What is DynamoDB Scan?
DynamoDB Scan is an operation in Amazon DynamoDB. This NoSQL database service retrieves one or more items along with their attributes by scanning through every object in a specified table or secondary index. This operation fetches data without determining a particular key value, making it suitable for scenarios where the entire dataset must be examined or filtered based on specified conditions using the’ Filter Expression’ parameter. However, it’s important to note that scanning large tables can be resource-intensive and may impact performance, so it should be used judiciously, and alternative approaches like querying should be considered when possible.
Use the following CLI command to run a Scan operation.
aws dynamodb Scan --table_name My_Table
Table of Contents
- What is DynamoDB Scan?
- When to Use DynamoDB Scan?
- How does DynamoDB Scans Work?
- Scan Filtering and Expression Attribute Values (EAV)
- Pagination with DynamoDB Scan
- DynamoDB Scan Examples
- How fast is the DynamoDB scan?
- Parallel Scan in DynamoDB
- When to Avoid DynamoDB Scan?
- Best Practices for Using Scans
- Pitfalls and Limitations
- Alternatives to Scan
Key Takeaways
- DynamoDB Scan examines all items in a table.
- Less efficient than targeted queries for large datasets.
- Filters results based on specified criteria.
- Resource-intensive, impacting performance and costs.
- Ideal for tables lacking a defined structure.
- Optimize scans and consider alternatives for efficient data retrieval in DynamoDB.
When to Use DynamoDB Scan?
Developers often use scans when a table needs a defined structure and a comprehensive examination of its content is necessary. You can use DynamoDB Scan in the following scenarios.
- Table-wide Analysis: When you must analyze all items in a table without specifying a particular key.
- Data Exploration: Ideal for tables lacking a predictable structure, allowing comprehensive content exploration.
- They limited Data: In relatively small datasets where scan performance is acceptable.
- One-Time Operations: For occasional or one-time operations where efficiency is not a primary concern.
However, be cautious, as scans can be resource-intensive. You can also consider alternatives like queries for optimal performance.
How does DynamoDB Scans Work?
DynamoDB Scans examines every item in a table, evaluates each item against specified filter conditions, and returns the matching results. Here’s a step-by-step overview.
- Sequential Examination: Scans go through every item in the table, traversing the entire dataset sequentially.
- Filtering: You can apply filter conditions to refine the results, allowing you to retrieve items that meet specific criteria.
- Provisioned Throughput: Scans consume read capacity units for the data read, and the provisioned throughput affects the scan performance.
- Page Size: Results are paginated, and a limit is set on the number of items returned per page. Pagination tokens are used to navigate through multiple result pages.
- Full Table Scan: Unlike queries that target specific keys, scans read the entire table, making them less efficient for large datasets.
Scan Filtering and Expression Attribute Values (EAV)
DynamoDB Scan Filtering is a mechanism that allows you to retrieve items from a table selectively based on specified conditions. It involves using two key parameters: Filter Expression and Expression Attribute Values.
Scan Filtering
Allows you to narrow down the results of a DynamoDB Scan operation based on specified conditions. It works by applying a filtering expression to the items in the table.
For Example
Suppose you have a table with items representing books and want to scan for books with a specific genre.
import boto3
dynamodb = boto3.client('dynamodb')
params = {
'TableName': 'BooksTable',
'FilterExpression': 'genre = :desired_genre',
'ExpressionAttributeValues': {':desired_genre': {'S': 'Science Fiction'}}
}
response = dynamodb.scan(**params)
print(response['Items'])In this example, the FilterExpression is set to look for items where the ‘genre’ attribute equals ‘Science Fiction.’ The ExpressionAttributeValues parameter provides the actual values for the placeholders in the expression.
Expression Attribute Values (EAV)
Allows you to use named placeholders in your expressions, improving the readability of your code and making it easier to reuse expressions.
For Example
Continuing with the book example, suppose you want to scan for books with a particular author.
params = {
'TableName': 'BooksTable',
'FilterExpression': '#author = :desired_author',
'ExpressionAttributeNames': {'#author': 'author'},
'ExpressionAttributeValues': {':desired_author': {'S': 'Isaac Asimov'}}
}
response = dynamodb.scan(**params)
print(response['Items'])In the above example, Expression Attribute Names defines the placeholder #author, representing the ‘author’ attribute in the filtering expression. This improves code clarity and allows for easy modification of attribute names without changing the expression.
Combined Example
Let’s combine Scan Filtering and EAV for a more complex query.
params = {
'TableName': 'BooksTable',
'FilterExpression': '#genre = :desired_genre AND #author = :desired_author',
'ExpressionAttributeNames': {'#genre': 'genre', '#author': 'author'},
'ExpressionAttributeValues': {':desired_genre': {'S': 'Science Fiction'}, ':desired_author': {'S': 'Isaac Asimov'}}
}
response = dynamodb.scan(**params)
print(response['Items'])This example scans for books of the Science Fiction genre written by ‘Isaac Asimov.’
Pagination with DynamoDB Scan
Pagination with DynamoDB Scan involves breaking down the Scan results into manageable chunks or pages, as the entire result set may be too significant to retrieve in a single request. This is typically achieved using the Limit parameter to specify the number of items to retrieve per page and the Exclusive Start Key parameter to determine where the next page should start.
For Example
Suppose you have a DynamoDB table named “Users” and want to retrieve all users, ten at a time, and navigate through the pages. Here’s how you can implement pagination:
import boto3
dynamodb = boto3.client('dynamodb')
# Initial Scan request without ExclusiveStartKey
initial_params = {
'TableName': 'Users',
'Limit': 10,
}
response = dynamodb.scan(**initial_params)
print("Page 1:", response['Items'])
# Subsequent requests using ExclusiveStartKey
while 'LastEvaluatedKey' in response:
exclusive_start_key = response['LastEvaluatedKey']
params = {
'TableName': 'Users',
'Limit': 10,
'ExclusiveStartKey': exclusive_start_key,
}
response = dynamodb.scan(**params)
print(f"Next Page starting from {exclusive_start_key}:", response['Items'])In the above example-
- The initial scan request (initial_params) fetches the first page of 10 items.
- More items must be retrieved if the response contains a Last Evaluated Key. Subsequent requests are made using this key to continue fetching the next page.
This process continues until no Last Evaluated Key is in the response, indicating that all items have been retrieved.
DynamoDB Scan Examples
In DynamoDB, the Scan operation reads all the items in a table. However, it is essential to note that Scan operations can be inefficient and costly, especially on large tables, as they read every item.
Here are a couple of examples of using the AWS SDK for Python (Boto3) to perform a scan operation in DynamoDB.
1. Basic Scan
import boto3
# Create a DynamoDB resource
dynamodb = boto3.resource('dynamodb')
# Specify the table name
table_name = 'YourTableName'
# Get the table
table = dynamodb.Table(table_name)
# Perform a basic Scan operation
response = table.scan()
# Print the items
items = response['Items']
for item in items:
print(item)2. Filtering results
import boto3
# Create a DynamoDB resource
dynamodb = boto3.resource('dynamodb')
# Specify the table name
table_name = 'YourTableName'
# Get the table
table = dynamodb.Table(table_name)
# Define a filter expression
filter_expression = Key('AttributeName').eq('DesiredValue')
# Perform a Scan operation with a filter expression
response = table.scan(FilterExpression=filter_expression)
# Print the items that match the filter
items = response['Items']
for item in items:
print(item)How fast is the DynamoDB scan?
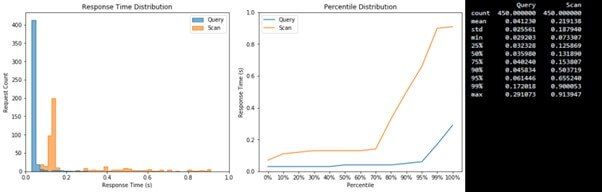
DynamoDB Scan isn’t speedy; it checks the whole table (O(n) complexity). For quick data fetching, prefer Query or Get operations. Scans are less efficient, especially for large tables; they may use up the provisioned throughput in one go.
To minimize impact-
- Reduce Page Size- Set a smaller page size since a Scan reads a whole page (default 1 MB).
- Isolate Scan Operations- Avoid impacting critical traffic; scan a separate table and rotate traffic periodically.
Parallel Scan in DynamoDB
Parallel Scan in DynamoDB is a method to speed up large tables or index scans by dividing them into segments that are processed simultaneously. It enhances performance through parallelism, using multiple threads or processes.
DynamoDB’s Parallel Scanning API facilitates the implementation, but careful provisioned throughput management is essential for optimal results. This feature is handy for efficiently scanning through large volumes of data.
To execute a parallel scan, every worker initiates its Scan request with specific parameters.
- Segment: Designates a segment scanned by a particular worker. Each worker should use a distinct value for each Segment.
- TotalSegments: This represents the overall count of segments for the parallel Scan. This value should align with the number of workers employed by your application.
The subsequent diagram illustrates the process of a multithreaded application conducting a parallel Scan with three degrees of parallelism.
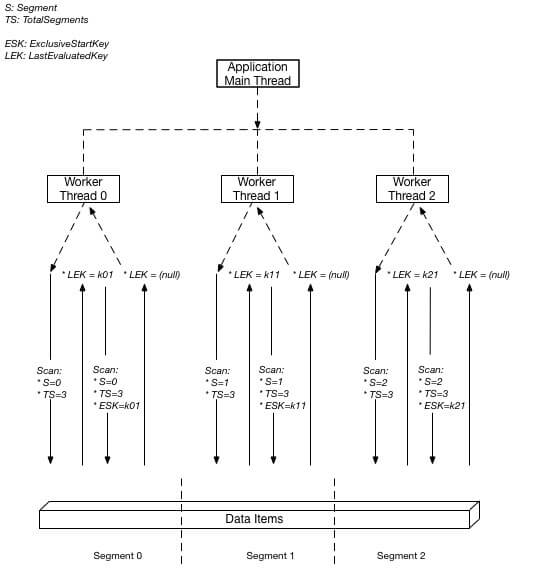
Source- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Scan.html#Scan.ParallelScan
When to Avoid DynamoDB Scan?
Avoid using DynamoDB Scan in specific scenarios due to its potential impact on performance, cost, and efficiency. Here are situations when you should consider alternatives to DynamoDB Scan.
- Large Tables: Scanning large tables can be resource-intensive and time-consuming. Consider using Query or Get operations instead, especially when targeting specific items.
- Frequent Access: If your application requires regular data retrieval, Scan operations lead to high costs and increased read capacity consumption. Opt for queries that target specific keys for more efficient access.
- Filtering Many Results: Avoid using Scan with extensive filtering conditions that exclude many results. It can result in scanning a significant portion of the table, affecting performance and costs.
- Provisioned Throughput Concerns: Scans consume read capacity based on the amount of data read. For tables with provisioned throughput, excessive scanning can quickly finish available capacity. Use scans judiciously and monitor provisioned throughput.
- Real-time Data Needs: If your application requires real-time or low-latency data access, consider other operations like Query, which are more tailored to efficient data retrieval.
- Unindexed Attributes: Scans on unindexed attributes can be less efficient. Design your table schema with indexes that align with your query patterns.
- Mission-Critical Tables: Avoid performing Scans on tables that handle mission-critical traffic, as it may impact the performance of essential operations. Isolate scans to separate tables if necessary.
Best Practices for Using Scans
Consider the following best practices to ensure better results and performance.
- Avoid Big Tables: Don’t use scans on large tables; they can be slow and use many resources.
- Filter Smartly: If you have to scan, use filters carefully. Avoid scanning if you’re only interested in a small part of the data.
- Mind Your Costs: Scans consume read capacity, which can get expensive. Be mindful of your provisioned throughput.
- Prefer Queries: Use queries instead of scans. They are often faster and more efficient for fetching specific data.
- Use Indexes: If you have predictable query patterns, set up indexes. They can significantly speed up your scans.
Pitfalls and Limitations
Pitfalls and limitations of DynamoDB Scan include:
- Performance Impact: Scans can be slow and resource-intensive, especially on large tables, impacting the overall performance of your application.
- Provisioned Throughput Consumption: Scans consume read capacity units based on the amount of data read. This can lead to high costs and rapid consumption of provisioned throughput.
- No Sorting: Scan results are not sorted, so additional processing may be required to organize the data.
- Unpredictable Timing: It takes unexpected time to complete a scan, making it challenging to estimate when the operation will finish.
- Limited Filtering Efficiency: Filtering results within a scan is less efficient than using Query operations, especially when dealing with large datasets.
- Full Table Read: Scans read the entire table, making them less suitable for targeted retrievals than queries.
- No Strong Consistency: Scan operations do not support strong consistency, meaning the results may include recently updated data.
- Problems with Paginating Large Result Sets: Paginating through large result sets can be complex and require careful LastEvaluatedKey handling.
- Not Suitable for Real-Time Needs: Scans are not optimal for real-time or low-latency data retrieval; consider other operations for such requirements.
Understanding these pitfalls and limitations is crucial for making informed decisions about when to use DynamoDB Scan and when to explore alternative approaches for data retrieval in DynamoDB.
Alternatives to Scan
The alternatives below provide more targeted and efficient ways to retrieve data in DynamoDB compared to using scans, especially when dealing with large datasets.
- Query Operation: Efficient for retrieving items based on specific vital conditions. It is ideal when you want to fetch objects with a particular attribute value or critical condition.
Source- https://res.cloudinary.com/
- GetItem Operation: Retrieves a single item based on its primary key, offering high efficiency. It is suitable when you know the item’s primary key you want to retrieve.
- Global Secondary Index (GSI): Enables efficient querying on attributes other than the primary key. Useful for scenarios where your queries involve non-key attributes.
- BatchGetItem Operation: Retrieves multiple items in a single request, reducing the number of round trips. Efficient for fetching various objects based on their primary keys.
Conclusion
DynamoDB Scan is a powerful yet resource-intensive operation. While it allows comprehensive data retrieval, its O(n) computational complexity and potential impact on performance and costs make it less efficient for large datasets. Best practices involve judicious use, consideration of alternatives like queries, and careful provisioned throughput management.
FAQ’s
Q1. Why is DynamoDB Scan considered less efficient than other operations?
Answer: DynamoDB Scan reads the entire table, introducing an O(n) computational complexity. This exhaustive process can be resource-intensive and impact performance and costs, making it less efficient, especially for large datasets.
Q2. When should I use DynamoDB Scan, and when should I avoid it?
Answer: Use Scan to analyze the entire table or lack a well-defined query pattern. Avoid it for large tables, frequent data retrieval, and real-time needs. Consider alternatives like Query for more targeted and efficient data retrieval.
Q3. How can I optimize the performance of DynamoDB Scan?
Answer: To optimize DynamoDB Scan, reduce page size to minimize impact, perform scans on non-mission-critical tables, and, if applicable, implement parallel scans. Additionally, carefully manage provisioned throughput and use filters wisely to refine scan results.
Recommended Articles
We hope this EDUCBA information on the “Dynamodb scan” benefited you. You can view EDUCBA’s recommended articles for more information.


{kind=link}