Introduction to Data Augmentation
Data augmentation, a fundamental technique in deep learning and machine learning, enriches the volume and diversity of training data. It involves creating new data samples from existing ones through diverse transformations while retaining their labeling information. This procedure is crucial in counteracting overfitting, amplifying model generalization, and bolstering the resilience of machine learning algorithms. By artificially expanding the training dataset, models become more proficient in identifying patterns and features, enhancing performance on previously unseen data. This article explores data augmentation’s definition, significance, and methodologies and delves into its practical applications, implementation strategies, best practices, and case studies across various domains.
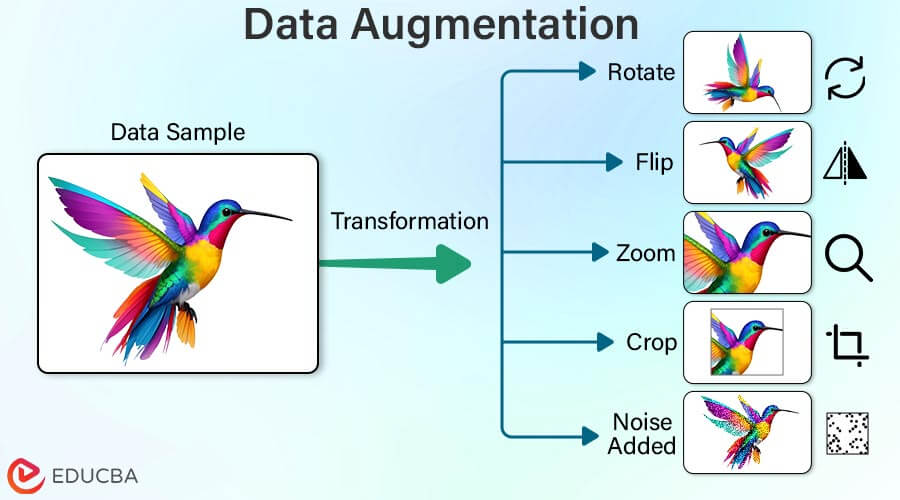
Table of Contents
- Introduction to Ubuntu Office 365
- Techniques of Data Augmentation
- Applications of Data Augmentation
- Implementation of Data Augmentation
- Best Practices and Considerations
Data Augmentation
Data augmentation is a method employed in machine learning and deep learning to expand the diversity and size of a dataset by applying diverse transformations to existing data samples. These transformations may involve rotation, flipping, zooming, cropping, translation, and noise addition. The main objective of data augmentation is to optimize the performance and reliability of machine learning models by providing them with a broader array of representative examples for learning. Through this artificial dataset expansion, models improve their ability to generalize patterns and features, ultimately enhancing their capacity to make precise predictions on unseen data.
Importance in Machine learning and Deep learning
Data augmentation holds immense importance in both machine learning (ML) and deep learning (DL) domains, primarily due to its role in reducing overfitting and improving generalization.
Reduced Overfitting
- Overfitting arises when a model becomes overly tailored to the training data, performing impressively on it but failing to generalize to new, unseen data. It occurs when the model captures irrelevant noise or patterns in the training data, resulting in subpar performance on unseen examples.
- Overfitting typically stems from a model’s complexity relative to the size and diversity of the training data. When confronted with a limited dataset, the model may focus on memorizing specific examples rather than learning the underlying patterns that facilitate generalization.
- Data augmentation is crucial in combating overfitting by enriching the training dataset through diverse transformations. By introducing additional variability into the data, data augmentation ensures the model is exposed to a broader array of examples, preventing it from fixating on specific instances or noise.
- Research findings highlight the effectiveness of data augmentation techniques, such as rotations, flips, and random distortions, in mitigating overfitting. By incorporating these techniques, models are better equipped to generalize to unseen data, leading to enhanced performance across various tasks.
Improved Generalization
- Generalization denotes the capability of a model to perform effectively on data it hasn’t encountered during training. A proficiently generalizing model can make accurate predictions on novel, unseen examples drawn from the same data distribution as the training data.
- Generalization is a fundamental objective in both ML and DL. It showcases the model’s proficiency in capturing underlying data patterns without fixating on specific instances or noise.
- Data augmentation enhances generalization by exposing the model to various variations and scenarios during training. Through training on augmented data, the model acquires the ability to recognize invariant features while maintaining robustness to real-world data variations and distortions.
- Models trained with data augmentation techniques often exhibit superior performance in practical applications. They can generalize effectively beyond the specific training examples, resulting in heightened performance when deployed in real-world scenarios.
Techniques of Data Augmentation
Image Data Augmentation
- Rotation: This technique involves rotating the image by a certain angle, such as 90 degrees clockwise or counterclockwise. Rotation augmentation helps the model learn invariant features from different orientations of the same object, improving its ability to generalize to rotated instances.
- Flip: Image flipping involves horizontally or vertically mirroring the image. Horizontal flipping reverses the image along the y-axis, while vertical flipping reverses it along the x-axis. Flip augmentation aids in teaching the model that the orientation of objects in an image does not affect their identity, enhancing its robustness to horizontal or vertical flips in real-world scenarios.
- Zoom: Zoom augmentation adjusts the scale of the image, either zooming in or out. It involves cropping the image to smaller or larger and then resizing it to its original dimensions. Zoom augmentation helps the model learn to recognize objects at different scales, improving its performance on images with varying levels of detail.
- Crop: Crop augmentation involves randomly cropping a portion of the image and resizing it to the original dimensions. This technique helps the model focus on relevant parts of the image while ignoring irrelevant background clutter. Crop augmentation is beneficial for object detection and localization tasks.
- Translation: Translation augmentation shifts the image along the x and y axes by a certain distance. It simulates the effect of moving the camera or changing the scene’s viewpoint. Translation augmentation enables the model to learn invariant features from different spatial locations within the image, enhancing its ability to generalize to translations in real-world scenarios.
- Shear: Shear augmentation involves applying a shear transformation to the image, distorting it along the x or y axis. This technique helps the model recognize objects from different perspectives, such as skewed or slanted views. Shear augmentation is valuable for improving the model’s robustness to perspective distortions in real-world images.
- Noise Injection: Noise injection involves adding random noise to the image and simulating variations in lighting conditions or sensor noise. Common types of noise include Gaussian noise, salt-and-pepper noise, or speckle noise. Noise injection augmentation helps the model learn to ignore irrelevant noise in the input data, improving its resilience to noisy images encountered in real-world scenarios.
Text Data Augmentation
- Synonym Replacement: In synonym replacement, words in the text are replaced with their synonyms while maintaining the overarching context and significance of the sentence. This technique helps to increase the diversity of the vocabulary used in the training data, thereby improving the model’s ability to generalize to word-choice variations.
- Random Insertion: Random insertion involves randomly inserting new words into the text. Users can select these inserted words from a predefined vocabulary or generate them using techniques such as word embeddings. Random insertion helps introduce variability into the text data, making the model more robust to sentence structure and length variations.
- Random Swap: Random swap entails swapping pairs of adjacent words in the text. This technique disrupts the original word order while maintaining the overall coherence of the sentence. By shuffling the word positions, the random swap augmentation technique encourages the model to emphasize the relationships between words rather than their absolute positions in the sentence.
- Random Deletion: Random deletion involves randomly removing words from the text with a certain probability. This technique forces the model to rely on the remaining words to infer the missing information, thereby improving its ability to understand the context of the sentence even with incomplete input. Random deletion augmentation helps to simulate noisy or incomplete text data commonly encountered in real-world scenarios.
Audio Data Augmentation
- Speed Perturbation: Speed perturbation involves altering the playback speed of an audio signal. It can include speeding up or slowing down the audio while maintaining its pitch. Speed perturbation augmentation helps the model learn to recognize spoken words at different speaking rates, improving its robustness to variations in speech tempo.
- Pitch Shift: Pitch shift augmentation involves modifying the pitch of an audio signal while preserving its duration. It can include shifting the pitch higher or lower by a certain number of semitones. Pitch shift augmentation simulates variations in speaker pitch or vocal characteristics, helping the model generalize to different speaking styles.
- Time Stretching: Time stretching involves stretching or compressing the duration of an audio signal while preserving its pitch. It can include elongating or shortening the duration of the audio waveform. Time stretching augmentation helps the model recognize speech at different speeds, enhancing its ability to handle variations in speech duration.
- Noise Addition: Noise addition augmentation involves injecting background noise into the audio signal. It can include adding random noise samples or mixing the audio with sounds from different environments. Noise addition augmentation helps the model distinguish between speech and background noise, improving its robustness to noisy audio conditions commonly encountered in real-world scenarios.
Applications of Data Augmentation
- Image Classification:
- It refers to a computer vision task wherein an algorithm assigns a label or category to an image based on its visual content.
- Data augmentation plays a crucial role in image classification by expanding the diversity of the training dataset. Augmented images introduce variations that help the model generalize better to unseen data.
- Augmentation techniques like rotation, flipping, zooming, etc., can be applied to images to create variations in the dataset for training classifiers.
- Object Detection:
- Object detection involves identifying and localizing objects within an image or a video frame. It goes beyond classification by recognizing the presence of objects and specifying their locations using bounding boxes.
- Data augmentation enhances the robustness of object detection models by offering them a broader array of object examples in different orientations, scales, and lighting conditions.
- Like image classification, augmentation techniques such as rotation, flipping, scaling, and adding noise are employed to generate additional training samples for object detection tasks.
- Image Segmentation:
- It entails partitioning an image into multiple segments or regions based on particular criteria, such as pixel intensity or similarity in color.
- Data augmentation improves the accuracy of image segmentation models by generating augmented images with variations in object shapes, sizes, and positions.
- You can apply augmentation techniques like flipping, rotation, scaling, and elastic transformations to images to create diverse training data for image segmentation models.
- Natural Language Processing (NLP):
- NLP is a branch of AI that bridges the gap between computers and human languages, enabling text analysis tasks like classification, sentiment analysis, and translation.
- You employ data augmentation in NLP tasks to generate additional training examples, especially in limited labeled data scenarios. Augmentation techniques help create text data variations without significantly altering its semantics.
- Synonym replacement, random insertion, random swap, and random deletion are common augmentation techniques used in NLP to introduce variations in text data.
- Speech Recognition:
- Speech recognition involves converting spoken language into text. Various applications utilize it, such as virtual assistants, voice search, and dictation software.
- Data augmentation is crucial in speech recognition to improve the robustness of models against variations in speech patterns, accents, background noise, and environmental conditions.
- Augmentation techniques like speed perturbation, pitch shifting, time stretching, and adding background noise are employed to create variations in speech data for training speech recognition models.
- Other Machine Learning Tasks:
- This category encompasses a wide range of machine learning tasks beyond the ones above, including but not limited to regression, clustering, anomaly detection, and reinforcement learning.
- Data augmentation applies to various machine learning tasks, and having a diverse and representative training dataset is essential for model performance and generalization.
- The choice of augmentation techniques depends on the specific task and the nature of the data involved. You may employ feature augmentation, oversampling, and synthetic data generation techniques based on the task requirements.
Implementation of Data Augmentation
Code Example Using Keras Library
- Importing the Libraries
import numpy as np
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from tensorflow.keras.preprocessing.image import ImageDataGenerator- Loading CIFAR-10 Dataset:
We will then load the CIFAR-10 dataset, comprising 60,000 32×32 color images distributed across 10 classes, with 6,000 images allocated per class.
(x_train, y_train), (x_test, y_test) = cifar10.load_data()Output:
![]()
- Data Preprocessing:
_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255We divide the pixel values of images by 255 to normalize them to the range [0, 1].
- Data augmentation setup:
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
)We then create an ImageDataGenerator object with various augmentation parameters such as rotation range, width shift range, height shift range, shear range, zoom range, and horizontal flip.
- Model Definition:
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])This section defines a sequential model using Keras’ Sequential API. It consists of convolutional layers, max-pooling layers, and dense layers. The model architecture is a simple CNN suitable for image classification tasks.
- Model Compilation:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])We compile the model using the Adam optimizer, sparse categorical cross-entropy loss function, and accuracy metric.
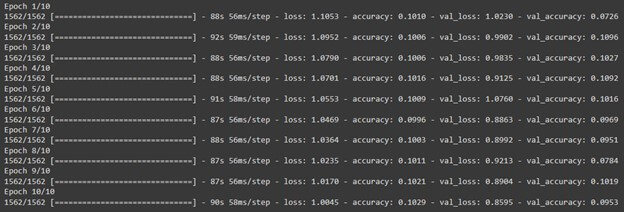
- Model Training with Data Augmentation:
batch_size = 32
train_generator = datagen.flow(x_train, y_train, batch_size=batch_size)
history = model.fit(train_generator, steps_per_epoch=len(x_train) // batch_size, epochs=10, validation_data=(x_test, y_test))
You call the fit method to train the model. Here, train_generator generates augmented batches of training data, and steps_per_epoch ensures the model sees all augmented samples in each epoch.
Output:
- Model Evaluation:
test_loss, test_acc = model.evaluate(x_test, y_test)
print("Test Accuracy:", test_acc)Ultimately, we evaluate the trained model on the test dataset and print the test accuracy.
Output:
![]()
Best Practices and Considerations
- Choose correct augmentation techniques:
Selecting the proper augmentation methods involves understanding your dataset’s unique characteristics and your task’s specific requirements. Crafting augmentation techniques ensure that they improve model performance and enhance the generalization ability of unseen data.
- Impact on Model Performance:
Data augmentation plays a pivotal role in shaping model performance. Exposing the model to diverse examples during training helps build robust features and improve generalization. However, balancing is crucial, as excessive or inappropriate augmentation techniques can adversely affect performance degradation.
- Overfitting and Generalization:
One of the primary benefits of data augmentation is its ability to combat overfitting by providing the model with a more varied training set. This diversification helps prevent the model from memorizing the training data too closely, thus improving its ability to generalize to new, unseen data. However, monitoring the augmentation process is essential to ensure it doesn’t inadvertently introduce biases that could hinder the model’s generalization capabilities.
- Computational Resources and Efficiency:
While data augmentation is an effective strategy for improving model performance, it can also incur increased computational costs, especially when handling large datasets or complex augmentation techniques. Achieving a balance between augmentation effectiveness and computational efficiency is crucial to optimizing training resources and ensuring timely model development.
- Ethical Considerations:
Employing data augmentation responsibly involves considering a range of ethical implications, including privacy, fairness, and bias. It’s essential to be mindful of how augmentation techniques may impact the data’s characteristics and the model’s performance. Transparent reporting of the augmentation methods enhances reproducibility and fosters accountability in developing and deploying machine learning models.
Conclusion
Data augmentation emerges as a potent technique in machine learning, enriching training datasets and bolstering model resilience. The deliberate diversification of training samples alleviates overfitting and promotes generalization, enhancing model efficacy across diverse tasks. Nonetheless, its successful application demands a thoughtful assessment of dataset attributes, computational constraints, and ethical dimensions. As machine learning progresses, embracing ethical augmentation practices fosters the creation of more precise and dependable models and upholds principles of equity, transparency, and responsibility in integrating AI solutions.
Frequently Asked Questions (FAQs)
Q1. How do I implement data augmentation in my machine-learning pipeline?
Answer: Data augmentation usually involves utilizing libraries or frameworks with built-in support for augmentation methods. For instance, TensorFlow, Keras, and PyTorch provide APIs facilitating seamless integration of data augmentation within the training pipeline.
Q2. Can data augmentation be used to address imbalanced datasets?
Answer: Indeed, data augmentation aids in handling imbalanced datasets by generating synthetic instances for underrepresented classes. Methods like oversampling, involving duplication of minority class samples, or SMOTE (Synthetic Minority Over-sampling Technique), which produces synthetic examples for minority classes, can prove advantageous.
Q3. Are there any limitations to data augmentation?
Answer: While data augmentation is a powerful tool, it does have limitations. Augmented data may not always capture real-world data’s full complexity and variability, and inappropriate augmentation techniques can introduce biases or distortions. Additionally, data augmentation may only be suitable for some datasets or tasks, particularly in domains where preserving the integrity of the original data is critical.
