What is Synthetic Data Generation?
Synthetic data generation involves forming artificial data that simulates real-world data. Instead of collecting data from real people or events, algorithms or computer simulations generate synthetic data. It looks and behaves like real data but not from real sources.
This data type is useful for testing, training machine learning models, or conducting research when real data is limited, expensive to collect, or must be kept private for security reasons. It helps maintain privacy and security while still allowing analysis and experimentation.
Applications of Synthetic Data
Synthetic data generation has numerous applications across different fields. Here are some of the most common use cases:
1. Training Data for ML and AI Models
Machine learning models require large datasets for effective training. Synthetic data expands small datasets, improving their robustness.
2. Text Generation for NLP Models
Synthetic text data can benefit Natural Language Processing (NLP) models, especially for low-resource languages where real data is scarce.
3. Fraud Detection and Trading Algorithms
Synthetic financial data trains fraud detection algorithms, and synthetic stock market data tests trading algorithms.
4. Autonomous Vehicles and Robotics
Synthetic environments and traffic patterns train and test autonomous vehicles and robots in simulations before deployment in the real world.
5. Healthcare Research
Synthetic data can be used for medical research and training, enabling researchers to conduct studies without exposing real patient data.
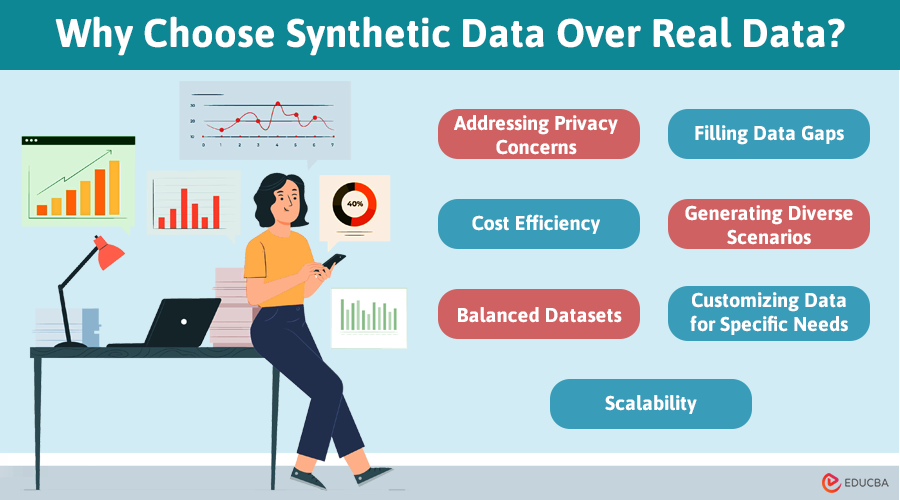
Why Choose Synthetic Data Over Real Data?
There are several advantages to using synthetic data instead of real-world data. Here is why synthetic data generation is often preferred:
1. Addressing Privacy Concerns
Real data often contains sensitive information, such as medical or financial records. Synthetic data generation creates realistic datasets that replicate the statistical properties of real data without compromising privacy.
2. Cost Efficiency
Collecting and analyzing real-world data can be costly and time-consuming. Synthetic data can be quickly and cost-effectively generated, saving both time and money.
3. Balanced Datasets
Real-world data can have biases or imbalances, such as over- or under-represented groups. Synthetic data generation can create balanced datasets to overcome these issues.
4. Filling Data Gaps
When real data is scarce or unavailable, synthetic data can fill the gaps, allowing projects to move forward without delay.
5. Generating Diverse Scenarios
Synthetic data generation allows the creation of diverse scenarios, including rare events that may not be present in real datasets.
6. Customizing Data for Specific Needs
Researchers can control the features and characteristics of synthetic data, tailoring it to meet their projects’ specific requirements.
7. Scalability
Synthetic data generation enables you to produce large quantities of data on demand, making it easy to scale for various studies and applications.
How to Use Synthetic Data?
Using synthetic data generation effectively involves several steps. Here is a simplified guide to get you started:
1. Define Your Objective
Determine why you need synthetic data. Is it to replace rare datasets, test a model, or preserve privacy? Having a clear objective is crucial.
2. Select the Right Generation Method
Choose the most appropriate synthetic data generation method based on your needs:
- Statistical Methods
- Simulation-based Methods
- Generative Adversarial Networks (GANs)
- Variation Autoencoders (VAEs)
3. Validate Synthetic Data
Compare the statistical properties of your synthetic data with the real data it mimics. Ensure your models perform well in real-world scenarios and verify that no sensitive information is exposed.
4. Combine Real and Synthetic Data (If Possible)
Mixing real data with synthetic data can improve model training unless privacy or data scarcity is a concern. This combined approach takes advantage of the benefits of both data types.
5. Deploy Models and Use Cases
Once you have validated your data and trained your models, deploy them in real-world environments. Use synthetic data to stress-test algorithms or share datasets with third parties without privacy concerns.
Final Thoughts
Synthetic data generation is a versatile and powerful tool that can drive innovation across many fields. By understanding its benefits and applications, you can harness synthetic data to overcome challenges with real-world data, ensuring more efficient and effective project outcomes.
Whether you are training machine learning models, conducting research, or testing algorithms, synthetic data generation offers a flexible solution. It also provides scalability, adapting to any project size.
Recommended Articles
We hope this guide on synthetic data generation has been helpful. Explore these recommended articles for deeper insights into applications, techniques, and benefits of synthetic data.

