Updated February 21, 2023

Introduction to PySpark Join on Multiple Columns
PySpark Join on multiple columns contains join operation, which combines the fields from two or more data frames. We are doing PySpark join of various conditions by applying the condition on different or same columns. We can eliminate the duplicate column from the data frame result using it. Join on multiple columns contains a lot of shuffling.
Overview
Using the join function, we can merge or join the column of two data frames into the PySpark. Different types of arguments in join will allow us to perform the different types of joins. We can use the outer join, inner join, left join, right join, left semi join, full join, anti join, and left anti join. In analytics, PySpark is a very important term; this open-source framework ensures that data is processed at high speed. It will be supported in different types of languages.
PySpark is a very important python library that analyzes data with exploration on a huge scale. It is used to design the ML pipeline for creating the ETL platform. Pyspark is used to join the multiple columns and will join the function the same as in SQL. The join function includes multiple columns depending on the situation.
How to use Join Multiple Columns in PySpark?
We must follow the steps below to use the PySpark Join multiple columns. First, we are installing the PySpark in our system.
- In the below example, we are installing the PySpark in the windows system by using the pip command as follows.
pip install pyspark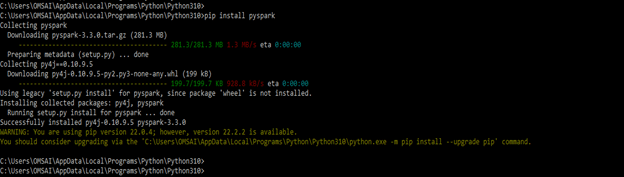
- Installing the module of PySpark in this step, we login into the shell of python as follows.
python
- After logging into the python shell, we import the required packages we need to join the multiple columns.
import pyspark
from pyspark.sql import SparkSession
- After importing the modules in this step, we create the first data frame.
Code:
spark_join = SparkSession.builder.appName ('sparkdf').getOrCreate()
data_join = [(13, "ABC"), (15, "PQR"), (17, "XYZ")]
columns_join = ['stud_id', 'stud_name']
dataframe_join = spark_join.createDataFrame (data_join, columns_join)
dataframe_join.show()Output:

- After creating the first data frame now in this step we are creating the second data frame as follows.
Code:
spark_join1 = SparkSession.builder.appName ('sparkdf').getOrCreate()
data_join1 = [(13, "ABC"), (15, "PQR"), (17, "XYZ")]
columns_join1 = ['stud_id', 'stud_name']
dataframe_join1 = spark_join1.createDataFrame (data_join1, columns_join1)
dataframe_join1.show ()Output:

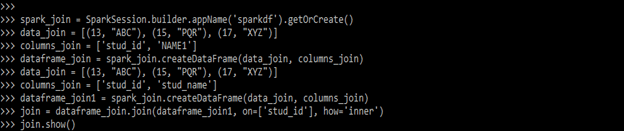
- After creating the data frame, we are joining two columns from two different datasets.
Code:
import pyspark
from pyspark.sql import SparkSession
spark_join = SparkSession.builder.appName ('sparkdf').getOrCreate()
data_join = [(13, "ABC"), (15, "PQR"), (17, "XYZ")]
columns_join = ['stud_id', 'NAME1']
dataframe_join = spark_join.createDataFrame (data_join, columns_join)
data_join = [(13, "ABC"), (15, "PQR"), (17, "XYZ")]
columns_join = ['stud_id', 'stud_name']
dataframe_join1 = spark_join.createDataFrame (data_join, columns_join)
dataframe_join.join (dataframe_join1, (dataframe_join.stud_id == dataframe_join1.stud_id)
& (dataframe_join.NAME1 == dataframe_join1.stud_name)).show()Output:

How Multiple Columns work in PySpark?
Below are the different types of joins available in PySpark. As per join, we are working on the dataset.
- Inner join
- Left outer join
- Right outer join
- Full outer join
- Cross join
- Left semi join
- Left anti-join.
The inner join is a general kind of join that was used to link various tables. It will be returning the records of one row, the below example shows how inner join will work as follows.
Code:
import pyspark
from pyspark.sql import SparkSession
spark_join = SparkSession.builder.appName('sparkdf').getOrCreate()
data_join = [( )]
columns_join = ['stud_id', 'NAME1']
dataframe_join = spark_join.createDataFrame(data_join, columns_join)
data_join = [( )]
columns_join = ['stud_id', 'stud_name']
dataframe_join1 = spark_join.createDataFrame (data_join, columns_join)
join = dataframe_join.join(dataframe_join1, on=['stud_id'], how='inner')
join.show ()Output:
The outer join into the PySpark will combine the result of the left and right outer join. The below example shows how outer join will work in PySpark as follows.
Code:
import pyspark
from pyspark.sql import SparkSession
spark_join = SparkSession.builder.appName ('sparkdf').getOrCreate()
data_join = [( )]
columns_join = ['stud_id', 'NAME1']
dataframe_join = spark_join.createDataFrame(data_join, columns_join)
data_join = [( )]
columns_join = ['stud_id', 'stud_name']
dataframe_join1 = spark_join.createDataFrame (data_join, columns_join)
join = dataframe_join.join(dataframe_join1, on=['stud_id'], how='outer')
join.show()Output:

Pyspark Join on Multiple Columns Dataframes
Pyspark join on multiple column data frames is used to join data frames. The below syntax shows how we can join multiple columns by using a data frame as follows:
Syntax:
join(right, joinExprs, joinType)join(right)In the above first syntax right, joinExprs, joinType as an argument and we are using joinExprs to provide the condition of join. In a second syntax dataset of right is considered as the default join.
In the below example, we are creating the first dataset, which is the emp dataset, as follows.
Code:
import pyspark
from pyspark.sql import SparkSession
spark_join1 = SparkSession.builder.appName('sparkdf').getOrCreate()
data_join1 = [(21, "BC"), (23, "QR"), (25, "YZ")]
columns_join1 = ['emp_id', 'emp_name']
dataframe_join1 = spark_join1.createDataFrame(data_join, columns_join)
dataframe_join1.show()Output:

In the below example, we are creating the second dataset for PySpark as follows. Here we are defining the emp set.
Code:
import pyspark
from pyspark.sql import SparkSession
spark_join2 = SparkSession.builder.appName ('sparkdf').getOrCreate()
data_join2 = [(31, "AC"), (33, "PR"), (35, "XZ")]
columns_join2 = ['emp_id', 'emp_name']
dataframe_join2 = spark_join2.createDataFrame (data_join, columns_join)
dataframe_join2.show()Output:

Examples
Below are the different examples:
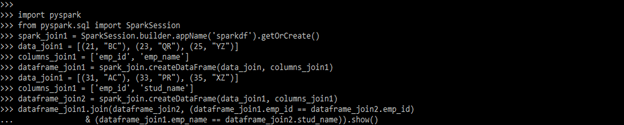
Example #1
In the below example, we are using the inner join.
Code:
import pyspark
from pyspark.sql import SparkSession
spark_join1 = SparkSession.builder.appName('sparkdf').getOrCreate()
data_join1 = [(21, "BC"), (23, "QR"), (25, "YZ")]
columns_join1 = ['emp_id', 'emp_name']
dataframe_join1 = spark_join.createDataFrame(data_join, columns_join1)
data_join1 = [(31, "AC"), (33, "PR"), (35, "XZ")]
columns_join1 = ['emp_id', 'stud_name']
dataframe_join2 = spark_join.createDataFrame(data_join1, columns_join1)
dataframe_join1.join(dataframe_join2, (dataframe_join1.emp_id == dataframe_join2.emp_id)
& (dataframe_join1.emp_name == dataframe_join2.stud_name)).show()Output:
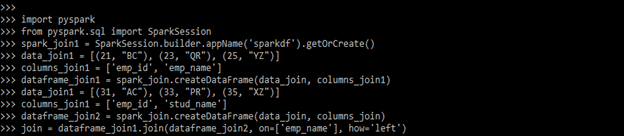
Example #2
In the below example, we are using the inner left join.
Code:
import pyspark
from pyspark.sql import SparkSession
spark_join1 = SparkSession.builder.appName ('sparkdf').getOrCreate()
data_join1 = [(21, "BC"), (23, "QR"), (25, "YZ")]
columns_join1 = ['emp_id', 'emp_name']
dataframe_join1 = spark_join.createDataFrame (data_join, columns_join1)
data_join1 = [(31, "AC"), (33, "PR"), (35, "XZ")]
columns_join1 = ['emp_id', 'stud_name']
dataframe_join2 = spark_join.createDataFrame (data_join, columns_join)
join = dataframe_join1.join (dataframe_join2, on=['emp_name'], how='left')
join.show()Output:
Key Takeaways
- In PySpark join on multiple columns, we can join multiple columns by using the function name as join also, we are using a conditional operator to join multiple columns.
- We also join the PySpark multiple columns by using OR operator. We need to specify the condition while joining.
FAQ
Given below are the FAQs mentioned:
Q1. What is the use of multiple columns join in PySpark?
Answer: It is used to join the two or multiple columns. We join the column as per the condition that we have used.
Q2. Which operator is used to join the multiple columns in PySpark?
Answer: We can use the OR operator to join the multiple columns in PySpark. We are using a data frame for joining the multiple columns.
Q3. What are the join types used in PySpark?
Answer: We are using inner, left, right outer, left outer, cross join, anti, and semi-left join in PySpark.
Conclusion
There are different types of arguments in join that will allow us to perform different types of joins in PySpark. Pyspark joins on multiple columns contains join operation which was used to combine the fields from two or more frames of data.
Recommended Articles
This is a guide to PySpark Join on Multiple Columns. Here we discuss the introduction and how to join multiple columns in PySpark along with working and examples. You may also have a look at the following articles to learn more –

