Introduction to Adversarial Machine Learning
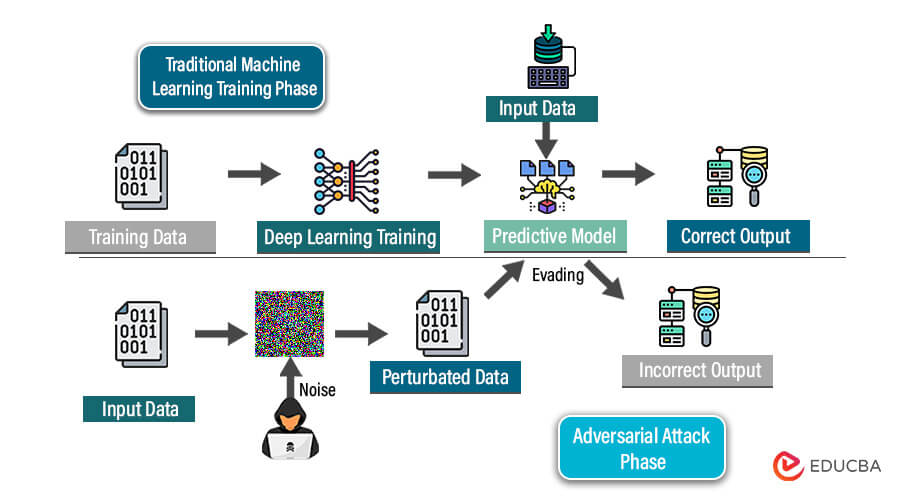
Adversarial machine learning is a field where attackers deliberately craft inputs, called adversarial examples, to fool machine learning models. These subtle alterations, invisible to humans, can lead to drastic misclassifications.
For example, an image recognition system could misclassify a slightly modified panda image as a gibbon. Adversarial machine learning studies both the creation of these attacks, exposing model vulnerabilities, and developing defenses to make models more robust.
This field has implications for security-sensitive areas like autonomous vehicles, facial recognition, and spam filtering, where attacks could have real-world consequences.
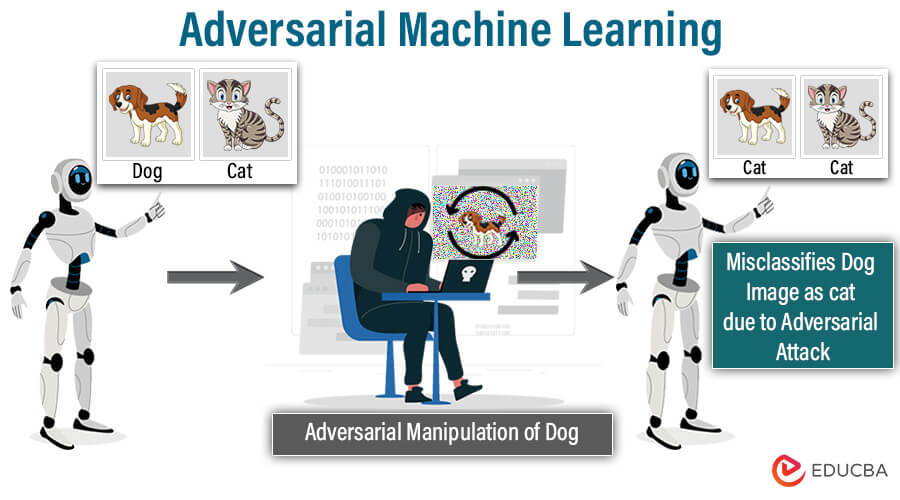
Table of Contents
- Introduction to Adversarial Machine Learning
- What is Adversarial Machine Learning
- Security implications in autonomous systems
- Case studies of adversarial attacks in deployed systems
- Types of Adversarial Attacks
- Defense Mechanisms
- Adversarial Machine Learning Examples
- How to Defend against Adversarial Attacks
- Popular Adversarial Attack Methods
- Generating Adversarial Attack
- Real-world Examples of Adversarial Attacks
Key Takeaways
- Adversarial Machine Learning pertains to protecting ML models from nefarious attacks.
- Attackers exploit weaknesses by altering inputs to trick algorithms.
- Approaches in Adversarial Machine Learning strive to enhance model durability and ability to resist attacks.
- Its uses extend to cybersecurity and independent systems.
- The main objective is to maintain the dependability and honesty of AI systems.
- Its importance lies in strengthening defenses against hostile attacks in various domains.
What is Adversarial Machine Learning?
Within artificial intelligence (AI), adversarial machine learning (AML) focuses on comprehending, identifying, and defending against adversarial attacks on AML models. In this context, adversaries aim to exploit weaknesses in ML models by intentionally constructing input data to mislead the algorithms, resulting in inaccurate predictions or classifications. Researchers design Adversarial Machine Learning techniques to strengthen the resilience and robustness of these models, ensuring their dependability and credibility in the presence of such attacks. For example, malicious actors can make subtle changes to images in image classification to deceive the model. Even though these changes may be invisible, they can lead the model to incorrectly classify a cat as a dog, emphasizing the importance of having solid defenses.
Differentiating adversarial attacks from traditional security threats
| Section | Adversarial Attacks | Traditional Security Threats |
| Target | Machine Learning Models | IT Systems, Networks, Applications |
| Objective | Exploit vulnerabilities in ML models to deceive | Gain unauthorized access, steal data, disrupt operations |
| Attack Method | Manipulate input data to mislead algorithms | Phishing, malware, DDoS attacks, SQL injection |
| Detection Difficulty | Challenging due to subtle, targeted manipulations | Detection methods like intrusion detection systems (IDS) |
| Impact on System | Misclassification, undermining model accuracy | Data breaches, system downtime, financial losses |
| Defense Mechanisms Needed | Adversarial robustness techniques, model hardening | Firewalls, antivirus software, encryption |
| Examples | Fooling image classifiers, evasion attacks on NLP models | Data breaches, ransomware attacks, network intrusions |
Examples
- Audio Attacks: Audio attacks targeting speech recognition systems involve subtly altering audio signals. Attackers may introduce imperceptible noise or manipulate speech patterns to create audio commands that voice-controlled devices misinterpret. Consequently, this could lead to unintended actions by the user or potentially enable attackers to gain unauthorized access to systems by exploiting vulnerabilities in voice authentication systems.
- Malware Detection Evasion Attacks: These types of attacks entail creating malware samples that can avoid being discovered by antivirus programs. Attackers slightly alter the behavior or coding of malware to evade standard antivirus systems’ signature-based detection techniques. It makes it easier for them to spread malware payloads covertly, which helps with cybercrime operations like ransomware assaults, data theft, and espionage.
- Manipulation of Autonomous Systems: Adversaries can manipulate autonomous systems by exploiting vulnerabilities in their perception systems. For example, strategically placing adversarial stickers on road signs or altering their appearance can deceive object detection algorithms used in autonomous vehicles. Consequently, this could lead to hazardous situations wherein the car misidentifies traffic signs or pedestrians, posing a threat to passengers and other road users.
Security Implications in Autonomous Systems:
Autonomous systems, such as self-driving cars and drones, pose distinct security challenges stemming from their dependency on intricate algorithms and interconnected networks. These systems engender several significant security considerations:
Cyberattacks: Autonomous systems are susceptible to cyber intrusions, which have the potential to disrupt their functions or wrest control without authorization. Hostile entities might capitalize on vulnerabilities in software or communication protocols to compromise autonomous vehicles or drones.
Data Privacy: These systems produce copious amounts of data, encompassing sensitive details about their environment and users. Preserving this data’s privacy and security is paramount to forestall unauthorized access or exploitation.
Safety Implications: The occurrence of security breaches in autonomous systems can pose significant safety risks, potentially resulting in accidents or injuries. It is imperative to establish resilient security protocols to mitigate potential threats and guarantee the secure functionality of these systems.
Adherence to Regulations: Regulatory frameworks governing autonomous systems must encompass security considerations to uphold adherence to legal and industry benchmarks. It encompasses mandates for cybersecurity protocols, data safeguarding, and the reporting of incidents.
Ethical Implications: Security breaches in autonomous systems can give rise to ethical issues, including the possibility of causing harm to individuals or communities. Stakeholders should guide the development and deployment of these systems by ethical principles and guidelines to mitigate risks and encourage responsible utilization.
Case Studies of Adversarial Attacks in Deployed Systems in Adversarial ML
Adversarial machine learning encompasses various techniques designed to exploit vulnerabilities within machine learning models. Several real-world case studies have shed light on examples of adversarial attacks in operational systems:
Adversarial Examples: Researchers have illustrated how minor alterations to input data can mislead machine learning models, resulting in inaccurate predictions. Adversarial examples have been utilized to circumvent image recognition systems, deceive autonomous vehicles, and manipulate natural language processing models. Let us take simple examples.
Code:
import numpy as np
import tensorflow as tf
from tensorflow.keras.applications import MobileNetV2
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input, decode_predictions
from tensorflow.keras.preprocessing import image
import matplotlib.pyplot as plt
# Load pre-trained MobileNetV2 model
model = MobileNetV2(weights='imagenet')
# Load and preprocess the original image
original_img_path = 'original_cat.jpg' # Path to the original image
original_img = image.load_img(original_img_path, target_size=(224, 224))
original_x = image.img_to_array(original_img)
original_x = np.expand_dims(original_x, axis=0)
original_x = preprocess_input(original_x)
# Convert NumPy array to TensorFlow tensor
original_x_tensor = tf.convert_to_tensor(original_x)
# Generate adversarial example using Fast Gradient Sign Method (FGSM)
epsilon = 0.1
loss_object = tf.keras.losses.CategoricalCrossentropy()
with tf.GradientTape() as tape:
tape.watch(original_x_tensor) # Watch the TensorFlow tensor
prediction = model(original_x_tensor)
loss = loss_object(tf.one_hot([282], prediction.shape[-1]), prediction)
gradient = tape.gradient(loss, original_x_tensor)
perturbation = tf.sign(gradient)
perturbed_image = original_x_tensor + epsilon * perturbation
original_label = ('n02124075', 'cat', 0.95)
# Make prediction on the perturbed image
adv_pred = model.predict(perturbed_image)
adv_label = decode_predictions(adv_pred)[0][0]
# Display the original image and the adversarial example
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.imshow(original_img)
plt.title('Original Image\nPrediction: {} ({:.2%})'.format(original_label[1], original_label[2]))
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(tf.squeeze(perturbed_image))
plt.title('Adversarial Example\nPrediction: {} ({:.2%})'.format(adv_label[1], adv_label[2]))
plt.axis('off')
plt.show()Output:

Explanation;
- The Fast Gradient Sign Method (FGSM) is used to generate adversarial examples, a technique for crafting perturbations to input data to mislead machine learning models.
- The MobileNetV2 model, pre-trained on the ImageNet dataset, is loaded as the target model for generating adversarial examples.
- An original image is loaded and preprocessed to ensure compatibility with the MobileNetV2 model’s input requirements, including resizing and normalization.
- To find the best direction to perturb the image to maximize the loss, the FGSM algorithm computes the gradient of the loss function with respect to the input image.
- A small perturbation is added to the original image based on the computed gradient, creating a visually similar adversarial example that may lead to a different model prediction.
- The MobileNetV2 model predicts class probabilities for both the original image and the adversarial example.
- The top predicted class label, class description, and confidence score are extracted from the model’s predictions for both images.
- The original image and the corresponding adversarial example are displayed side by side using Matplotlib for visualization.
- Through this process, the code showcases the vulnerability of machine learning models to adversarial attacks and emphasizes the importance of robustness testing and mitigation strategies in model development and deployment.
Poisoning Attacks: In poisoning attacks, adversaries modify training data to undermine the reliability of machine learning models. For instance, attackers may insert malicious samples into training datasets to introduce biases or diminish model performance.
Evasion of Models: Hostile entities can generate adversarial samples with the specific intention of circumventing detection by security systems based on machine learning. These attacks present a substantial risk to systems that depend on anomaly detection or intrusion detection methodologies.
Transference: Adversarial attacks frequently demonstrate transference, indicating that adversarial instances created for one model can also deceive other models trained on similar datasets. This occurrence empowers attackers to execute far-reaching attacks across various systems and applications.
Defenses and Mitigation Strategies: Researchers and practitioners are actively engaged in creating diverse defensive measures and mitigation strategies aimed at thwarting adversarial attacks. These measures include robust training techniques, adversarial training, and model monitoring. Nonetheless, the ever-evolving contest between aggressors and defenders underscores the persistent hurdles in safeguarding machine learning systems against adversarial threats.
Types of Adversarial Attacks
White-box Attacks:
A white-box attack gives the attacker full access to the internal workings of the target system, including its design and implementation. This is unlike black-box testing, where the attacker has limited or no knowledge of the system’s internals. During a white-box attack, the attacker can access the source code, architectural diagrams, and documentation, allowing them to exploit vulnerabilities more effectively. Security professionals commonly use white-box attacks to assess a system’s defenses and uncover potential weaknesses.
Examples:
In the 2017 Equifax data breach, attackers exploited a vulnerability in Apache Struts, an open-source web application framework used by Equifax. By scrutinizing the Apache Struts code, the attackers identified a weakness (CVE-2017-5638) that allowed them to execute unauthorized code on Equifax’s servers. With this knowledge, the attackers gained unauthorized access to sensitive personal and financial data of approximately 147 million individuals. The breach led to widespread identity theft and financial fraud, highlighting the severe consequences of white-box attacks.
Black-Box Attacks:
Black-box attacks occur when adversaries can’t access the inner workings of a machine-learning model. They only interact by providing input and observing outputs. Crafting adversarial examples is difficult without access to the model’s details. Two common approaches are query-based attacks and transfer attacks.
Examples:
- Facial Recognition System Attack (2018): University of Toronto researchers targeted facial recognition systems, tweaking images to deceive the model. This led to security vulnerabilities and unauthorized access.
- Voice Command Recognition Attack (2016): Georgetown University and University of California, Berkeley researchers exploited voice recognition systems like Alexa and Siri by embedding hidden commands in audio, causing unintended actions.
Transfer Attacks:
Transfer attacks use the transferability of adversarial perturbations across diverse machine learning models. Adversarial examples designed for one model are employed to target another model, regardless of differing architectures or training datasets. Transfer attacks exploit shared vulnerabilities among models, enabling attackers to create adversarial examples that effectively trick multiple models.
Evasion Attacks:
Evasion attacks entail skillfully incorporating specific disturbances into input data to induce misclassification or modify the model’s predictions. These alterations must remain invisible to human observers. Adversarial examples created through evasion attacks are engineered to capitalize on weaknesses in the model’s decision boundaries, resulting in inaccurate or unforeseen outputs.
Poisoning Attacks:
Poisoning attacks seek to alter the behavior of machine learning models by inserting harmful data into the training dataset. Through minor changes to some training samples, attackers can introduce biases or manipulate the model’s decision-making, impacting its accuracy in making future predictions. Poisoning attacks can be highly damaging as they compromise the trustworthiness and consistency of the entire training procedure.
Exploratory Attacks:
Exploratory attacks involve iteratively querying the target model to learn its vulnerabilities and generate adversarial examples. Attackers systematically explore the model’s decision space, gradually refining their attack strategy based on the model’s responses. Exploratory attacks are often used in black-box scenarios, where attackers have limited knowledge of the target model and must experiment to uncover its weaknesses.
Model Inversion Attacks:
Model inversion attacks leverage model outputs to deduce sensitive details about the data used for training. Through scrutiny of the model’s predictions, perpetrators seek to reverse-engineer attributes of the training dataset, posing a risk to the privacy and confidentiality of individuals depicted in the data. Model inversion attacks underscore the significance of safeguarding sensitive information within machine learning systems.
Adversarial Attack Defense Mechanisms
1. Adversarial Training:
Adversarial training incorporates adversarial examples into the standard training process to enhance the model’s robustness against adversarial attacks. By subjecting the model to adversarial perturbations and adjusting its parameters to minimize loss on both clean and adversarial examples, adversarial training strengthens the model’s defensive capabilities.
2. Defensive Distillation:
Defensive distillation is a method that entails training a model using modified versions of the training data or forecasts derived from another model. By transferring knowledge from the teacher model to the student model through temperature scaling or similar techniques, defensive distillation can enhance the student model’s overall performance and resistance to adversarial attacks.
3. Input Preprocessing Techniques:
Input preprocessing techniques encompass adjusting input data before feeding it into the model to minimize the influence of adversarial perturbations. Procedures like input normalization, feature scaling, or spatial transformation can lessen the effectiveness of adversarial attacks by enhancing the input data’s resilience against manipulation.
- Input Normalization: Scaling input data to a standard range, ensuring consistent feature magnitudes, and reducing sensitivity to variations.
- Feature Scaling: Adjusting feature ranges to avoid dominance during training and enhance model performance and robustness.
- Spatial Transformation: Applying geometric changes to input images increases model resilience to variations and improves generalization.
- Noise Injection: Introducing controlled noise to input data increases model tolerance to minor deviations and serves as regularization.
- Adversarial Training Data Generation: Creating adversarial examples during training to expand the dataset, promoting robust decision boundaries and attack resilience.
4. Gradient Masking and Obfuscation:
Gradient masking and obfuscation techniques encompass the means of concealing or disturbing model gradients during training, aimed at hindering adversaries from effectively devising adversarial examples by utilizing gradient-based optimization approaches. Through the obscuration of gradient information, these techniques introduce increased difficulty for attackers seeking to exploit vulnerabilities within the model.
5. Robust Optimization Techniques:
Robust optimization techniques entail adjusting the typical optimization algorithms utilized in model training to consider adversarial examples effectively. The primary goal of these techniques is to train models that can better withstand adversarial attacks by promoting the learning of robust decision boundaries that are less vulnerable to slight variations in the input data. Typically, these techniques involve integrating supplementary objectives or regularization terms into the training process.
Examples of robust optimization methods comprise adversarial training, involving training models on both clean and adversarial examples to promote robustness, and adversarial regularization, which entails adding extra regularization terms to the loss function to penalize model behavior vulnerable to adversarial manipulation. These methods can enhance the resilience of machine learning models against adversarial attacks and reduce their impact on model performance and security.
6. Ensemble Methods:
Ensemble methods entail consolidating numerous models or defenses to bolster model resilience in adversarial attacks. By capitalizing on the diversity in model predictions or defense strategies, ensemble methods can fortify the system’s overall robustness and alleviate the influence of adversarial examples.
7. Adversarial Detection and Rejection:
Adversarial detection and rejection mechanisms entail integrating modules into the model architecture to identify and discard real-life adversarial examples. Approaches like anomaly detection algorithms or adversarial example detectors can pinpoint questionable inputs and safeguard model predictions, thereby fortifying the model’s security and dependability.
Adversarial Machine Learning Examples
Crafting Perturbed Images: Adversarial assaults on picture recognition systems entail manipulating input images through imperceptible alterations to deceive the model into generating inaccurate predictions. For instance, incorporating meticulously crafted noise or adjusting pixel values within an image of a panda can lead to the misclassification of the image as a gibbon with substantial certainty by an image recognition system, even though the altered image continues to resemble a panda to human observers.
Generating Adversarial Text: Adversarial assaults on natural language processing (NLP) models are designed to alter text inputs to circumvent filters or induce misinterpretation. For example, appending or substituting words in a spam email can trick an email filter into categorizing it as a genuine message. Similarly, subtle modifications in language can deceive sentiment analysis models into inaccurately classifying the sentiment of a text.
Manipulating Sensor Data: Adversarial attacks on autonomous vehicles manipulate sensor inputs such as LiDAR, radar, or cameras to mislead the vehicle’s perception systems. By introducing alterations to sensor data, adversaries can construct adversarial instances that lead the car to misread its surroundings. Adding stickers to a stop sign, for example, could result in an autonomous vehicle incorrectly identifying it as a speed limit sign, possibly creating hazardous conditions on the road.
How to Defend against Adversarial Attacks
It is essential to use a variety of tactics and strategies to increase the robustness and resilience of machine learning models to reduce adversarial attacks. Presented below are several approaches for defending against adversarial attacks:
- Adversarial training: The practice of training machine learning models with purposefully disrupted data to increase the model’s robustness is known as adversarial training. The model can learn to identify and withstand such attacks by incorporating adversarial examples into the training dataset.
- Robust optimization: It refers to utilizing optimization techniques that explicitly integrate defenses against adversarial attacks during the training phase. This may entail adjusting the loss function or incorporating regularization terms to promote the model’s resilience to perturbations.
- Input preprocessing: Input preprocessing encompasses applying various techniques, such as input normalization, dimensionality reduction, or noise injection, to cleanse input data and enhance its ability to resist adversarial perturbations.
- Defensive Distillation: The process involves training a distilled model using the softer predictions from a primary model as labels. This approach results in a distilled model that displays reduced sensitivity to minor alterations in the input space, thus enhancing its resilience against adversarial attacks.
- Ensemble Methods: Ensemble approaches combine several machine learning models trained on different data sources or using various methodologies. Ensemble methods can enhance overall robustness by harnessing diverse predictions and mitigating the impact of adversarial perturbations.
- Feature Squeezing: This technique focuses on diminishing the precision of input features to alleviate or eliminate the impact of adversarial perturbations. For instance, quantizing continuous features into discrete intervals can bolster the model’s ability to withstand minor input-value fluctuations.
- Randomization techniques: Incorporate randomness into the model or its training process to heighten the difficulty for potential attackers in crafting practical adversarial examples. This may entail the introduction of random noise to input data, implementing dropout during training, or randomizing model parameters.
- Model monitoring and anomaly detection: Vigilantly observe model behavior within production environments to detect indications of adversarial attacks or unexpected deviations from typical behavior. Deploy anomaly detection methodologies to recognize and promptly address adversarial inputs in real-time.
- Adversarial example detection: Formulate approaches to identify adversarial examples during inference by scrutinizing model predictions and input data. This can encompass using adversarial example detection networks or outlier detection algorithms.
- Regular security practices: Regular security practices involve implementing customary security measures, including access controls, encryption, and intrusion detection, to safeguard machine learning systems from unauthorized access or tampering.
Popular Adversarial Attack Methods
Fast Gradient Sign Method (FGSM): Fast gradient sign technique (FGSM), developed by Goodfellow et al. in 2014, is one of the most accessible and popular adversarial assaults on neural networks. FGSM involves introducing a small perturbation to the input image aligned with the sign of the gradient of the loss function to the input. This perturbation is intended to elevate the loss and induce the neural network to misclassify the input. While FGSM can produce adversarial examples in a single step, its optimality and practical applicability may be limited.
Projected Gradient Descent (PGD): Projected Gradient Descent (PGD) is an iterative optimization method that produces adversarial examples. This technique involves iteratively applying minor perturbations to the input data, ensuring that the perturbed examples remain within a specified epsilon ball around the original data point. PGD exhibits enhanced effectiveness compared to FGSM, enabling the identification of adversarial examples with elevated success rates.
DeepFool: The DeepFool attack is an iterative approach to generate adversarial examples. It commences with an initial input image and calculates the minimal perturbation required to alter its classification. This is achieved by linearizing the model’s decision boundaries around the input image and identifying the direction in which the image can be most significantly perturbed to induce misclassification. Through the incremental application of minor perturbations, DeepFool creates adversarial examples that are often indiscernible to humans but have the potential to elicit incorrect predictions from the model.
Carlini-Wagner (CW) Attack: The Carlini-Wagner (CW) Attack, developed by Nicholas Carlini and David Wagner, employs an optimization-based method to create adversarial examples. It establishes an objective function to minimize the perturbation added to input data while ensuring misclassification by the intended model. This attack demonstrates effectiveness across diverse model architectures and defense mechanisms, thus serving as a formidable tool for generating adversarial examples. However, despite its efficacy, this approach necessitates access to the target model’s architecture and gradients, potentially requiring substantial computational resources.
Boundary Attack: The Boundary Attack employs an iterative approach to create adversarial examples by probing the decision boundary of a machine learning model. It commences from a random point near the original input and progresses towards the boundary, dynamically adjusting the step size. In each iteration, it projects the current input onto the decision boundary. The attack persists until it identifies an adversarial example or reaches a predetermined number of iterations. Notably, this method is adept at discovering adversarial examples close to the decision boundary without necessitating access to the model’s gradients.
Jacobian-based Saliency Map Attack (JSMA): The Jacobian-based Saliency Map Attack (JSMA) creates adversarial examples by identifying and modifying the most prominent features within the input space. This method involves computing the Jacobian matrix to pinpoint the features that significantly influence the model’s prediction for a particular class. Subsequently, it systematically modifies these features to induce misclassification. JSMA is proficient in producing adversarial examples, particularly when targeting models heavily depending on specific input features for classification. Nonetheless, it may encounter challenges when operating in high-dimensional input spaces or dealing with intricate models.
Techniques/Methods Used in Generating Adversarial Attack
| Attack Method | Description |
| Fast Gradient Sign Method (FGSM) | calculates perturbation by making little steps toward the loss function’s gradient. |
| Projected Gradient Descent (PGD) | Iteratively applies small perturbations to the input while ensuring the perturbed examples remain within a specified epsilon ball around the original data point. |
| DeepFool | Iteratively computes minimal perturbation by linearizing the decision boundaries of the model. |
| Carlini-Wagner (CW) Attack | Optimization-based attack minimizing perturbation while ensuring misclassification. |
| Boundary Attack | Iteratively explores the decision boundary of the model to find adversarial examples. |
| Jacobian-based Saliency Map Attack (JSMA) | Identifies and perturbs the most salient features in the input space. |
| Evolutionary Algorithms (EA) | Utilizes genetic algorithms or differential evolution to search for adversarial examples. |
| Universal Adversarial Perturbations | Small perturbations are added to multiple input samples, causing misclassification with high probability. |
Real-world Examples of Adversarial Attacks
DeepLocker: IBM Research has developed DeepLocker, an intricate type of malware that leverages artificial intelligence (AI) to mask its harmful payload until predetermined criteria are fulfilled. This malware embeds itself within harmless applications and utilizes AI methodologies to elude detection by security systems. Upon activation, it releases its payload, presenting a formidable challenge for detection and defense. DeepLocker signifies a notable progression in cyberattacks, posing obstacles for conventional security protocols.
Stuxnet: In 2010, an intricate computer worm named Stuxnet was discovered. It was crafted to disrupt Iran’s nuclear program by targeting the centrifuges used for uranium enrichment. The worm spread through infected USB drives and network shares, exploiting zero-day vulnerabilities in Windows systems. Stuxnet managed to manipulate Siemens PLCs, which controlled the centrifuges, causing them to malfunction. Despite its creators remaining unidentified, there is a widespread belief that Stuxnet was a collaborative effort between the US and Israel. The impact of Stuxnet on Iran’s nuclear endeavors was considerable, serving as a demonstration of the potential of cyberweapons in contemporary warfare.
Google’s Speech Recognition Vulnerability: In 2017, researchers discovered a vulnerability in Google’s speech recognition system that allowed adversaries to embed hidden voice commands within audio recordings. Attackers could remotely control gadgets such as smart speakers or cell phones by tampering with the audio signals. This example demonstrates the potential security risks of adversarial attacks against voice recognition systems.
Conclusion
Adversarial machine learning represents a noteworthy challenge within the artificial intelligence discipline. The existence of adversarial attacks poses a significant threat to the dependability and security of machine learning models throughout diverse domains. Implementing effective defense mechanisms, including adversarial training and robust optimization, minimizes these risks. It is imperative that researchers collaborate and continuously innovate to address evolving threats proactively, thus ensuring the ongoing progress and responsible implementation of machine learning technologies.
FAQs
Q1. Does adversarial machine learning have any ethical or legal consequences?
Answer: Adversarial machine learning elicits significant legal and ethical inquiries, encompassing apprehensions about data privacy, algorithmic equity, and accountability for unforeseen ramifications. Attending to these deliberations is imperative to guarantee machine learning technologies’ responsible advancement and implementation.
Q2. Who are the potential perpetrators of adversarial attacks?
Answer: Adversarial attacks can be carried out by various actors, including cybercriminals, hackers, state-sponsored entities, and malicious insiders. The motivations for these attacks can vary, including financial gain, espionage, sabotage, or activism.
Q3. What are some emerging trends and future directions in adversarial machine learning research?
Answer: Emerging developments in adversarial machine learning research encompass the creation of resilient defense mechanisms, the investigation of adversarial transferability across various domains, the analysis of adversarial attacks in reinforcement learning and generative models, and the incorporation of security considerations into the foundational design of machine learning systems.
Q4. Is adversarial machine learning an ongoing area of research?
Answer: Yes, the field of adversarial machine learning is currently a dynamic and rapidly developing research area. Researchers are constantly creating fresh attack methods and defensive approaches to counter the advancing risks presented by adversarial attacks.
Recommended Articles
We hope that this EDUCBA information on the “Adversarial Machine Learning” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
