Updated April 4, 2023

Introduction to Scrapy FormRequest
Scrapy form request crawls online sites using Request and Response objects. Request objects are typically generated in the spiders and passed through the system until they reach the downloader, which executes the request and returns a response to the spider that submitted it. Subclasses of Response and Request classes provide functionality not found in the basic classes. Therefore, Scrapy FormRequest is very important and useful.
What is Scrapy FormRequest?
- Traditional scraping techniques will get a long way, but we will run across the problem of Login pages sooner or later. We may wish to scrape data, but we won’t be able to do so unless we have an account logged in.
- Scrapy, by default, visits the website while “not logged in.” Fortunately, Scrapy includes the FormRequest tool, which allows us to automate login into any website if we have the necessary information.
- Each site has its own set of fields, which must be found by the login procedure and watching the data flow.
How to Use Scrapy FormRequest?
- A successful login is very important to developing an automated login. We can implement automated login by using scrapy FormRequest.
- Web scrapping is complicated, and there is no one-size-fits-all approach that will work on all websites. Each Spider must be customized to interact with a single website. However, as explained below, the general notion and concept usually remain the same. The below steps show how to log in with FormRequestare as follows.
- Examine the site’s log-in page. Recreate the login process and list the “Form Data” fields and values. In particular, keep a look out for hidden fields.
- Using our Spider, go to the site’s login page.
- Create parsing functions and add the Scrapy FormRequest with the form data we collected before.
- Make sure our key fields (for form data) correspond to the website’s key fields. After all, variation is to be expected.
- Include a quick check to ensure that we have entered our credentials correctly. Look for differences between the “before login” and “after login” pages. This modification will make it easier to tell if we have logged in correctly.
- After completing the preceding steps successfully, we can now include the parsing function for data we wish to scrape from the website. In addition, regular Scrapy techniques such as rules and so on are now available.
- The below step shows how to use scrapy FormRequest as follows.
1. In this step, we install the scrapy using the pip command. In the below example, we have already installed a scrapy package in our system, so it will show that the requirement is already satisfied, then we do not need to do anything.
pip install scrapy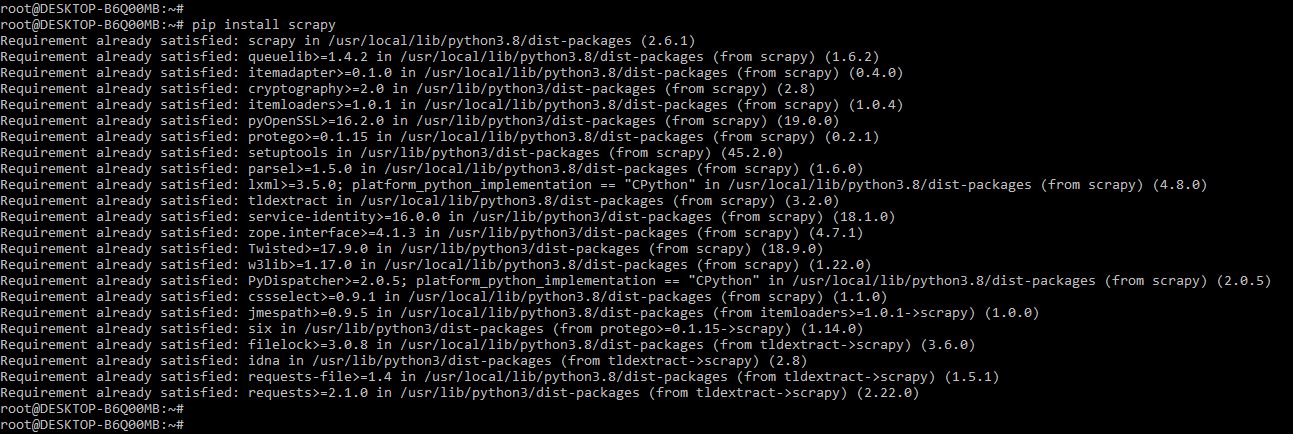
2. After installing the scrapy in this step, we log into the scrapy shell by using the scrapy shell command, or we can also write code into the visual studio.
scrapy shell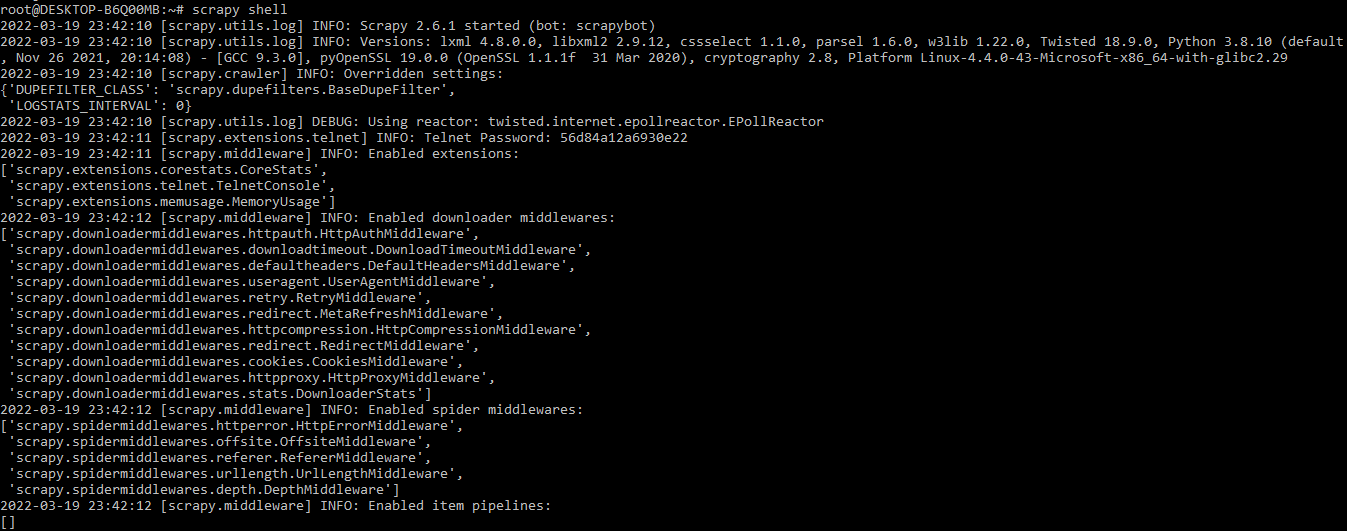
3. After logging into the python shell, duplicate the “Form Data” arguments. If one of the details changes, inspect the page for the changing feature in the source code and extract it into a variable. Then use return FormRequest to include the login information and the name of the callback function that will identify what we want to do scrape from the page we will be routed to after signing in.
Code:
def parse (self, response):
py_tok = response.xpath ('//*[@name="py_token"]/@value').extract_first ()
return FormRequest.from_response (response,
formdata = {
'py_token' = py_tok,
'password' = 'scrapy',
'username' = 'scrapy'},
Callback = self.scrape_pages)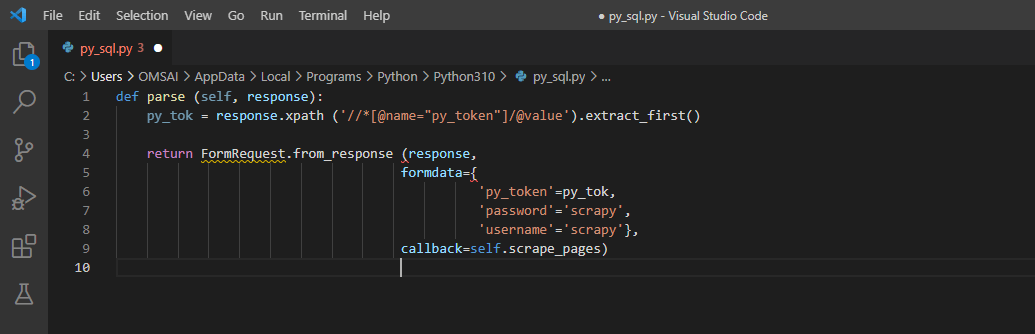
- Scrapy FormRequest is a dictionary that stores arbitrary request metadata. Its content will be submitted as keyword arguments to the Request callback. It’s empty for new Requests.
- The dict is shallow copied and can also be accessed from the response in our spider. Cb_kwargs is a variable.
- This dict can be seen in the request’s errback as a failure. request.cb kwargs in the event of a request failure.
Scrapy FormRequest Examples
- Except for any members whose values have been changed by the keyword arguments. By default, shallow copies are made of the request.cb kwargs and Request.meta attributes.
- The HTTP method, URL, headers, cookies, and body are all filled up. This is because it precedes the values of the same arguments in the cURL command.
- The below example shows that examples of scrapy formrequest are as follows. In the below example, we will be splitting the function into two parts. The first one, parse, is executed automatically on the start URL we defined. Make the start URL or request point to the site’s login page.
- We obtain the value of the CSRF token in the parse function and feed it along with the login and password we used before into the FormRequest function.
Example #1
The below example shows a simple code of scrapy formrequest as follows.
Code:
class ScrapySpider (CrawlSpider):
py_name = 'scrapy'
py_domains = ['example.com']
py_surl = ['http://example.com/scrapy']
def parse (self, response):
py_token = response.xpath ('//*[@name="py_token"]/@value').extract_first()
print (py_token)
yield FormRequest.from_response(response, formdata={'py_token': py_token, 'username':'scrapy', 'password': 'scrapy'}, callback=self.parse_after_login)
def parse_after_login (self, response):
print (response.xpath('.//div[@class = "col-md-4"]/p/a/text()'))
- It’s worth noting that the FormRequest is tied to a function called parse after login. After a successful login, this function is in charge of handling all subsequent activities.
- In this new function, we’ve introduced a single line that checks whether or not the login was successful. According to our observations, the website says “login” in a certain part. However, it will also say “log out” if we are logged in.
Example #2
The below example shows a scrapy formrequest; in this example, we are using the “example.com” url.
Code:
def parse (self, response):
py_url = "https://example.com/scrapy"
py_form = {
"search_downloads": ".scrapy",
}
return [FormRequest(py_url = py_url, method = "POST",
formdata = py_form, callback = self.parse_form)]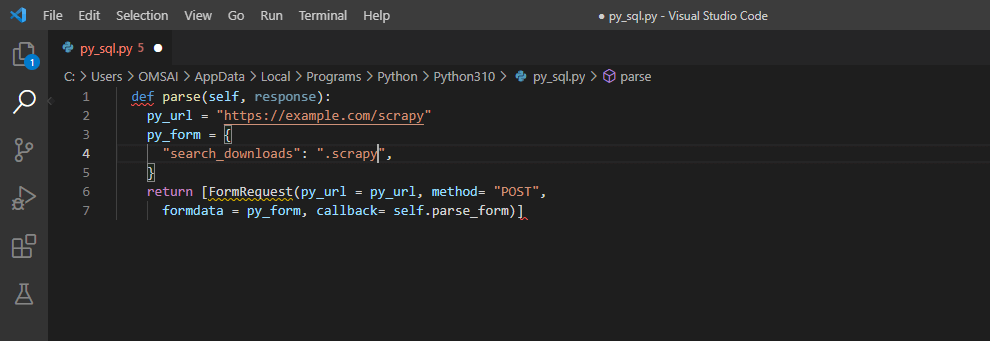
Example #3
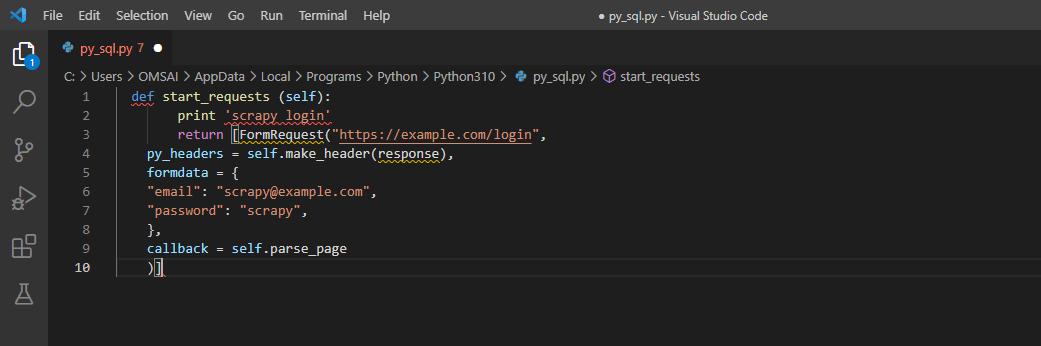
In the below example, we are using formrequest with example.com URL. In addition, we have used email ID and password to validate the request.
Code:
def start_requests (self):
print 'scrapy login'
return [FormRequest ("https://example.com/login",
py_headers = self.make_header (response),
formdata = {
"email": "[email protected]",
"password": "scrapy",
},
callback = self.parse_page
)]
Conclusion
Each site has its own set of fields, which must be found by the login procedure and watching the data flow. Scrapy formrequest crawls online sites using Request and Response objects. Request objects are typically generated in the spiders and passed through the system until they reach the downloader.
Recommended Articles
We hope that this EDUCBA information on “Scrapy FormRequest” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
