server. It will easily trigger the job on the hive server.
Hive Client or Gateway: It provides a communication channel in-between the current working host or node to the hive server2. With the help of the hive client, we can able to trigger the hive queries on top of the hive server. For the hive JDBC, we need to have the hive JDBC client jar. With the help of this jar, we can establish the JDBC connection and trigger the hive queries on top of the hive server.
Below is the format of the hive JDBC.
| Sr No | JDBC Parameter | Explanation |
| 1 | Hive Node Hostname | It is the host name of the cluster node where the hive server2 is installed. We need to pass the value of the hostname in the host parameter. |
| 2 | Hive server port no | The hive server2 is listing on the specific port (by default, it is listing on 10000 port). As per the hive server configuration, we need to place the port value in this parameter. |
| 3 | Database Name | We need to specify the hive database name. The same database name we need to provide to which we need to connect. By default, it will connect to the default hive database. |
| 4 | Session Confs | It is not mandatory parameter in the JDBC connection. As per the application requirement, we need to set the value in terms of the key and value pair like <key1> = <value1>; <key2> = <key2> … ; |
| 5 | Hive Confs | It is also optional parameters for Hive on the server configuration. Here also, we need to follow the key and value pair format like <key1> = <value1>; <key2> = <key2> … ; |
Examples
Examples to understand Hive JDBC driver.
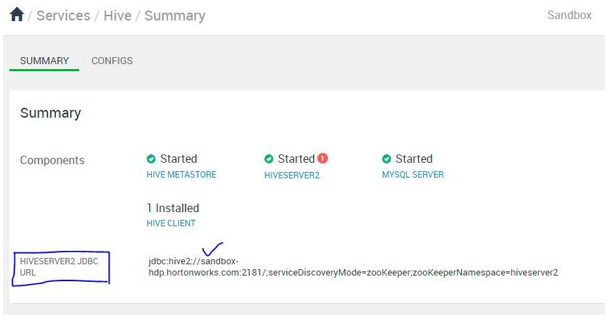
Hive JDBC driver: From Hive Service UI
In the Hadoop environment, we are able to get the hive JDBC path.
Command:
It will on available on the Hadoop UI
Explanation:
We can get the driver JDBC string from the Hadoop UI.
Output:
Hive JDBC driver: From Hive Shell
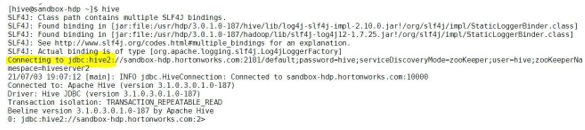
In the Hadoop environment, we can get the hive JDBC string from the hive shell.
Command:
hiveExplanation:
As per the above command, we are able to get the Hive JDBC connection string.
Output:
Hive JDBC driver: From Hive beeline
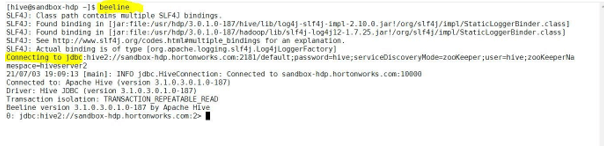
In the hive service, we can get the hive JDBC string from the beeline shell.
Command:
beelineExplanation:
As per the above command, we are able to get the hive JDBC information.
Output:
Advantages of hive JDBC Driver
1) It will enable the communication channel from the login host to the hive server.
2) It will help to onboard the third part application.
3) It can be used with the security services like Knox.
4) It has good support for different BI tools.
5) We can use external hive clients like the squirrel tool with the help of hive JDBC.
Conclusion
We have seen the uncut concept of the “Hive JDBC driver” with the proper example, explanation, and command with different outputs. It will help to connect the hive server. It will easily be integrated with the different security level tools. With the help of the hive JDBC driver, we can work on different BI tools.
Recommended Articles
This is a guide to Hive JDBC Driver. Here we discuss the Introduction, How JDBC driver work in Hive? Examples and code implementation. You may also have a look at the following articles to learn more –
