Updated June 8, 2023

Introduction to SQLAlchemy Upsert
SQLAlchemy deals with the process of upserting the data which means inserting new records into the table and modifying/ updating the existing rows present inside the table. In this article, we will study about SQLAlchemy upsert and also have a detailed look at it by studying the subtopics including What is sqlalchemy upsert, How to sqlalchemy upsert, sqlalchemy upsert method, sqlalchemy upsert Examples, and Conclusion about the same.
What is sqlalchemy upsert?
SQLAlchemy upsert is a technique using which we can update the existing records in the tables of the database and even go for adding the new records to the same table of the same database. For this, we need to make sure that we are establishing the connection between the python application and the database that we will be using to store the data of the application. Here, we will be making the use of an SQL server, though it’s not compulsory. The upserting can be carried out on a wide range of databases that are supported by SQLalchemy and python libraries. We will also make sure that the upsert of data happens in a lightning-fast way.
Using this process, we can handle huge amounts of data sets and deliver validations of data and performance at high speed. We will be seeing step by step process to upsert the data with the help of an example.
How to sqlalchemy upsert?
We will have to follow some sequential steps while performing an upsert of data. The below bullet points list all the steps –
- Prerequisites and setup of the environment – This includes deciding the data and tables of databases that are to be upserted and setting the goal of the task.
- Preparing the database – Here, we will create the required tables in database and also insert the required data to the tables. These tables will also contain those tables which are to be upserted. It will involve the CREATE and INSERT statements in SQL.
- Loading the data in the python application – It will contain loading the CSV that is the comma-separated file in the python application files by using the method of read_csv() for which we can make the use of Pandas library or any other library of python that is convenient for you to use.
- Creating a new connection to the database from python files – This can be achieved by using the drivers and creating the database engine containing all the passed configurations for connection.
- Upserting the required data – For upserting the data, we will be making the use of a temporary table where we will insert all the data and then go for merging the original table that is to be upserted and the temporary table. Merge operation will allow us to perform all three operations of inserting, updating, and deleting the records in just a single statement.
- Check our results – You can fire up a SELECT query to confirm the contents of the upserted table.
SQLAlchemy upsert method
Upserting requires the following steps as a methodology to accomplish the task –
Step 1:
We will have to create a new temporary table where we can store the records. For example, /let us create temporary table NewTechnologies –
CREATE TABLE #NewTechnologies (
[SKU] INT UNIQUE
, [Technology_type] NVARCHAR(100)
, [Domain] NVARCHAR(100)
, [Technology_name] NVARCHAR(100)
, [Number_of_pages] INT
, [rate_per_page] FLOAT
)Which gives the following output –
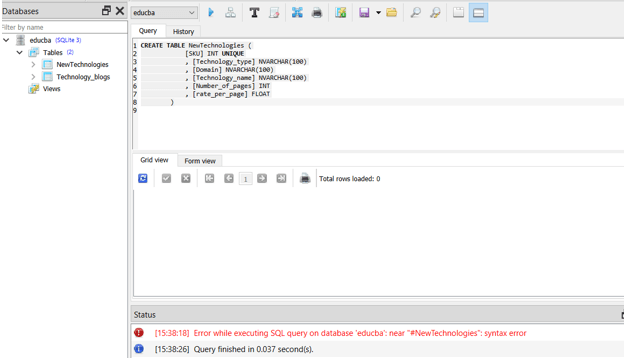
Step 2:
The new data that is to be added should be inserted in the temporary table where we can make use of some of the options such as fast_execute and bulk insertion which makes this step superfast.
For insertion, we will use the following statement –
INSERT INTO NewTechnologies ([SKU], [Technology_type], [Domain], [Technology_name], [Number_of_pages], [rate_per_page]) VALUES
(123, 'Data Handling', 'Database', 'SQL', 1358, 299.95)
, (24, 'Data Handling', 'Cloud', 'AWS', 885, 389.99)
, (5577, 'Data Handling', 'DBMS', 'SQl_Server', 8, 295.00)
, (1233, 'Front End', 'Structure', 'HTML', 334, 659.99)
, (33, 'Front End', 'Beautification', 'CSS', 25, 517.00)
, (34, 'Back End', 'Handling and manipulating requests', 'Python', 12, 319.00)Which results in output –
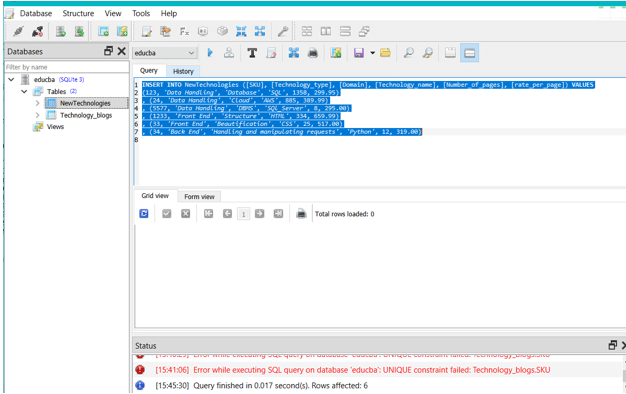
Step 3:
Merging the target table with the newly created temporary table. While performing the merge operation, there are some internal things that happen to give the resulting upserted data in the target table which includes
– In case if records are not present inside the target table then they are inserted from temporary to the target table.
– The updation of all the records including any change in the columns is performed.
– The records that are not present in the temporary table but are there in the target table are deleted. This can be done on an optional basis if we want to keep it simple a pure upsert task.
Step 4 – The final step is to go for deleting our temporary table which can be done by using the below statement –
DROP TABLE IF EXISTS #NewTechnologies
This results in the following output –
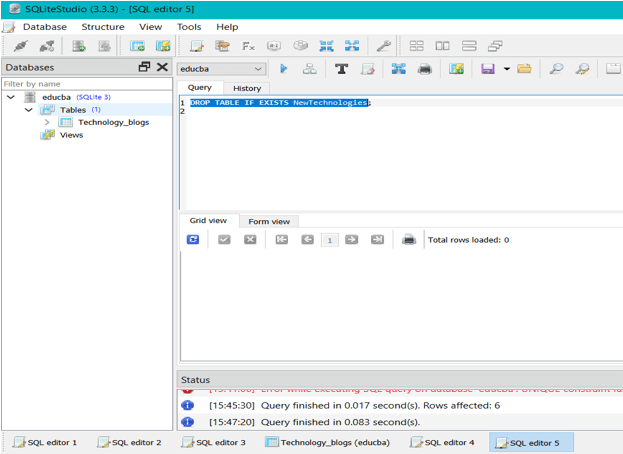
SQLAlchemy upsert Examples
Let us consider a simple step-by-step example of how we can upsert the data in the table.
Step 1 – Prerequisites and setup of the environment – Open the SQL studio Lite and set all the tables to be upserted.
Step 2 – Preparing the database – Here, we will create a table named technology_blogs and insert some data in it with the help of below-mentioned query statements –
CREATE TABLE Technology_blogs (
[SKU] INT UNIQUE
, [Technology_type] NVARCHAR(100)
, [Domain] NVARCHAR(100)
, [Technology_name] NVARCHAR(100)
, [Number_of_pages] INT
, [rate_per_page] FLOAT
, [time_of_creation] DATETIME
, [time_of_updation] DATETIME
)Output is as shown below –
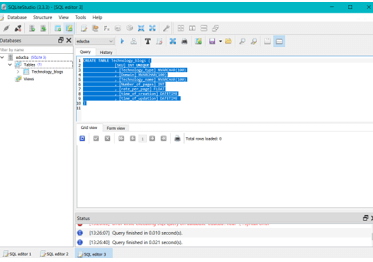
INSERT INTO Technology_blogs ([SKU], [Technology_type], [Domain], [Technology_name], [Number_of_pages], [rate_per_page]) VALUES
(123, 'Data Handling', 'Database', 'SQL', 1337, 1299.95)
, (24, 'Data Handling', 'Cloud', 'AWS', 885, 1389.99)
, (5577, 'Data Handling', 'DBMS', 'SQl_Server', 8, 2295.00)
, (1233, 'Front End', 'Structure', 'HTML', 334, 1659.99)
, (33, 'Front End', 'Beautification', 'CSS', 25, 2517.00)
, (34, 'Back End', 'Handling and manipulating requests', 'Python', 12, 319.00)The execution of the above statement gives the following output –
Step 3 – Loading the data in the python application –
For this, we will write the below code in one of the python files –
import csv
import pandas as pd
import sqlalchemy
def main():# 1. Load the new products
df = pd.read_csv('data/new_products.csv', dtype={
'SKU': int,
'Type': str,
'Domain': str,
'Technology_name': str,
'Number_of_pages': int,
'rate_per_page': float,
})
if __name__=="__main__":
main()which looks as below in the editor –
Step 4 – Creating a new connection to the database from python files –
We will write the below code in our python db file used for configuration –
database = "Educba"
driver = "ODBC Driver 17 for SQL Server"
dbEngine = sqlalchemy.create_engine(
f"mssql+pyodbc://localhost/{database}?driver={driver}&trusted_connection=yes",
fast_executemany=True,
connect_args={'connect_timeout': 10})which looks as shown below in the editor –

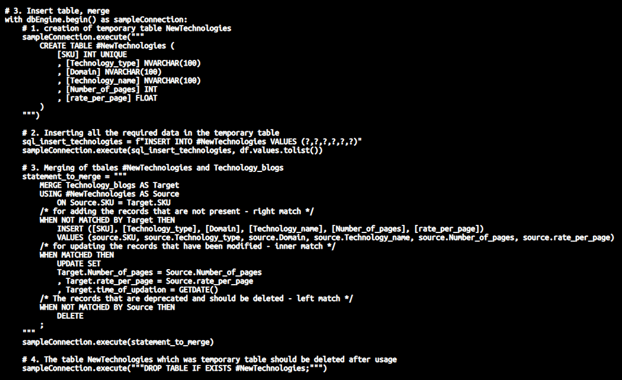
Step 5 – Upserting the required data –
We will now, write the code that will upsert the data with the help of the merge operation –
# 3. Insert table, merge
with dbEngine.begin() as sampleConnection:# 1. creation of temporary table NewTechnologies
sampleConnection.execute(“””
CREATE TABLE #NewTechnologies (
[SKU] INT UNIQUE
, [Technology_type] NVARCHAR(100)
, [Domain] NVARCHAR(100)
, [Technology_name] NVARCHAR(100)
, [Number_of_pages] INT
, [rate_per_page] FLOAT
)
""")# 2. Inserting all the required data in the temporary table
sql_insert_technologies = f"INSERT INTO #NewTechnologies VALUES (?,?,?,?,?,?)"
sampleConnection.execute(sql_insert_technologies, df.values.tolist())# 3. Merging of tables #NewTechnologies and Technology_blogs
statement_to_merge = """
MERGE Technology_blogs AS TargetUSING #NewTechnologies AS Source
ON Source.SKU = Target.SKU/* for adding the records that are not present – right match */
WHEN NOT MATCHED BY Target THEN
INSERT ([SKU], [Technology_type], [Domain], [Technology_name], [Number_of_pages], [rate_per_page])
VALUES (source.SKU, source.Technology_type, source.Domain, source.Technology_name, source.Number_of_pages, source.rate_per_page)
/* for updating the records that have been modified - inner match */
WHEN MATCHED THEN
UPDATE SET
Target.Number_of_pages = Source.Number_of_pages
, Target.rate_per_page = Source.rate_per_page
, Target.time_of_updation = GETDATE()
/* The records that are deprecated and should be deleted - left match */
WHEN NOT MATCHED BY Source THEN
DELETE
;
"""
sampleConnection.execute(statement_to_merge)# 4. The table NewTechnologies which was a temporary table should be deleted after usage
sampleConnection.execute("""DROP TABLE IF EXISTS #NewTechnologies;""")which looks as shown below on the editor. Also, the hash statements are comments demonstrating the step-by-step process for merging that is upserting.
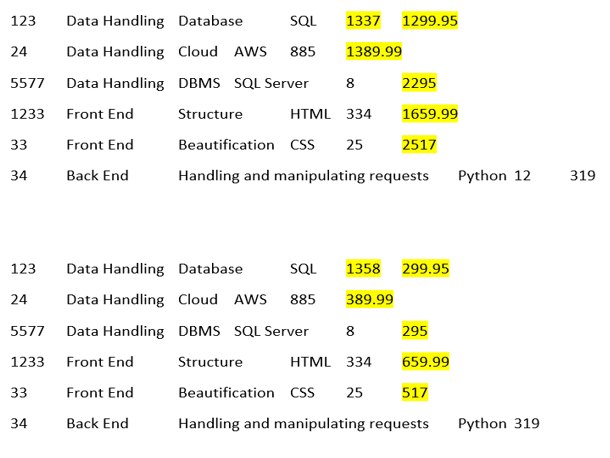
Step 5 – Check our results –
If we give a check on the contents of the table before and after upserting, we can get the following differences –
Conclusion
SQLAlchemy Upsert is the methodology where the new data is inserted in the table as well as existing data is modified and updated. This is carried out in SQLAlchemy with the help of the Merge operation where we can skip the delete part and just perform insert and update operations in the merge statement.
Recommended Articles
This is a guide to SQLAlchemy Upsert. Here we discuss the definition, What is sqlalchemy upsert, How to sqlalchemy upsert, examples with code implementation. You may also have a look at the following articles to learn more –
