Updated February 21, 2023

Introduction to Elasticsearch Java
The Elasticsearch technology is written using the Java-based search engine requiring at least the Java 8 version to perform the operations. Using Oracle’s Java and the OpenJDK are the most and only ones that will be handled for all Elasticsearch nodes and clients. We can use the same JVM version that should be utilized in the different Java versions like 1.8 is most recommended for elasticsearch installation.
What is Elasticsearch java?
Elasticsearch is an Apache Lucene-based current search, and also it is one of the analytics engines. It is a NoSQL database that is full fill open-source and written in Java programming language. And this means that it stores data in an unstructured manner and cannot be queried using an SQL database. Hence it is a NoSQL database, and it is in an unstructured way. It places a heavy emphasis on search capabilities and functionalities, at the point where searching for data is using the vast Elasticsearch API; the simplest way is to acquire data from it.
Uses of Elasticsearch
Generally, elasticsearch is used for the open-source, and it is the full-text search and analytics engine that can be highly scalable and is used to enable swiftly storing on the highly explored. Large amounts of datas are to be analyzed with real-time scenarios. Then it is highly and typically employed as the underpinning engine and technology for web-based applications with advanced security and search functionality. The Elasticsearch is joined together with the other components of the ELK Stack, Logstash, and Kibana. It is mainly used for data analysis and serves as a data indexing and storing system. If we need a lot of text using search and typical like RDBMS databases and they are not functioning effectively, a way to perform the poor configuration act like a black box and other performance issues. It is a highly flexible search engine that can be extended using plugins without knowledge and other robust search engines. Elasticsearch has an n number of APIs that may be used to do tasks such as data insertion, data updating, and search among the various data sectors.
Elasticsearch Java Setup
The Java must be installed on the machine where Elasticsearch will be used after installing the java. If we have already installed it on the machine, we use the java -version. Mainly Elasticsearch will be supported for version 11 or higher than Java 8. It is one of the open-source full-text search and analytics engines that runs in a real-time application, and also, the Single Page Application (SPA) developments make use of it. We can set the heap size of the Elasticsearch Java Virtual Machine (JVM) to the amount of RAM available on the machine. We can use the Edit option in the jvm.options for the file to configure the JVM. Machine. It has some pre-defined steps for to perform the elasticsearch setup,
- First, we can set the number of file descriptors to 65536 or more to prevent Elasticsearch from running out of descriptors and other losing data.
- Then, if we want to avoid memory swapping and ensure the system is configured, do so. For example, the Java Virtual Machine (JVM) can be configured to lock the heap in memory using the mlockall default command.
Also, in the elasticsearch.yml file, we can set the bootstrap. The memory lock property is true after installing Elasticsearch, and we can configure it. This attribute prevents memory swapping by setting the memory lock. If the memory locking issues occur when Elasticsearch starts, we may need to specify soft memlock unlimited and hard memlock unlimited.
Elasticsearch java Connecting
The Java API Client is generally made up of three primary elements like below,
- Client classes for APIs: These give Elasticsearch APIs with highly typed data structures and operations. Due to its size, the Elasticsearch API is organized into some feature groups for each with its client class. For example, the ElasticsearchClient class will implement the fundamental functionalities of Elasticsearch.
- A mapper for JSON objects: Next, this converts the application classes to JSON format and combines them with the API client smoothly.
- Implementation of the transport layer: Finally, this is where all HTTP requests are processed.
Java Rest Client:
Example:
package com.example.example3;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Document(indexName="companies")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class companies {
@Id
private String id;
private String name;
}
Repository:
package com.example.example3;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface companyRespository extends ElasticsearchRepository<companies, String>{
}Main:
package com.example.example3;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@RestController
public class Jan5Application {
@Autowired
private companyRespository repo;
@PostMapping("/saveCompany")
public int saveCustomer(@RequestBody List<companies> comp[]) {
repo.saveAll(comp);
return comp.size();
}
@GetMapping("/findAll")
public Iterable<companies> findAllCompanies() {
return repo.findAll();
}
@GetMapping("/findByName/{name}")
public List<companies> findByName(@PathVariable String name) {
return repo.findByname(name);
}
public static void main(String[] args) {
SpringApplication.run(Jan5Application.class, args);
}
}application.properties:
spring.data.elasticsearch.cluster-name=my-application
spring.data.elasticsearch.cluster-nodes=localhost:9300Sample Output:
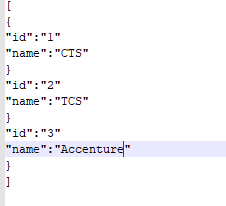
We used the above example to create the spring boot application with Rest API and elasticsearch. Here I created moral classes like companies with the attributes like id and name. Then I created the repository, which the companies like a moral class handle; we can pass the moral class with the datatype. Finally, I have created the main class like RestController to call the moral and repository and to control the company details like id and name. Finally, I have sent the Request using a tool like mail carriers for sent Requests by using the Post method and searching or finding the details using the get method.
Conclusion
Generally, we have seen how to utilize ElasticSearch’s Java API to conduct some of the most typical full-text search engine features to handle the big datas and analytical datas for real-time applications. In addition, the API will handle the controller like Rest Web Services to perform the operations.
Recommended Articles
This is a guide to Elasticsearch Java. Here, we discuss utilizing ElasticSearch’s Java API with conduct and some of the most typical full-text search engine features. You may also look at the following articles to learn more –

