Introduction
Extracting data from PDFs for analysis or processing can often be challenging in today’s digital age, as PDF (Portable Document Format) files have become essential for storing and sharing documents. Various industries and sectors widely use PDFs for creating reports, invoices, research papers, or forms. Thankfully, Python provides many powerful libraries and tools to efficiently extract data from PDF files. Python offers versatile solutions for various PDF data extraction tasks, from extracting plain text to parsing complex tables and layouts.
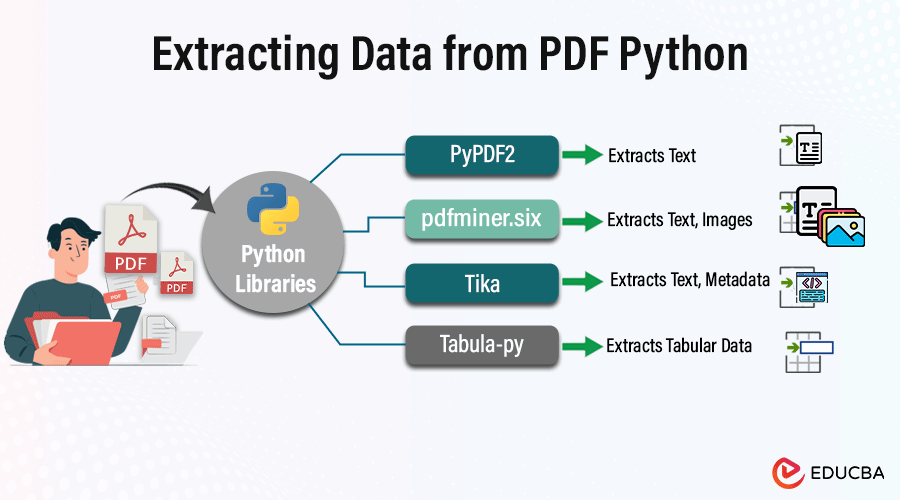
Table of Contents
Choosing the Right Python Libraries
Several libraries are available when extracting data from PDF files using Python, each with its features and capabilities.
PyPDF2
- Features: PyPDF2 is a Python library for reading and manipulating PDF files. It provides functionalities for extracting text and merging or splitting PDFs.
- Suitability: PyPDF2 is a good choice for basic text extraction tasks where the PDF structure is straightforward and doesn’t involve complex layouts or tables.
- Example: Extracting text from a simple PDF document can be easily achieved using PyPDF2.
Pdfminer.six
- Features: pdfminer.six is a more advanced PDF processing library that provides tools for extracting text, images, and other elements from PDF files. It offers more control over the extraction process compared to PyPDF2.
- Suitability: If you need more flexibility and control over text extraction, especially for PDFs with complex layouts or non-standard fonts, pdfminer.six is a suitable choice.
- Example: Extracting text with precise positioning information or extracting text from scanned documents are scenarios where pdfminer.six shines.
Tika
- Features: Tika is a toolkit that provides Python bindings to Apache Tika, a robust content analysis toolkit. It supports text, metadata, and structured content extraction from various file formats, including PDF.
- Suitability: Tika is a versatile option for extracting text and metadata from PDF files and other formats, such as DOCX and XLSX.
- Example: Tika makes extracting text content and metadata (such as author, creation date, etc.) from PDF documents accessible.
Tabula-py
- Features: Tabula-py, designed explicitly to extract tabular data from PDF files. It uses algorithms to detect and extract tables, making it ideal for dealing with PDFs containing structured data in table format.
- Suitability: If your main task involves extracting tabular data from PDFs, such as financial reports, research tables, or data tables, Tabula-py is the go-to library.
- Example: Tabula-py efficiently extracts tables from PDFs with complex layouts or tables spanning multiple pages.
Basic Text Extraction
Let’s explore how to extract text from a PDF file using PyPDF2 and discuss how to handle different encodings.
Example with PyPDF2
Required Python Library:
pip install PyPDF2Code:
import PyPDF2
pdf_file = open("Text Extraction.pdf", "rb")
pdf_reader = PyPDF2.PdfReader(pdf_file)
full_text = ""
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
text = page.extract_text()
full_text += text
print(full_text)
pdf_file.close()Output:
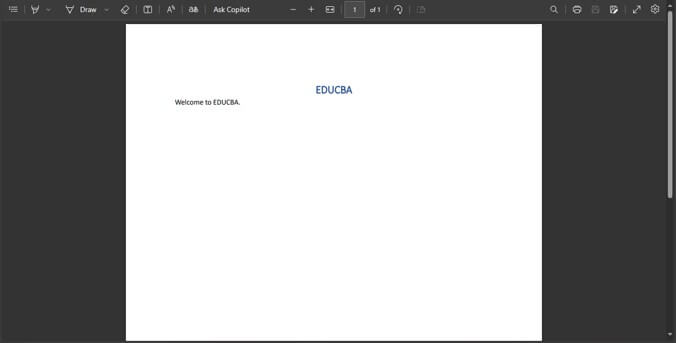
- PDF VIEW:
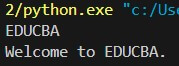
- Extracted Text Output:
Example with Encoded Text
Code:
import PyPDF2
pdf_file = open("Text Extraction.pdf", "rb")
pdf_reader = PyPDF2.PdfReader(pdf_file)
full_text = ""
for page_num in range(len(pdf_reader.pages)):
page = pdf_reader.pages[page_num]
text = page.extract_text()
full_text += text
utf8_bytes = full_text.encode('utf-8')
with open("utf8_encoded_text.txt", "wb") as f:
f.write(utf8_bytes)
print(utf8_bytes.decode('utf-8'))
pdf_file.close()Output:
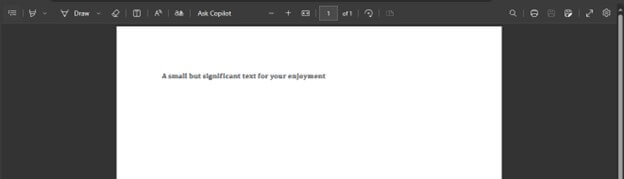
- Endoced Text PDF View:
- Encoded Text Output
![]()
Extracting Tables with Tabula-py
Extracting tables from PDFs can be a common requirement in various fields such as data analysis, finance, and research. Tabula-py is a Python library built on top of Tabula, which provides a convenient interface for extracting tables from PDF documents.
Use Cases
- Extracting financial reports, invoices, product catalogs, and other documents with structured data in tables.
- Converting tabulated data into a format suitable for further analysis (e.g., CSV, pandas DataFrame).
- Automating data collection workflows that rely on information within PDF tables.
Example
Required Python Library:
pip install tabula-pyCode:
import tabula
def extract_tables(pdf_path):
tables = tabula.read_pdf(pdf_path, pages='all', multiple_tables=True)
return tables
pdf_path = 'Text Extraction.pdf'
extracted_tables = extract_tables(pdf_path)
for i, table in enumerate(extracted_tables):
print(f"Table {i + 1}:")
print(table)
print()Output:
- PDF Output:
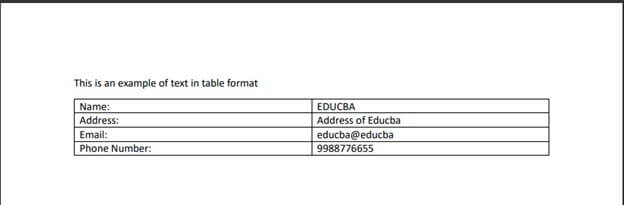
- Code Output:
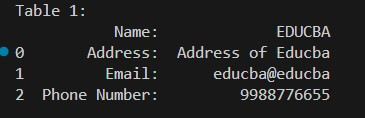
Advanced Topics
Image Extraction
PDF documents can contain images in addition to text and tables. Extracting images from PDFs can be helpful for various purposes, such as analyzing graphical content or processing image-based documents. You can use PyMuPDF (Fitz) and pdf2image libraries to extract images from PDFs.
OCR for Scanned PDFs
Scanned PDFs, also known as image-based PDFs, contain images of text rather than actual text data. Optical Character Recognition (OCR) is a technique used to extract text from scanned PDFs by recognizing characters in the images. Tesseract is a popular OCR engine that can be integrated with Python using libraries like pytesseract to perform OCR on scanned PDFs.
Handling Large or Complex PDFs
- Some PDF documents may be large or have complex structures, making them challenging to process efficiently. To handle such PDFs, consider techniques like:
- Incremental Processing: Process pages of the PDF document one at a time instead of loading the entire document into memory at once.
- Memory Optimization: Use memory-efficient data structures and algorithms to minimize memory usage during processing.
- Parallel Processing: Utilize parallel processing techniques to distribute the workload across multiple CPU cores, improving performance for large PDFs.
Best Practices –
- Choose the Right Library: Select a PDF processing library that best suits your requirements. Take into account elements like performance, user-friendliness, and available features.
- Understand PDF Structure: Familiarize yourself with the structure of PDF documents, including text, images, fonts, and layout information. Understanding the internal structure will help you extract data more effectively.
- Validate Data: Validate extracted data to ensure accuracy and consistency. Perform data cleaning and preprocessing as needed to handle formatting inconsistencies or errors.
- Consider Security: Be cautious when processing PDF files from untrusted sources. PDF documents can contain malicious content, so consider implementing security measures such as file validation and sanitization.
- Keep Libraries Updated: Regularly update your PDF processing libraries to benefit from bug fixes, performance improvements, and new features. Stay informed about library updates and changes to maintain compatibility with your code.
Conclusion
Python offers a robust ecosystem of libraries and tools for extracting valuable information from PDFs. From simple text and layout extraction to complex table structures and scanned documents with OCR. It enables us to uncover useful information, streamline workflows, and make informed decisions across various domains.
Frequently Asked Questions (FAQs)
Q1. How can I extract specific regions or coordinates from a PDF using Python?
Answer: To extract specific regions or coordinates from a PDF, you’ll need to use a library that provides access to the layout information of the PDF content. Libraries like pdfplumber and pdfminer.six offer functionalities to extract text and other elements based on their coordinates. You can then define the coordinates of the region you want to extract and filter the content accordingly.
Q2. Can Python extract data from password-protected PDFs without providing the password?
Answer: No, Python cannot extract data from password-protected PDFs without providing the correct password for decryption. Attempting to access the content of a password-protected PDF without the password will result in an error. You must provide the password to decrypt the PDF before extracting data.
Q3. How can I use Python to extract text with formatting (e.g., font styles, sizes) from PDFs?
Answer: Extracting text with formatting from PDFs is challenging because most PDF extraction libraries focus on extracting plain text without preserving formatting details. However, libraries like pdfminer.six offer functionalities to access font and style information, which you can use to infer formatting details. Remember that extracting formatted text may only sometimes be accurate or straightforward, especially for complex PDF layouts.
Q4. Are there any limitations or constraints when extracting data from PDFs using Python?
Answer: Yes, there are some limitations and constraints when extracting data from PDFs using Python. These may include handling non-standard PDFs, complex layouts, encrypted PDFs, and scanned documents. Additionally, the extraction accuracy may vary depending on the quality and structure of the PDF.
Recommended Articles
We hope that this EDUCBA information on “Extracting Data from PDF Python” was beneficial to you. You can view EDUCBA’s recommended articles for more information,

