Updated December 5, 2023
Difference Between ASCII vs Unicode
Character encoding plays a crucial role in digital communication, and two prominent standards are ASCII (American Standard Code for Information Interchange) and Unicode. Developed in the 1960s, ASCII initially aimed at encoding English characters within a 7-bit system. However, as digital communication expanded globally, Unicode emerged in the 1990s, offering a comprehensive character set capable of representing diverse languages and symbols. Unlike ASCII’s limited scope, Unicode facilitates multilingual support, making it essential for modern applications and the internet. This brief introduction sets the stage for exploring the distinctions and applications of ASCII and Unicode in the digital landscape.
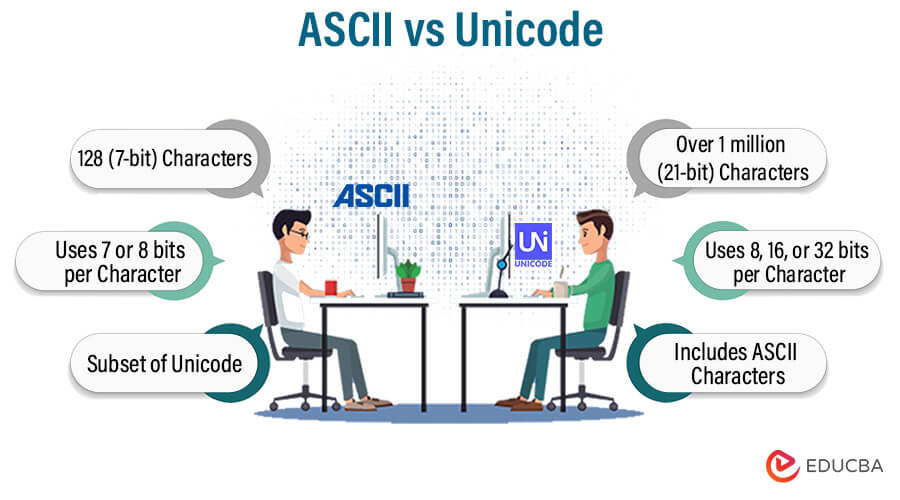
Table of Contents
- Difference Between ASCII vs Unicode
- What is ASCII?
- What is Unicode?
- Critical Differences Between ASCII vs Unicode
- Choosing Between ASCII and Unicode
What is ASCII?
The character encoding system ASCII (American Standard Code for Information Interchange) was created in the 1960s and laid the groundwork for early computers. It represents text using a 7-bit binary code, allowing the encoding of 128 characters, including English letters, numerals, and basic symbols. ASCII facilitates the communication and exchange of information between computers, serving as a universal encoding system for various devices and applications. However, its limitation to English characters posed challenges in multilingual environments. Despite its historical significance, Unicode has primarily surpassed ASCII, which offers a broader character set, accommodating the global diversity of languages and symbols in modern digital communication.
Origin and History of ASCII
American Standard Code for Information Interchange has its roots in the early years of computing and telecommunication. The development of ASCII can be traced back to the American Standards Association (ASA), which later became the American National Standards Institute (ANSI).
- Early Computing Needs (1960s): ASCII was developed in the early 1960s to standardize character encoding for computers and communication equipment. Before ASCII, various incompatible encoding systems were in use, causing interoperability issues.
- Committee Formation: To address the lack of standardization, a committee was formed by ASA in 1961, led by Robert W. Bemer. This committee worked to create a unified encoding system that could be adopted across different computer systems.
- 7-Bit Encoding: The ASCII standard was first published in 1963, defining a 7-bit binary code that allowed for the representation of 128 characters, including uppercase and lowercase letters, numerals, punctuation, and control characters.
- Widespread Adoption: ASCII quickly gained popularity due to its simplicity and became widely adopted in computer systems, communication protocols, and early programming languages. Its success contributed to the interoperability of systems and the growth of digital communication.
- Standardization by ANSI: In 1967, the ASCII standard was officially adopted by ANSI (American National Standards Institute), solidifying its status as the standard character encoding system in the United States.
- Global Impact: While ASCII was initially designed for English-language characters, its influence extended globally. Many early computer systems worldwide adopted ASCII as the de facto standard for character encoding. However, its limitations in representing non-English characters became apparent as the need for internationalization grew.
- Legacy and Transition: Even as more advanced character encoding systems like Unicode emerged to address the limitations of ASCII, the ASCII standard continues to influence computing and programming, especially in legacy systems and specific application domains.
Character Set of ASCII
| Decimal | Binary | Octal | Hexadecimal | Character |
|
0 |
0 | 0 | 0 |
NUL |
|
1 |
1 | 1 | 1 |
SOH |
|
2 |
10 | 2 | 2 |
STX |
|
3 |
11 | 3 | 3 |
ETX |
|
4 |
100 | 4 | 4 |
EOT |
|
5 |
101 | 5 | 5 |
ENQ |
|
6 |
110 | 6 | 6 |
ACK |
|
7 |
111 | 7 | 7 |
BEL |
|
8 |
1000 | 10 | 8 |
BS |
|
9 |
1001 | 11 | 9 |
HT |
|
10 |
1010 | 12 | 0A |
LF |
|
11 |
1011 | 13 | 0B |
VT |
|
12 |
1100 | 14 | 0C |
FF |
|
13 |
1101 | 15 | 0D |
CR |
|
14 |
1110 | 16 | 0E |
SO |
|
15 |
1111 | 17 | 0F |
SI |
|
… |
… | … | … |
… |
| 127 | 1111111 | 177 | 7F |
DEL |
Challenges of ASCII
While ASCII has been foundational in the history of computing, it comes with several significant challenges as technology and communication evolve. Here are some of the key challenges associated with ASCII:
- Limited Character Set: ASCII has a 7-bit encoding system, allowing for the representation of only 128 characters. This limitation is particularly restrictive in multilingual environments where non-English characters are prevalent.
- English-Centric: Originally designed for English-language characters, ASCII needs help accommodating other languages’ diverse characters and symbols, hindering internationalization efforts.
- No Support for Special Characters: ASCII lacks representation for special characters, mathematical symbols, and diacritical marks commonly used in various contexts, limiting its applicability in fields such as mathematics and science.
- Multilingual Challenges: In multilingual environments, ASCII’s inability to handle characters from different scripts and languages makes global communication and information exchange impractical.
- Compatibility Issues: As technology advanced and global communication expanded, the limitations of ASCII became apparent, leading to compatibility challenges in systems that required support for a broader range of characters.
- Unicode Adoption: The emergence of Unicode, offering a comprehensive character set for internationalization, has overshadowed ASCII in modern computing, leading to a transition away from ASCII in favor of more versatile encoding standards.
What is Unicode?
Unicode is a character encoding standard that addresses the limitations of ASCII, providing a universal representation of text in almost all known writing systems. Introduced in the 1990s, Unicode employs a unique code point for each character, encompassing many symbols, scripts, and languages. Unlike ASCII, Unicode accommodates multilingual content and special characters, facilitating seamless communication and information exchange in the global digital landscape. It has become the foundation for modern computing, enabling software and systems to handle diverse linguistic and cultural expressions. It is an essential component for internationalization and the development of multilingual applications.
Origin and History of Unicode
The origin and history of Unicode trace back to the need for a more versatile character encoding system that could address the limitations of existing standards like ASCII:
- Formation of Unicode Consortium (1987): The Unicode Consortium, founded in 1987, played a crucial role in developing the Unicode standard. The consortium comprised significant technology companies, including Apple, Microsoft, IBM, and Xerox.
- Motivation for Development: The limitations of ASCII became apparent as computing expanded globally. The need to represent a diverse range of characters, languages, and symbols in a standardized way led to the creation of Unicode.
- Unicode 1.0 (1991): The first version of Unicode, Unicode 1.0, was released in October 1991. It aimed to provide a universal character set by assigning unique code points to characters from various writing systems, encompassing scripts beyond the scope of ASCII.
- 16-Bit Encoding: Unicode initially used a 16-bit encoding system, allowing for the representation of 65,536 characters. This provided a significant expansion compared to the 128 characters supported by ASCII.
- Adoption and Growth: Unicode gained traction in the computing industry due to its comprehensive character set, facilitating multilingual support. Its adoption was crucial for standardizing character encoding in software development, operating systems, and the internet.
- Unicode Transformation Formats (UTF): Different UTFs, such as UTF-8, UTF-16, and UTF-32, were developed to handle the varying storage and transmission requirements of text in computing environments. UTF-8, in particular, became widely adopted due to its backward compatibility with ASCII.
- Continuous Updates: The Unicode Consortium releases updates to accommodate new characters and symbols. The standard’s dynamic nature ensures relevance in an ever-evolving linguistic and cultural landscape.
- Global Impact: Unicode has become the standard for character encoding worldwide. It is integral to internationalization efforts in software development, ensuring seamless communication across different languages and scripts.
Character Set of Unicode
| Code Point (Hex) | UTF-8 Encoding (Binary) | Character |
|
U+0020 |
100000 |
Space |
|
U+0021 |
100001 |
! |
|
U+0022 |
100010 |
“ |
|
U+0023 |
100011 |
# |
|
U+0024 |
100100 |
$ |
|
U+0025 |
100101 |
% |
|
U+0026 |
100110 |
& |
|
U+0027 |
100111 |
‘ |
|
U+0028 |
101000 |
( |
|
U+0029 |
101001 |
) |
|
U+002A |
101010 |
* |
|
U+002B |
101011 |
+ |
|
U+002C |
101100 |
, |
|
U+002D |
101101 |
– |
|
U+002E |
101110 |
. |
|
U+002F |
101111 |
/ |
|
U+0030 |
110000 |
0 |
| U+0031 | 110001 |
1 |
Challenges of Unicode
While Unicode is a powerful and widely adopted character encoding standard, it has challenges. Here are some key challenges associated with Unicode:
- Storage and Bandwidth: Unicode characters often require more storage space than ASCII characters, especially when using UTF-16 or UTF-32 encoding. This can impact storage requirements and increase bandwidth usage in network communication.
- Backward Compatibility: Transitioning from legacy systems using non-Unicode character sets to Unicode can be challenging. Legacy systems may not support Unicode, requiring careful migration strategies to ensure compatibility.
- Complexity: Unicode’s vast character set and support for multiple scripts make it complex. Implementing Unicode correctly in software and systems requires careful handling of various encoding forms (UTF-8, UTF-16, UTF-32) and consideration of normalization forms.
- Sorting and Searching: Sorting and searching algorithms become more complex with Unicode due to the diverse nature of characters. Different languages and scripts have unique sorting orders, making it challenging to develop universal sorting algorithms.
- Security Concerns: Unicode allows for the representation of visually similar characters, which can be exploited in security attacks, such as homograph attacks. These attacks use identical characters with different Unicode code points to deceive users.
- Font and Rendering Issues: Rendering characters correctly depends on font support. Some characters might not display as intended if the chosen font lacks support, leading to inconsistencies in visual representation.
- Compatibility with Legacy Systems: While Unicode aims to provide compatibility, some legacy systems may not fully support it. This can result in interoperability issues when exchanging data between modern Unicode-enabled systems and older systems that use different character encodings.
- Learning Curve: Developers and system administrators need to familiarize themselves with the complexities of Unicode to implement it effectively. This learning curve may be a hurdle for someone used to less complex character encoding schemes.
- Performance Overhead: Processing Unicode text, especially in languages like C or C++, can introduce performance overhead due to additional processing requirements for variable-length encoding schemes like UTF-8.
- Versioning and Updates: Unicode is a dynamic standard that evolves. Software and systems need to adapt to new versions of Unicode to support the latest characters and improvements, which can require ongoing maintenance.
Critical Differences Between ASCII vs Unicode
| Feature | ASCII | Unicode |
|
Number of Characters |
128 (7-bit) |
Over 1 million (21-bit) |
|
Character Range |
Primarily English characters |
Multilingual support |
|
Representation |
It uses 7 or 8 bits per character |
Uses 8, 16, or 32 bits per character |
|
Characters Covered |
Limited to basic Latin alphabet |
Covers a wide range of scripts, languages, symbols, emojis, etc. |
|
Internationalization |
Not well-suited for non-English languages |
Designed for global language support |
|
Size |
Fixed-size per character (7 or 8 bits) |
Variable size per character (8, 16, or 32 bits) |
|
Backward Compatibility |
ASCII is a subset of Unicode |
Unicode includes ASCII characters |
|
Encoding Schemes |
ASCII has limited encoding schemes (e.g., ASCII, UTF-8) |
Unicode supports various encoding schemes (UTF-8, UTF-16, UTF-32) |
| Memory Usage | Generally requires less memory |
It may require more memory due to variable encoding |
Choosing Between ASCII and Unicode
It is essential to base your selection between ASCII and Unicode on the particular needs of your application, system, or use case. Here are some considerations to guide your decision:
Choose ASCII when
- English-Only Content: ASCII might be sufficient if your application deals primarily with English text and doesn’t require characters from other languages or special symbols.
- Legacy Systems: In situations where you are working with legacy systems that only support ASCII or if constraints are preventing the adoption of Unicode, sticking with ASCII might be necessary.
- Storage and Bandwidth Constraints: ASCII may be preferred due to its minor character set and more straightforward encoding in scenarios where storage space or bandwidth is critical.
- Simplicity: ASCII can provide a straightforward solution for simpler applications with limited text processing needs and where multilingual support is not required.
Choose Unicode when
- Multilingual Support: If your application needs to support multiple languages, scripts, and symbols worldwide, Unicode is a clear choice. It ensures that text in various languages can be represented accurately.
- Internationalization (i18n): For applications that aim to be globally accessible and user-friendly, Unicode is essential for internationalization efforts. It allows seamless handling of diverse linguistic and cultural content.
- Modern Software Development: Unicode is the standard in contemporary software development, especially for web applications and systems targeting a broad user base. Most modern programming languages and platforms support Unicode natively.
- Compatibility and Future-Proofing: When dealing with modern systems and applications, choosing Unicode ensures compatibility with various platforms and technologies. It also future-proofs your application as the industry continues to move towards global standards.
- Symbol and Emoji Usage: If your application involves using symbols, emojis, or characters outside the ASCII range, Unicode is necessary for accurate representation.
Conclusion
The choice between ASCII and Unicode hinges on the application’s specific requirements. With its simplicity and English-centric focus, ASCII suits scenarios with limited language diversity and legacy constraints. However, Unicode has emerged as the preferred standard for modern applications, offering a comprehensive character set crucial for multilingual support and global accessibility. As the digital landscape becomes increasingly interconnected and diverse, Unicode is the foundation for internationalization. It ensures seamless communication across languages and cultures, making it indispensable in contemporary software development and communication technologies.
Recommended Article
We hope that this EDUCBA information on “ASCII vs Unicode” was beneficial to you. You can view EDUCBA’s recommended articles for more information,
