Updated February 18, 2023

Introduction to NLTK POS Tag
NLTK POS tag is the practice of marking up the words in text format for a specific segment of a speech context is known as POS Tagging (Parts of Speech Tagging). It is in charge of interpreting a language’s text and associating each word with a specific token. Grammar tagging is another term for it. A part-of-speech tagger, also known as a POS-tagger, analyses a string of words.
What is NLTK POS Tag?
- The words will assign to part-of-speech tag to one. To begin, we must employ the concept of tokenization.
- The built-in voice tagger is the most useful feature of NLTK for Python. Nltk pos tagger is not flawless, but it is quite good. So we can buy some or alter the existing NLTK code if we want something better.
- The goal of part of speech tagging is to help us grasp sentence structure and start using our computer to follow the sentence meaning of words, part of speech, and the string it forms.
How to use NLTK POS Tag?
The description tokens assignment is tagged, which is a type of classification. The descriptor is a ‘tag,’ representing one of the components of speech and semantic information. When it comes to Part-of-Speech (POS) tagging, on the other hand, it can be defined as the process of turning a sentence written as a list of words into a list of tuples. The tuples, in this case, have the word tag form. POS tagging can alternatively be defined as the process of associating a given the word with a part of speech.
Below steps shows how to use the nltk pos tag by using python as follows:
1. When using the nltk pos tag, the first step is to install nltk in our system. Next, we will install the nltk by using the pip command.
The below example shows installing nltk in our system using the pip command. In the below example, we have already installed nltk so that it will show a message as a requirement already satisfied.
Code:
pip install nltkOutput:

2. Login into the python shell – After installing nltk, the next step is to log into the python shell to execute the python code.
In the below example, we are using the python version as 3.10.2.
Code:
pythonOutput:

3. After logging into the python shell, the next step is to import the nltk module into our code. We are importing the nltk module in our python code by using the import keyword. For example, the “import nltk” command imports the nltk module.
Code:
import nltkOutput:
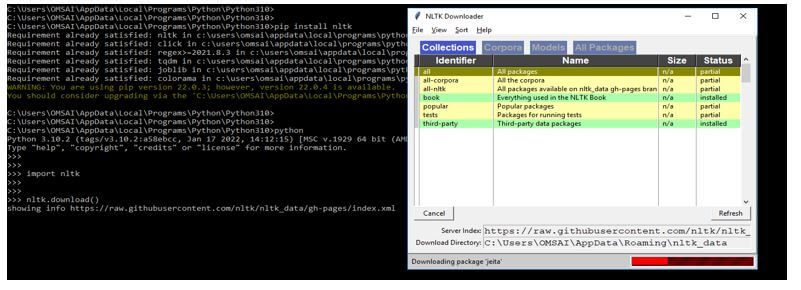
4. After importing the module, the next step is to download all the packages of nltk. The below example shows downloading all the packages of the nltk module as follows. After executing the “nltk.download” command, a graphical user interface will appear, from which we can select “all” for all packages and then click download. This will install tokenizers, various algorithms, chunkers, and corpora, which will take a long time.
Code:
nltk.download()Output:
5. The below example shows how to use the nltk pos tag in our code.
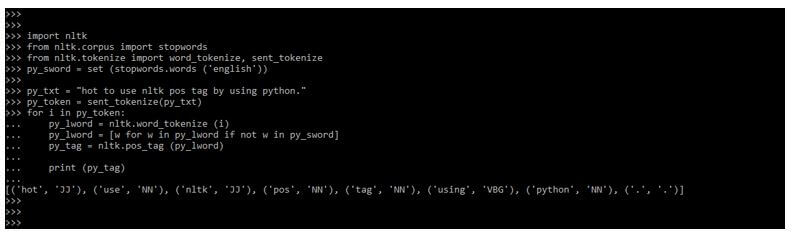
In the example below, we have seen that we have imported the nltk module. After importing the nltk module, we imported the stopwords module using the nltk.corpus. Then we have to import the word_tokenize and sent_tokenize module using nltk.tokenize module. After importing all the modules, we are calling the set method. After calling the set method, we have defined the sentence to use in pos tagging. After defining the sentence, we are calling the sent_tokenize and word_tokenize methods. Then we have to call the nltk.pos_tag method to use the nltk pos tag in our code. At the time of calling this method, we have created the object. After creating the object, we have printed this in output.
Code:
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenize
py_sword = set (stopwords.words ('english'))
py_txt = "hot to use nltk pos tag by using python."
py_token = sent_tokenize (py_txt)
for i in py_token:
py_lword = nltk.word_tokenize (i)
py_lword = [w for w in py_lword if not w in py_sword]
py_tag = nltk.pos_tag (py_lword)
print (py_tag)Output:
NLTK POS Tag List
Below is the pos tag list of nltk as follows. There is a multiple tag list available in nltk, tag list showing in output as per word.
- CC: It is the conjunction of coordinating
- CD: It is a digit of cardinal
- DT: It is the determiner
- EX: Existential
- FW: It is a foreign word
- IN: Preposition and conjunction
- JJ: Adjective
- JJR and JJS: Adjective and superlative
- LS: List marker
- MD: Modal
- NN: Singular noun
- NNS, NNP, NNPS: Proper and plural noun
- PDT: Predeterminer
- WRB: Adverb of wh
- WP$: Possessive wh
- WP: Pronoun of wh
- WDT: Determiner of wp
- VBZ: Verb
- VBP, VBN, VBG, VBD, VB: Forms of verbs
- UH: Interjection
- TO: To go
- RP: Particle
- RBS, RB, RBR: Adverb
- PRP, PRP$: Pronoun personal and professional
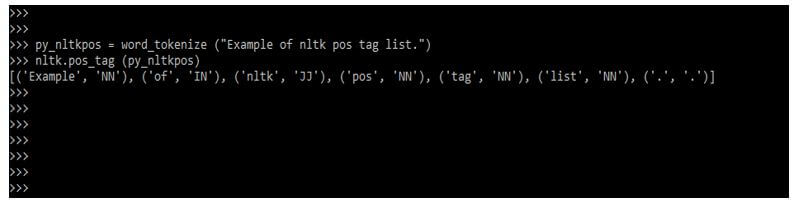
Below example shows an example of the nltk pos tag list as follows:
Code:
py_nltkpos = word_tokenize ("Example of nltk pos tag list.")
nltk.pos_tag (py_nltkpos)Output:
Examples of NLTK POS Tag
Tagging is the first and most fundamental stage in POS tagging, and it may be done with the NLTK’s tagger class.
Tagging assigns each token the same POS tag. Default tagging also serves as a benchmark for measuring accuracy improvements.
Example #1
Below is the example of the default nltk pos tag as follows.
Code:
import nltk
from nltk.tag import DefaultTagger
py_tag = DefaultTagger ('NN')
py_tag.tag (['Example', 'tag'])Output:

Example #2
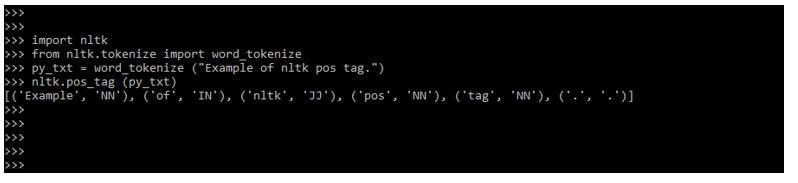
In the below example, we have not used any default tag, so it will show the tag as per the words we have used.
Code:
import nltk
from nltk.tokenize import word_tokenize
py_txt = word_tokenize ("Example of nltk pos tag.")
nltk.pos_tag (py_txt)Output:
Conclusion
POS tagging can alternatively be defined as the process of associating a given the word with a part of speech. Nltk pos tag is the practice of marking the words in text format for a specific segment of a speech context and is known as POS Tagging.
Recommended Articles
This is a guide to NLTK POS Tag. Here we discuss the introduction and how to use the NLTK POS tag with a List and examples. You may also have a look at the following articles to learn more –

