Introduction to Difflib Module in Python
The Difflib module in Python serves as a potent tool for comparing and identifying differences between sequences, primarily tailored for text data. It offers various functions and classes that facilitate multiple types of sequence comparisons, enabling the generation of detailed difference reports. Whether you’re comparing strings, lists, or other sequences, Difflib provides efficient and accurate methods for pinpointing additions, deletions, modifications, and common subsequences between two sequences.
One of the module’s standout features involves its capacity to compute a “delta” between sequences, a concise representation of their disparities. This delta proves invaluable for tasks such as version control, code review, text analysis, data cleaning, and more. Difflib finds extensive use in applications like code versioning, change tracking, and natural language processing (NLP), where the primary objective is to analyze and highlight sequence differences. The Difflib module in Python is essential for developers performing code diffing, data scientists managing data records, and anyone working on text analysis and comparison tasks. It streamlines your work by providing valuable insights into the differences and similarities between sequences. This makes it crucial for tasks like code version control, code review, and content management.
Table Of Content
- Introduction
- Why compare Sequences?
- Classes of Difflib
- 2. SequenceMatcher Class
- 3. What is HtmlDiff in difflib?
Why compare Sequences?
Difflib, a Python module, facilitates the comparison of sequences, particularly strings, and allows for identifying differences between them. Several compelling reasons support the use of Difflib for sequence comparison. Firstly, it proves invaluable in text processing tasks, such as document comparison, version control, and plagiarism detection, as it enables precise identification of text alterations, additions, deletions, or changes. Secondly, In the field of developing software, Difflib serves as an essential tool for code comparison, empowering developers to closely examine code changes in version control systems or collaborative coding efforts.
Moreover, it plays a critical role in data preprocessing, aiding in the cleaning and standardizing datasets by highlighting discrepancies and variations in data records. Additionally, Difflib can generate patches for updating files or texts, align sequences for pattern matching, and form the foundation of version control systems like Git. Difflib is a flexible and essential tool for comparing sequences since it basically provides a wide range of applications in text analysis, coding, data management, and other areas.
Classes of Difflib
The Difflib module has various classes and functions for sequence comparisons. Difflib has three types of classes. The given items are as follows below.
1. Differ class
Differ class does line-by-line comparison of two sequences. This class creates “delta” output, which shows differences between the input sequences, replacements, deletions, insertions, etc. The differ class compares sequences and produces human-readable difference reports.
For example, the compare method takes two sequences as input and returns strings that explain whether a line is common, added, or deleted. Each input string calls the splitlines method to split into a list of lines. Use the join method to join the comparison results with a newline character (\n).
from difflib import Differ
def compare_strings(str1, str2):
d = Differ()
result = d.compare(str1.splitlines(), str2.splitlines())
return '\n'.join(result)
str1 = "Hello\nWorld\nPython"
str2 = "Hello\nPython\nWorld"
print(compare_strings(str1, str2))Output:
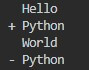
In this example:
- Mark the same lines in both sequences with a space (”).
- Mark lines with a minus sign (‘-‘) that appear only in the first sequence to indicate deletion.
- Mark lines with a plus sign (‘+’) that appear only in the second sequence, indicating additions.
The Differ class is used for line-by-line comparison of sequences. It provides highlighted locations for added and removed lines. It produces a “delta” output with a list of strings. These strings represent the distinctions in the input sequences. Every line of delta output has one of the following characters, which says the type of change.
- ‘?’: It means intraline difference in the input sequences.
- ”: (space) – It means lines are identical in both sequences.
- ‘+’: It means line is present only in the second sequence (added).
- ‘-‘ means the line is present only in the first sequence (deleted).
How to use the Differ class for performing a line-by-line comparison
It is easy to perform Line-by-Line comparisons using the Differ class. You need to follow the given steps.
- Import the difflib module, which contains the Differ class.
- Create a Differ object.
- Prepare the input sequences or read the lines from two text files.
- Now, compare the input sequences.
- Then, the delta output, which shows the differences between the input sequences, is displayed. Each line has either ‘, “-,’ ‘+,’ or ‘?’
For example, we compare given texts line by line.
# Import necessary module
import difflib
# Set up input sequences
text1 = ["This is line 1.", "This is line 2.", "This is line 3."]
text2 = ["This is line 1.", "This is the updated line 2.", "This is line 3."]
# Create a Differ object
comparator = difflib.Differ()
# Compare input sequences
delta_result = list(comparator.compare(text1, text2))
# Display the delta output
for line in delta_result:
print("\n")
print(line, end="")Output:
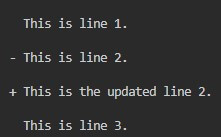
In the above example, the comparator creates an instance of the Differ class. The result of delta_result is a list of strings representing differences between two sequences. We iterate through delta_result and print each line of delta output.
Methods and Attributes of Differ Class
There are various methods and attributes of the Differ class. Some of them are given below.
1. The Compare Method
The compare() method generates a difference report (delta – a sequence of lines) between two sequences.
Example-1: We generate the differences between the two strings. The differences are then iterated through, and each difference is printed.
# Import necessary module
from difflib import Differ
# Assign values
text1 = 'Educba'
text2 = 'educba!'
# Compare values
for item in Differ().compare(text1, text2):
print(item)Output:
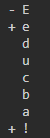
In this example code, the character ‘E’ is deleted, and ‘e’ and ‘!’ are added in the second string.
Now, see another example with more input strings.
Example-2: This time, we compare between a list (`list1`) and a string (`text2`). We generate the differences between the list and the string. The differences are then iterated through, and each difference is printed.
# Import necessary module
from difflib import Differ
# Assign values
list1 = ['Educba', 'is', 'awesome!']
text2 = 'educba!'
# Compare values
for item in Differ().compare(list1, text2):
print(item)Output:
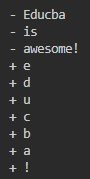
In this example, in the second string, “Educba,” “is,” and “awesome!” are deleted. Character’ e,’ ‘d’, ‘u,’ ‘c,’ ‘b,’ ‘a’, ‘!’ is added.
2. The ndiff Method
You can also make the above comparison using the ndiff () method, but if lists are passed, the elements of the lists are compared first.
Note that compare() and ndiff() are similar so that you can see the example used for the compare() method. You can simply substitute “ndif” instead of “compare” and get the same output.
3. Context Diff Method
This context_diff() method is a convenient way to display only the lines that have moved along certain lines of context. The style has seen before/after improvements. The number of background lines is set to n, which is set to three by default.
Example-1: context_diff function from the difflib module generates the difference between two strings in the context format. The system prints each difference along with the surrounding context to highlight the added, deleted, and modified lines.
# Import necessary module
import difflib
# Assign values
text1 = 'Educba'
text2 = 'educba!'
# Compare values
for item in difflib.context_diff(text1, text2):
print(item)Output:
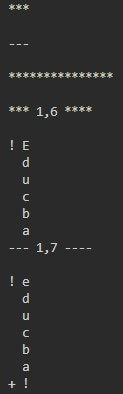
In the above example,
- Lines prefixed with ‘+’ indicate lines only in the second sequence.
- Lines prefixed with ‘!’ indicate lines where the content differs between the two sequences.
Example-2: In this code example, the context_diff generates the difference between list and string in the context format. Printing each difference provides a more relevant view of the discrepancies between list and string.
# Import necessary module
import difflib
# Assign values
list1 = ['Educba', 'is', 'awesome!']
text2 = 'educba!'
# Compare values
for item in difflib.context_diff(list1, text2):
print(item)Output:
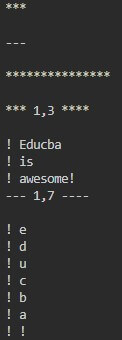
It shows you added, removed, and modified elements and the surrounding context.
- Lines prefixed with” (space) indicate lines that are the same in both sequences.
- Lines prefixed with ‘-‘ indicate lines only in the first sequence (list1).
- Lines prefixed with ‘+’ indicate lines only in the second sequence (text2).
- Lines prefixed with ‘!’ indicate lines where the content differs between the two sequences.
2. SequenceMatcher Class
The SequenceMatcher class provides a flexible way to perform detailed sequence matching. The SequenceMatcher class is used for matching sequence pairs of any sort. You can use the SequenceMatcher class in various applications like document comparison, plagiarism detection, code review, DNA sequence alignment, and natural language processing.
Functions of SequenceMatcher class
This class has various functions discussed below.
1. The Ratio Method
The ratio() method returns the ratio between two arguments passed. The similarity check formula is 2*x/y, where x is the number of similar matches and y is the total number of elements in both sequences.
Example-1:
# Import necessary module
import difflib
# Assign values
text1 = ['e', 'd', 'u', 'c', 'b', 'a']
text2 = 'educba'
# Compare
print(difflib.SequenceMatcher(None, text1, text2).ratio())Output:
![]()
In the above example, first, we import the difflib module, which provides tools to compare sequences. Text1 contains a list of characters, and text2 contains a string. Then we have difflib.SequenceMatcher object with None as the first argument (i.e., the default comparison method). We have also provided text1 and text2 as arguments. The ratio() method is called on the SequenceMatcher object. This ratio() method returns a similarity ratio ranging from 0.0 (no match) to 1.0 (perfect match, i.e., identical sequences). Finally, we printed this ratio score.
Note that in the above code, text1 and text2 have identical sequences, so the output is 1.
Example-2:
# Import necessary module
import difflib
# Assign values
text1 = 'Educba'
text2 = 'Educba is awesome!'
# Compare
print(difflib.SequenceMatcher(None, text1, text2).ratio())Output:
![]()
In the above code, we have used two strings for the ratio() method. Since text1 is matching text2, text2 is not matching text1 exactly. Hence, the output is 0.5.
Example-3:
# Import necessary module
import difflib
# Assign values
text1 = 'educba'
text2 = 'EDUCBA'
# Compare
print(difflib.SequenceMatcher(None, text1, text2).ratio())Output:
![]()
In the above code, though text1 and text2 have the same value, the cases are different. Text1 is lowercase, and text2 is uppercase. Because it is case-sensitive, the output is 0.0, which does not match.
2. The get_matching_blocks Method
The get_matching_blocks() method returns a list of triples describing matching subsequences. Every triple is the format of (i, j, n). It means a[i:i+n] == b[j:j+n].
Example-1:
# Import necessary module
import difflib
# Assign values
text1 = 'Educba'
text2 = 'Educba is awesome!'
# Compare
matches = difflib.SequenceMatcher(
None, text1, text2).get_matching_blocks()
for match in matches:
print(text1[match.a:match.a + match.size])Output:
![]()
In the above code example, the get_matching_blocks() method is called on the SequenceMatcher object. This method returns a list of namedtuples representing matching blocks. The output will be the substrings of text1 that match with parts of text2. Each line printed in the loop represents a matching block between the two strings.
Note that the code only prints the matching substrings from text1. This specific example will print “Educba” since it is a common substring between the two strings.
Consider another example with case-sensitive strings.
Example-2:
# Import necessary module
import difflib
# Assign values
text1 = 'educba'
text2 = 'EDUCBA'
# Compare
matches = difflib.SequenceMatcher(
None, text1, text2).get_matching_blocks()
for match in matches:
print(text1[match.a:match.a + match.size])Output:
![]()
There will not be any output because there is nothing to match due to case-sensitive cases.
3. The get_close_matches Method
The get_close_matches() method returns the best character or group of characters in a column.
Example:
# Import necessary module
import difflib
# Assign values
main_string = "CBA4cba"
string_list = ["for", "CbA", "C4c", "cba"]
# Find common strings
print(difflib.get_close_matches(main_string, string_list))Output:
![]()
In the above code example, the get_close_matches() method is called. This function returns a list of the best “good enough” matches in the string list based on similarity. Finally, we print the result, which is a list of close matches to the main string in the provided string list.
3. What is HtmlDiff in difflib?
The HtmlDiff provides a convenient way to generate an HTML side-by-side comparison of two sequences. It is generally used in web applications like versions of documents, in text data, source code file etc. You can use different colors and styles to add, remove, and replace. This generates an HTML table to display two sequences side-by-side with change indicators and line numbers.
For example,
# Import necessary module
import difflib
# Assign values
fruits1 = ["apple", "banana", "cherry"]
fruits2 = ["apple", "blueberry", "grape"]
# Create HtmlDiff object
html_diff = difflib.HtmlDiff()
# Generate comparison table
table_html = html_diff.make_table(fruits1, fruits2)
# Write HTML table to a file
with open("fruits_comparison.html", "w") as output_file:
output_file.write(table_html)In this example, the code uses the difflib module in Python to generate an HTML comparison table between two lists of strings (fruits1 and fruits2). The HtmlDiff class performs the comparison, and it writes the resulting HTML table to a file named “fruits_comparison.html.”
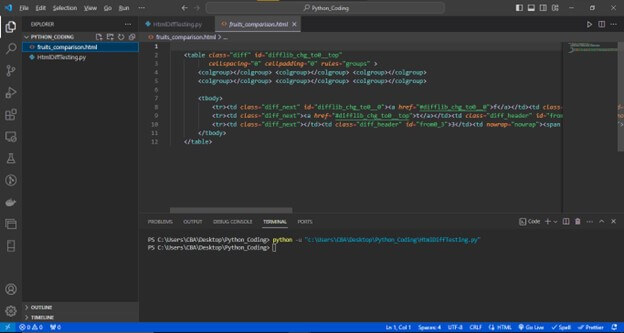
Now, this output file “fruits_comparison.html” will contain an HTML table displaying side-by-side comparisons:
Before Running the Code :
After running the code:
There are other examples of HtmlDiff in Web Applications. Some of them are discussed below.
1. Jupyter Notebook
You can use HtmlDiff in Jupyter Notebook to display comparison tables using IPython.display.
For example,
# Import necessary module
from IPython.core.display import display, HTML
import difflib
# Assign values
my_fruits1 = ["apple", "banana", "cherry"]
my_fruits2 = ["apple", "blueberry", "grape"]
# Create HtmlDiff object
html_diff = difflib.HtmlDiff()
# Generate comparison table
table_html = html_diff.make_table(my_fruits1, my_fruits2)
# Display HTML table
display(HTML(table_html))Output:

In the above example, we have used the IPython.core.display module to display an HTML comparison table between two lists of strings (my_fruits1 and my_fruits2). The HtmlDiff class from the difflib module performs the comparison, and the IPython environment displays the resulting HTML table.
2. Flask web application
Use HtmlDiff to create an HTML-based comparison table and incorporate it into a template for rendering.
For example,
from flask import Flask, render_template_string
import difflib
app = Flask(__name__)
@app.route("/compare")
def compare():
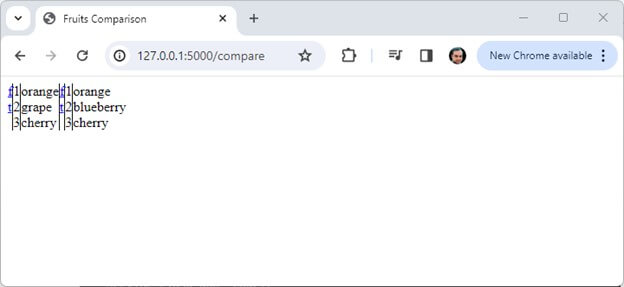
my_fruits1 = ["orange", "grape", "cherry"]
my_fruits2 = ["orange", "blueberry", "cherry"]
html_diff = difflib.HtmlDiff()
comparison_table = html_diff.make_table(my_fruits1, my_fruits2)
template = '''
{{ comparison_table | safe }}
'''
return render_template_string(template, comparison_table=comparison_table)
if __name__ == "__main__":
app.run()Running this script starts a Flask web server, and you can access the comparison results by visiting the “/compare” route in your web browser. Display the differences between the two lists of fruits in an HTML table.
This example creates a Flask web application to compare two lists of fruits and displays the differences in an HTML table. The difflib.HtmlDiff class generates the comparison table. The render_template_string function from Flask renders the HTML template with the comparison results.
Output:
Similarly, you can use HtmlDiff in the Django web application too
Application/uses of Difflib
Difflib has various applications and uses in Python. For example, you can compare the contents of the two text files. Consider these two files: the original.txt file and the modified.txt file. These files contain text content. We will place these files in the same folder and execute them on Jupyter Notebook.
import difflib
original_lines = open("original.txt", "r").readlines()
modified_lines = open("modified.txt", "r").readlines()
char_junk_filter = lambda x: x in [",", ".", "-", "'"]
difference = difflib.Differ(charjunk=char_junk_filter)
for line in difference.compare(original_lines, modified_lines):
print(line, end="")Output:

As you can see, it does a line-by-line comparison. Line no.1 has been completely removed from the modified.txt file, and a new line has been added. There is no change in Line 2. In line 3, only one word, “unacceptable,” was removed, and “not acceptable” was added. Line 4 is still the same. Line 5 has been completely redesigned. There are no changes in lines 6, 7, and 8. In line 9, the words “bad” have been removed, and “not” and “good” have been added. Similarly, line 10 has also been modified.
Similarly, you can also generate its HTML table. For example,
import difflib
from IPython import display
original_lines = open("original.txt", "r").readlines()
modified_lines = open("modified.txt", "r").readlines()
html_diff = difflib.HtmlDiff(tabsize=2)
with open("comparison_output.html", "w") as output_file:
html_table = html_diff.make_table(fromlines=original_lines, tolines=modified_lines, fromdesc="Original", todesc="Modified")
output_file.write(html_table)
display.HTML(open("comparison_output.html", "r").read())Output:
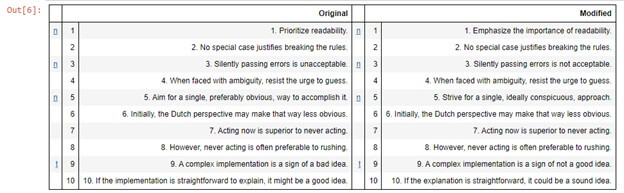
The changes are shown in tagged lines in the given comparison HTML table.
There are various other functionalities of difflib, some of which are:
- You can identify differences and similarities between two sequences (using SequenceMatcher).
- You can calculate the similarity ratio between two sequences (using SequenceMatcher).
- You can compare strings (using SequenceMatcher), ignoring junk characters.
- You can implement the necessary operations (insertion, deletion, replacement) to transform one sequence into another (using SequenceMatcher).
- You can highlight the differences between two lists of strings and file contents (using diff).
- You can generate HTML of differences between files (HtmlDiff).
Conclusion
In conclusion, you can compare sequences in Python using the “difflib” module. Whether you need to analyze the differences between two strings, compare file contents, and perform code versioning. The classes and functions of the “difflib” module, like Differ and SequenceMatcher, make it easy to identify matching subsequences and generate detailed difference reports.
The Differ class provides a line-by-line comparison for human-readable delta output that highlights added, deleted, and common lines. On the other hand, the SequenceMatcher class provides detailed sequence matching, calculating similarity ratios, identifying matching blocks, etc. You can use “difflib” in various applications like document comparison, code review, natural language processing (NLP), etc.
FAQs (Frequently Asked Questions)
Q1: Can you use the difflib module to compare complex data structures like nested lists and dictionaries in Python?
Answer: No. While difflib is excellent for comparing sequences like strings and lists. However, it may not provide good results for complex data structures like nested lists and dictionaries. You can use specialized libraries that tailor specific and complex data structures in Python.
Q2: How do you ignore whitespaces in difflib?
Answer: You can use strip() method to remove whitespaces from input strings. You can define a function to do this. For example,
import re
def remove_whitespace(line):
return re.sub("\s+", " ", line.strip())Now, you can use this method to remove whitespaces from given strings.
Q3: Can you use difflib to compare sequences across different file formats in Python?
Answer: Difflib is used to compare sequences of text-based data. It is excellent to use in strings and text files. It may require more consideration to compare sequences in different file formats (such as binary formats, JSON, and CSV). You may need to search for format-specific libraries for more robust comparisons.
Recommended Articles
We hope that this EDUCBA information on “Difflib Python” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

