Updated December 5, 2023
Difference Between KDD and Data Mining
KDD and Data Mining are essential for extracting valuable insights from vast datasets. KDD involves a broader process of identifying patterns, transforming raw data, and interpreting results, encompassing Data Mining as a crucial step. On the other hand, Data Mining specifically focuses on employing algorithms and techniques to unveil meaningful patterns, correlations, and trends within the data. While KDD is the overarching framework, Data Mining is a specialized tool within this process, collectively contributing to extracting actionable knowledge from complex datasets. Understanding their distinctions is vital for optimizing analytical processes and leveraging data-driven decision-making.
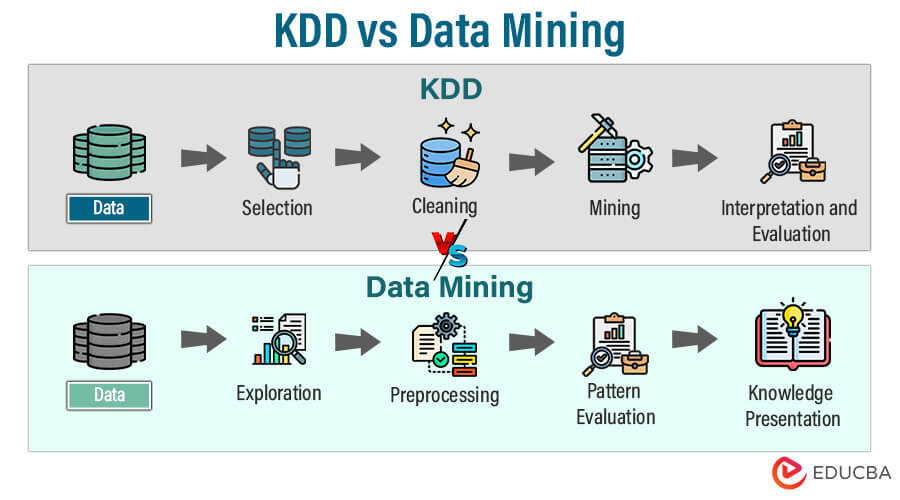
Table of Contents
What is KDD?
KDD, or Knowledge Discovery in Databases, refers to obtaining helpful knowledge or insights from enormous amounts of data. It involves various stages: data selection, preprocessing, transformation, mining, interpretation, and knowledge presentation. The primary objective of KDD is to convert raw data into actionable knowledge, uncovering hidden patterns, trends, and relationships. While data mining is a key component of the KDD process, KDD encompasses a more comprehensive framework that includes steps beyond data mining, such as data preprocessing and interpretation. KDD is crucial in turning data into meaningful and valuable information for decision-making and strategic planning.
KDD Process
The knowledge Discovery in Databases (KDD) process systematically extracts valuable insights and knowledge from large volumes of data. It typically involves the following stages:
1. Data Selection:
- It is essential to locate and gather pertinent information from diverse sources.
- Describe the analysis’s goals and parameters.
2. Data Preprocessing:
- Cleanse and preprocess the data to handle missing values, outliers, and errors.
- Normalize or transform data to ensure consistency and compatibility.
3. Data Transformation:
- Convert and integrate data into a suitable format for analysis.
- Perform aggregation, summarization, or feature engineering to enhance the dataset.
4. Data Mining:
- Use techniques from data mining, such as regression analysis, association rule mining, clustering, and classification.
- The information may be analyzed to find patterns, trends, and relationships.
5. Interpretation/Evaluation:
- Evaluate the results of data mining to ensure their relevance and accuracy.
- Interpret the discovered patterns in the context of the problem domain.
6. Knowledge Presentation:
- Communicate the findings and knowledge in a meaningful way to stakeholders.
- Use visualizations, reports, or other presentation methods for effective communication.
Challenges in KDD
Knowledge Discovery in Databases (KDD) faces several challenges that impact the effectiveness of the process and the quality of the extracted knowledge. Some key challenges include:
- Data Quality: Data quality, including inaccuracies, missing values, and inconsistencies, can lead to reliable results and misinterpretation.
- Data Volume and Complexity: Coping with large volumes of data and managing the complexity of diverse data sources pose challenges for efficient analysis and processing.
- Scalability: As datasets grow, the scalability of algorithms and tools becomes crucial for maintaining reasonable processing times.
- Computational Resources: Adequate computational resources are essential for handling complex algorithms, especially in cases where large-scale data processing is required.
- Privacy Concerns: Ensuring the privacy of sensitive information during the data mining process raises ethical challenges, particularly in healthcare and finance domains.
- Data Integration: Integrating data from various sources with different structures and formats can be challenging, requiring careful handling to ensure consistency.
- Dynamic Nature of Data: Dealing with dynamic, evolving data introduces challenges in maintaining the relevance of models and patterns over time.
- Interpretability: Complex models generated by data mining algorithms may need more interpretability, making it challenging for non-experts to understand and trust the results.
- Domain Knowledge Integration: Incorporating domain knowledge into the analysis process is crucial, but integrating it effectively can be challenging, especially when expertise is dispersed.
- Bias and Fairness: Addressing biases in the data and ensuring fairness in the analysis results is an ongoing challenge, particularly in machine learning applications.
- Costs and Resource Constraints: The financial and human resources required for KDD projects, including skilled personnel and advanced tools, can be substantial.
What is Data Mining?
Data Mining is the process of discovering patterns, relationships, and meaningful insights within vast datasets. Using advanced algorithms and statistical techniques, data mining extracts hidden knowledge, unveiling trends, associations, and anomalies. It involves various classification, clustering, and regression analysis methods to transform raw data into actionable information for informed decision-making. Data mining is integral to knowledge discovery, contributing to fields like business intelligence, healthcare, and finance, empowering organizations to make strategic decisions based on a deeper understanding of their data.
Types of Data Mining
Data mining encompasses various techniques and methods to extract valuable patterns and knowledge from large datasets. The main types of data mining can be categorized as follows:
1. Descriptive Data Mining:
- It entails presenting and summarising a dataset’s key features.
- Techniques include clustering, summarization, and visualization to understand data structures better.
2. Predictive Data Mining:
- Focuses on forecasting future trends or behaviors based on past data.
- Techniques include regression analysis, time-series analysis, and machine learning algorithms for predictive modeling.
3. Prescriptive Data Mining:
- Recommends actions to optimize a particular outcome.
- Utilizes optimization algorithms and decision support systems to provide actionable insights.
4. Classification:
- Assigns predefined labels or categories to instances based on their characteristics.
- It is commonly used in spam detection, image recognition, and customer segmentation.
5. Clustering:
- Group similar data points together according to their characteristics to find natural patterns.
- Beneficial for pattern recognition, anomaly detection, and client segmentation.
6. Association Rule Mining:
- Discovers relationships and associations between variables in large datasets.
- They are utilized extensively in market basket research to find co-occurring item trends.
7. Regression Analysis:
- Predicts numerical results by modeling the link between dependent and independent factors.
- They are applied in forecasting, trend analysis, and risk assessment.
8. Anomaly Detection:
- Identifies unusual patterns or outliers in the data that deviate from the norm.
- Essential for quality assurance, network security, and fraud detection.
Challenges in Data Mining
Data mining, while powerful, faces several challenges that impact its effectiveness and reliability. Key challenges include:
- Data Quality: Poor data quality, with inaccuracies, missing values, or inconsistencies, can lead to unreliable results and misinterpretation.
- Data Quantity: Managing and analyzing large volumes of data poses challenges regarding storage, processing power, and computational efficiency.
- Data Complexity: Dealing with diverse and complex data sources, including unstructured data like text and multimedia, requires sophisticated processing techniques.
- Scalability: Ensuring algorithms and models can handle growing datasets while maintaining reasonable processing times is a continual challenge.
- Privacy Concerns: Balancing the need for data analysis with privacy concerns is crucial, especially in sensitive domains like healthcare and finance.
- Algorithm Selection: Choosing the correct algorithm for a specific task is challenging, and only some algorithms may be suitable for some types.
- Interpretability: Complex models generated by some data mining algorithms may need more interpretability, making it easier for non-experts to understand the results.
- Computational Resources: Resource-intensive algorithms may require substantial computational power and memory, posing challenges for organizations with limited resources.
- Dynamic Data: Handling evolving data requires continuous adaptation of models to maintain their relevance and accuracy.
- Bias and Fairness: Addressing biases in data and ensuring fairness in algorithmic outcomes is a growing concern, especially in applications involving decision-making.
- Ethical Considerations: Ethical issues, such as the responsible use of data, consent, and the potential for unintended consequences, need careful consideration.
- Domain Expertise: Integrating domain knowledge is crucial in data mining, but it is challenging to incorporate diverse expertise
Comparative Table- KDD vs. Data Mining
Now, let’s examine the comparative distinctions between User KDD vs Data Mining.
| Section | KDD | Data Mining |
| Scope | The broader process includes data mining as a step. | A specific process within KDD focused on data analysis. |
| Definition | Comprehensive process of knowledge extraction. | A specific technique for discovering patterns in data. |
| Stages | Includes data selection, preprocessing, transformation, data mining, interpretation, and knowledge presentation. | Primarily involves data mining techniques. |
| Objective | Extract actionable knowledge from large datasets. | Discover patterns, associations, and trends in data. |
| Components | Encompasses a range of data processing steps. | Primarily focused on applying algorithms to data. |
| Integration | Integrates data mining as one component of the overall process. | Represents a key stage within the broader KDD process. |
| Application | Used for comprehensive knowledge extraction in various domains. | Applied to specific tasks such as classification, clustering, and association rule mining. |
| Iterative Process | Yes, with feedback loops between stages for refinement. | Yes, especially within the data mining stage for model improvement. |
| Emphasis on Patterns | Considers patterns, trends, and relationships in data. | Specifically, it focuses on uncovering patterns in datasets. |
| Example Usage | Business intelligence, healthcare analytics, fraud detection. | Customer segmentation, predictive modeling, anomaly detection. |
KDD vs Data Mining- which one should you choose?
The choice between Knowledge Discovery in Databases (KDD) and Data Mining depends on your specific goals, the nature of your data, and the level of detail and control you need in the analysis process. Here are some considerations to help you decide:
Choose KDD if:
- Comprehensive Analysis: If you need a holistic approach that covers data selection, preprocessing, transformation, mining, interpretation, and presentation, KDD is the most suitable choice.
- Decision Support Systems: If you aim to support decision-making processes by providing a structured framework for knowledge extraction.
- Complex Data Processing: When dealing with diverse and complex datasets that require thorough preprocessing and interpretation beyond the scope of data mining.
- Long-Term Knowledge Management: If you want to create a knowledge management system that involves continuous improvement and adaptation.
Choose Data Mining if:
- Focused Pattern Extraction: When your primary goal is to uncover specific patterns, relationships, or trends within a dataset, you do not require the broader context of KDD.
- Algorithmic Insight: If you want to apply specific algorithms and techniques for classification, clustering, or association rule mining.
- Targeted Analysis: When your interest lies in a particular aspect of the data mining process, you don’t need to address the entire knowledge discovery lifecycle.
- Efficiency and Specificity: If you have limited resources or time and need a more targeted approach to uncover patterns within the data.
Conclusion
The synergy between Knowledge Discovery in Databases (KDD) and Data Mining unlocks unparalleled insights from vast datasets. KDD’s holistic approach, encompassing data selection, preprocessing, mining, interpretation, and presentation, provides a comprehensive framework for knowledge extraction. As a specialized technique within KDD, Data Mining excels in targeted pattern extraction using advanced algorithms. The choice depends on the specific goals, dataset characteristics, and the depth of analysis required. Leveraging KDD vs Data Mining ensures a nuanced understanding of data, fostering informed decision-making and strategic advancements across diverse domains.
Recommended Articles
We hope that this EDUCBA information on “KDD vs Data Mining” was beneficial to you. You can view EDUCBA’s recommended articles for more information,
