Updated March 17, 2023
Introduction to Azure Data Factory Oracle
Azure data factory oracle is used to transfer the data. We are developing a pipeline to transfer data from Oracle on-premises database tables to Azure data lake files. While using the azure data factory, first, we need to install a data management gateway in our system; this is a very simple installation procedure. Also, we need to create two linked services for the azure data factory.
Key Takeaways
- Azure IR provides the compute, which was fully managed to perform the dispatch data transformation and data movement.
- Basically, azure data factory is used to transfer the data from the on-premises oracle database to the azure lake cloud. It is an important tool used for data transfer from on-premises to the cloud.
What is Azure Data Factory Oracle?
At the time of working with azure data factory, we need to create two services, one for the source oracle database and another for the target Azure Data Lake. The linked service is nothing but the connection information required by the data factory to connect to external resources. Azure data factory supports connecting to on-premises Oracle databases using the data management gateway.
The data management gateway is important in the data factory even though our database is hosted in the Azure infrastructure. We install the same gateway on the same VM, so data is stored on a different VM, and the gateway can connect to the database server. At the time of installing the data management gateway, the driver of Microsoft is automatically installed by using a gateway.
Azure Data Factory Oracle Integration Runtime
The integration runtime is a compute infrastructure used for the synapse pipeline and azure data factory for providing data integration capabilities across multiple network environments. The below steps show how we can create the azure data factory integration as follows:
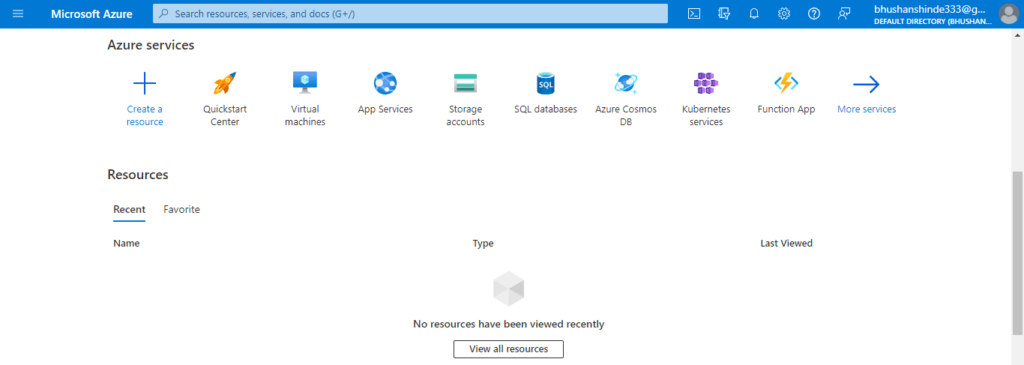
1. In the first step, we are logging in to the Azure portal by using specified credentials as follows.
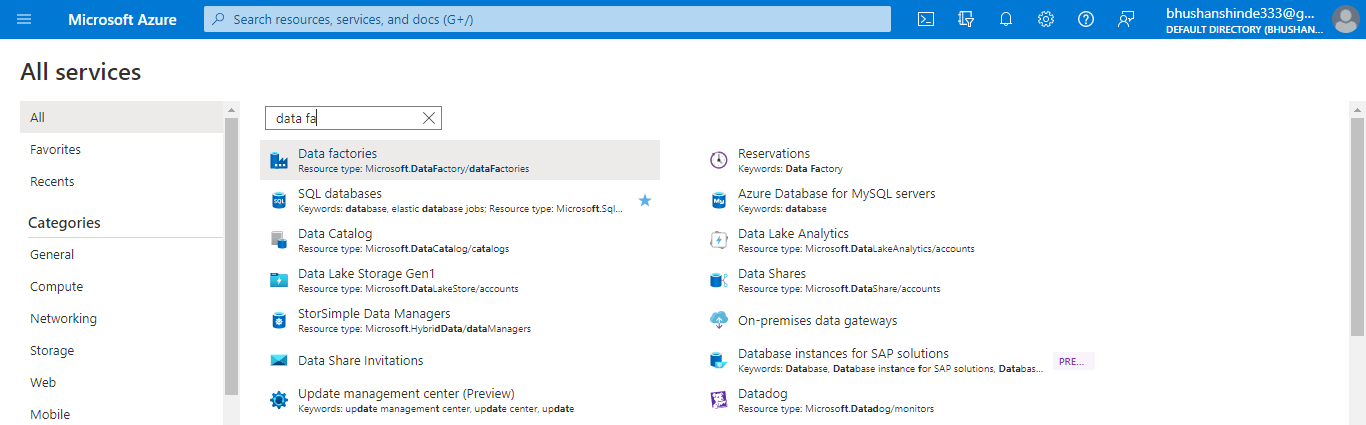
2. After login into the azure portal now, in this step, we are searching for azure data factories as follows.
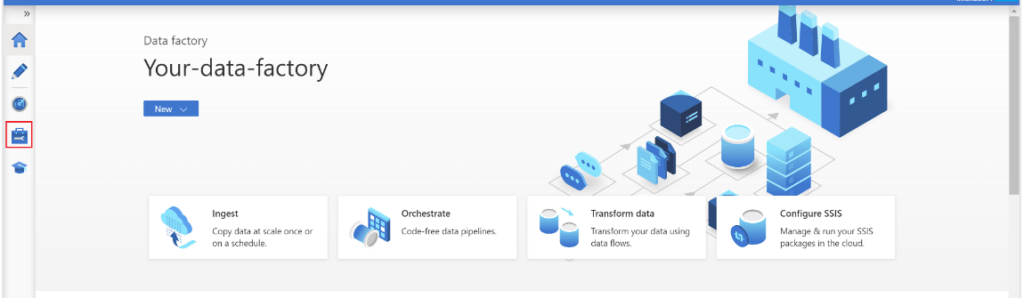
3. After selecting the data factory now, in this step, we are opening the azure data factory service as follows.
4. After opening the homepage of azure data factory now, in this step, we are selecting the integration runtime for integrating with the oracle database.
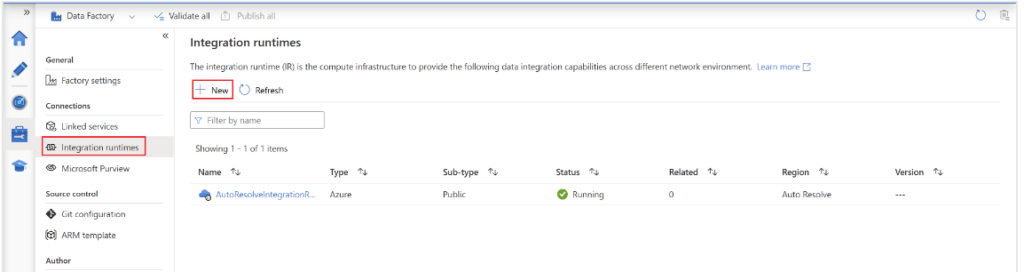
5. After selecting the integration runtime, now in this step we are selecting the type of azure integration as follows.
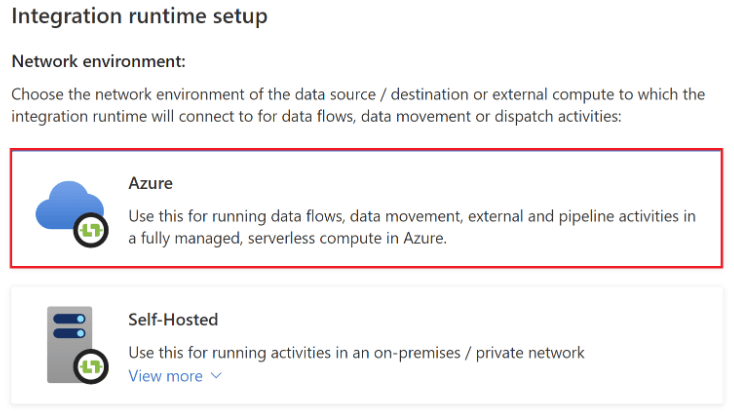
6. After selecting the azure integration in this step, we need to define the name of azure integration to create the same as follows.
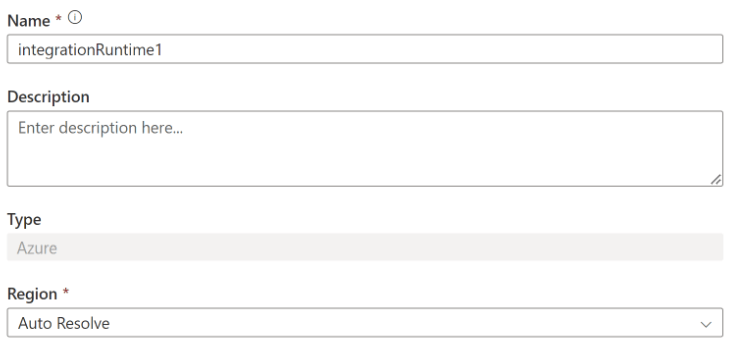
7. After defining the name and entering on create button, we can see that our integration is created as follows.
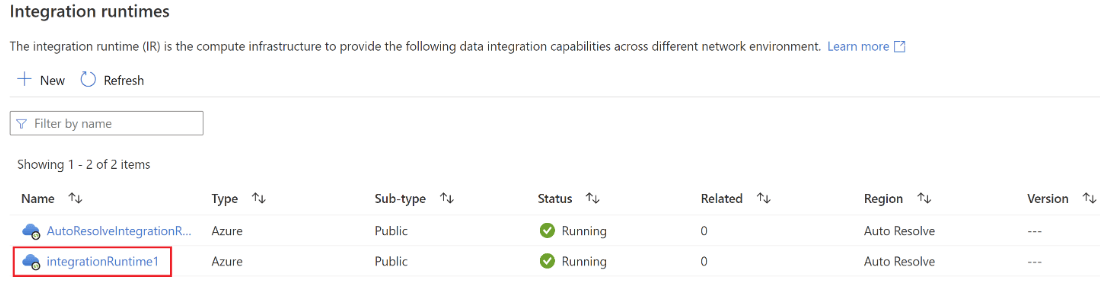
Azure Data Factory Oracle to Copy
The below steps show how we can copy the data from the Oracle database to azure as follows:
1. While copying the data, we need to create the linked service to the oracle service cloud by using UI. In the below example, we are selecting the linked service as follows.
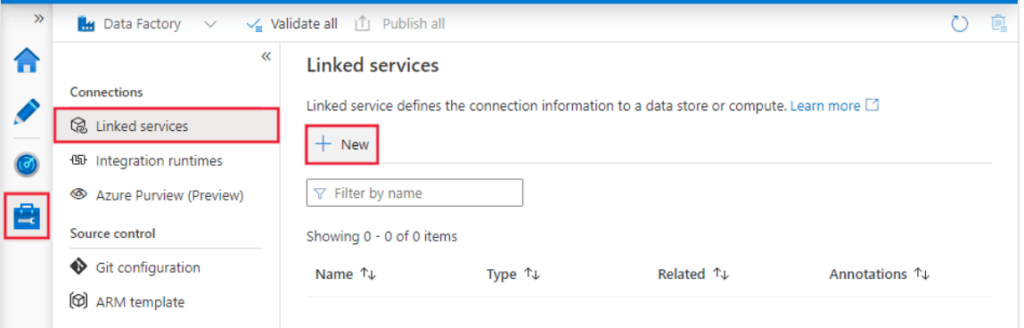
2. After selecting the linked service now, in this step, we are defining the linked service as an oracle as follows.
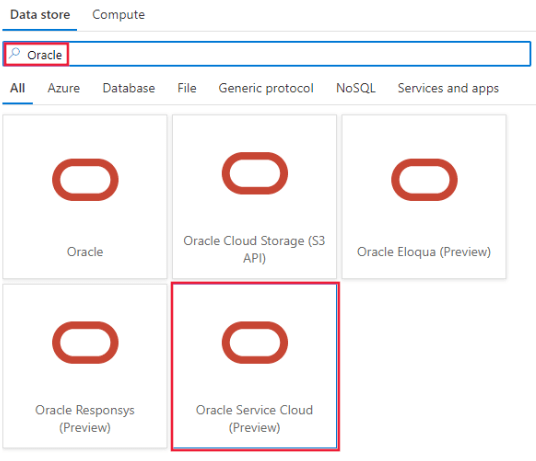
3. After selecting the oracle linked service, we are now filling in all the details and creating a new linked service as follows.
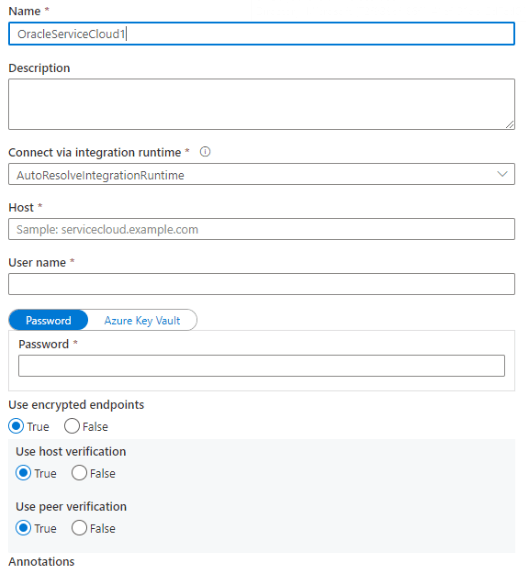
4. After creating the linked service now, in this step, we define the details of the connector configuration.
{
"name": "OracleService",
"properties": {
"type": "OracleServiceCloud",
"typeProperties": {
"host" : "example.com",
"username" : "ocloud",
"password": {
"type": "SecureString",
"value": "Test@123"
},
"useEncryptedEndpoints" : true,
"useHostVerification" : true,
"usePeerVerification" : true,
} }
}
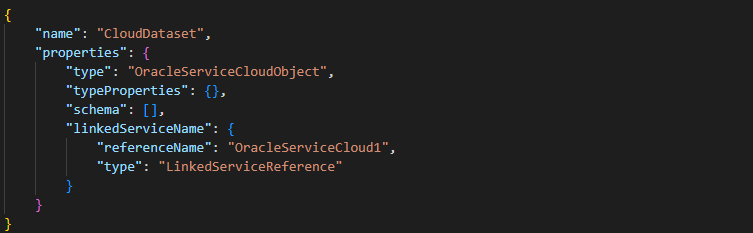
5. After defining the connector configuration now, we are defining the dataset properties as follows.
{
"name": "CloudDataset",
"properties": {
"type": "OracleServiceCloudObject",
"typeProperties": {},
"schema": [],
"linkedServiceName": {
"referenceName": "OracleServiceCloud1",
"type": "LinkedServiceReference"
}
}
}
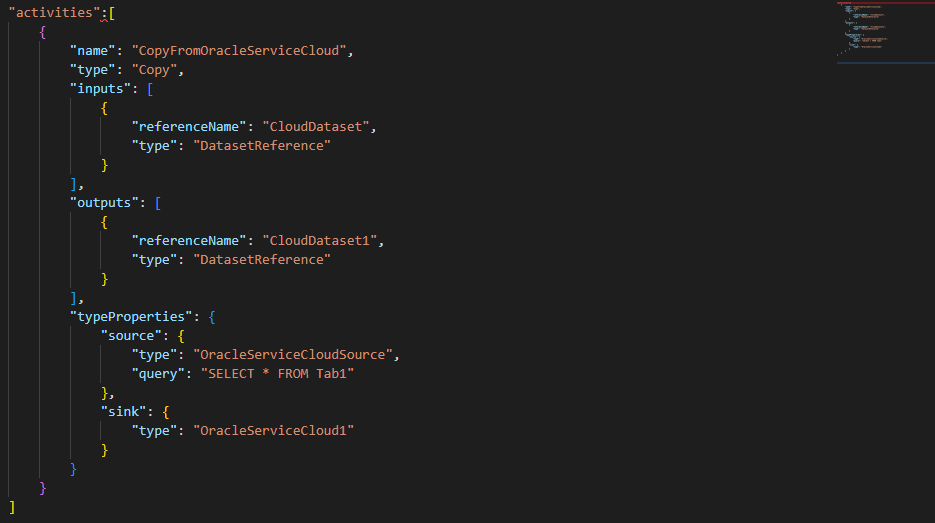
6. After defining the properties dataset, we are copying the activities properties as follows.
"activities": [
{
"name": "CopyFromOracleServiceCloud",
"type": "Copy",
"inputs": [
{
"referenceName": "CloudDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "CloudDataset1",
"type": "DatasetReference"
}
],
"typeProperties":
{
"source":
{
"type": "OracleServiceCloudSource",
"query": "SELECT * FROM Tab1"
},
"sink":
{
"type": "OracleServiceCloud1"
}
}
} ]
Oracle Database Service
We need a standard database driver for clients to access on-premises databases. For creating the oracle database linked service for azure data factory, we need to open the author and need to deploy the tool. Then we need to select the new data store for oracle. It is opening the definition of draft JSON for oracle DB in the linked service.
The below example shows how we can create the linked service as follows:
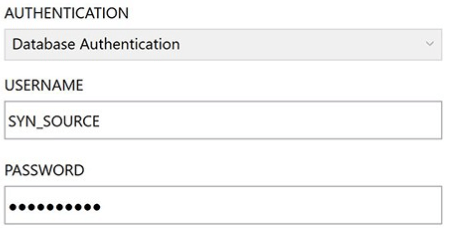
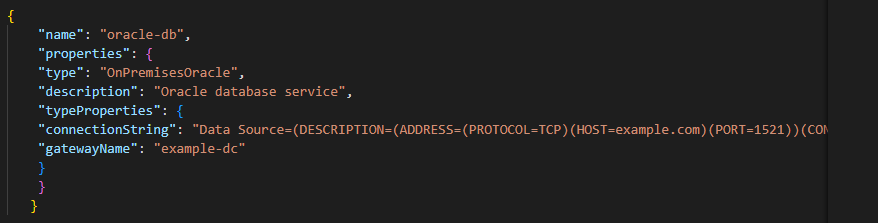
After defining the linked service of azure now, we are creating the JSON file of the oracle database service.
{
"name": "oracle-db",
"properties": {
"type": "OnPremisesOracle",
"description": "Oracle database service",
"typeProperties": {
"connectionString": "Data Source=(…)",
"gatewayName": "example-dc"
}
}
}
Type Mapping for Oracle
Oracle maps the ANSI data types through ODBC and by using the OLE DB interface, which was supported by oracle data types. At the time results of the query are returned, oracle converts the ODBC data types into the oracle data types.
The below table shows the mapping of ANSI data types to the oracle data types by using the ODBC interface as follows:
| ANSI | ODBC | Oracle |
| NUMERIC (19, 0) | SQL_BIGINT | NUMBER(19, 0) |
| N/A | SQL_BINARY | RAW |
| CHAR | SQL_CHAR | CHAR |
| DATE | SQL_DATE | DATE |
| DECIMAL (P, S) | SQL_DECIMAL (P, S) | NUMBER (P, S) |
| DOUBLE PRECISION | SQL_DOUBLE | FLOAT(49) |
| FLOAT | SQL_FLOAT | FLOAT(49) |
| INTEGER | SQL_INTEGER | NUMBER(10) |
| N/A | SQL_LONGVARBINARY | LONG RAW |
| N/A | SQL_LONGVARCHAR | LONG |
| REAL | SQL_REAL | FLOAT(23) |
| SMALLINT | SQL_SMALLINT | NUMBER(5) |
| TIME | SQL_TIME | DATE |
| TIMESTAMP | SQL_TIME | DATE |
| NUMERIC (3, 0) | SQL_TINYINT | NUMBER(3) |
| VARCHAR | SQL_VARCHAR | VARCHAR |
Azure Data Factory Oracle File Examples
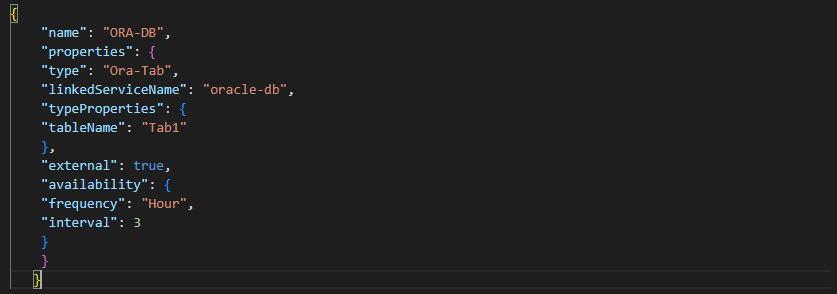
While comparing definitions of linked services, creating the source datasets and the target is very simple. Datasets are self-explaining from the JSON files. We are using batches to extract the same. The below example shows the source dataset of the oracle file as follows. We are using the table name Tab1. We are reading data in three-hour slices as follows.
{
"name": "ORA-DB",
"properties": {
"type": "Ora-Tab",
"linkedServiceName": "oracle-db",
"typeProperties": {
"tableName": "Tab1"
},
"external": true,
"availability": {
"frequency": "Hour",
"interval": 3
}
}
}
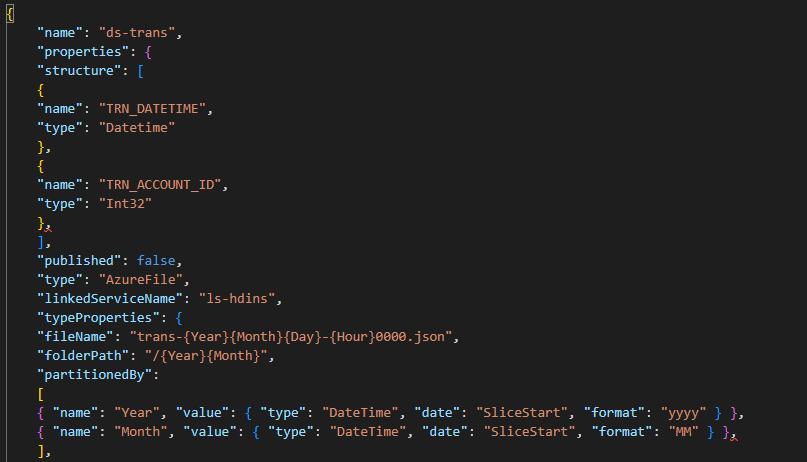
The below file shows the partitioning options for creating the name of the dynamic target folder and the name of the files.
{
"name": "ds-trans",
"properties": {
"structure": [
{
"name": "TRN_DATETIME",
"type": "Datetime"
},
{
"name": "TRN_ACCOUNT_ID",
"type": "Int32"
},
],
"published": false,
"type": "AzureFile",
"linkedServiceName": "ls-hdins",
"typeProperties": {
"fileName": "trans-{Year}{Month}{Day}-{Hour}0000.json",
"folderPath": "/{Year}{Month}",
"partitionedBy":
[ ........ ],
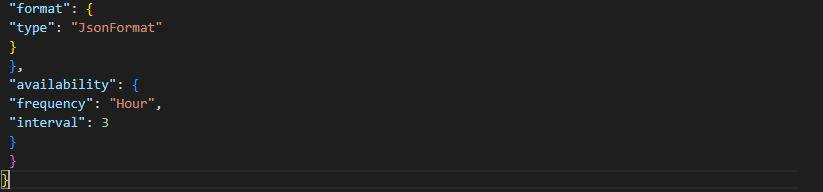
"format": {
"type": "JsonFormat"
}
},
"availability": {
"frequency": "Hour",
"interval": 3
}
}
}
Conclusion
Linked service is nothing but the connection information which was needed for the data factory to connect to the external resources. Azure data factory oracle is used to transfer the data; for transferring the data, we are creating the pipeline for transferring the data from the oracle on-premises database table to the files of the azure data lake.
Recommended Articles
This is a guide to Azure Data Factory Oracle. Here we discuss the introduction, azure data factory oracle integration runtime, type mapping for oracle, and examples. You can also look at the following articles to learn more –

