Updated February 18, 2023
Introduction to Avro Serialization
Avro serialization is the process of transferring the data orderly over the network. We can interpret data structure or entity position into a binary or descriptive form; such process is called the serialization in avro, and it is also called marshaling and deserialization in avro, which we can call unmarshalling. As we know, the avro is not dependent on the platform; it is schema-based and can utilize it to execute serialization and deserialization. Moreover, it can use JSON and binary formation for transformation.
Overview of Avro Serialization
The avro serialization converts data structures or state of the object within the binary or textual format to transform data for reserving on the persistent storage. If data has been transformed through the object, then that has to be deserialized once again. Which serialization is also called marshaling, and deserialization is called unmarshalling. The avro serialization is a schema-based data serialization collection; it also can perform the encoding, in which the encoder has been used to describe the format. It has two types of encoders, binary encoding and JSON encoding.
Avro Serialization Steps
Let us see how to serialize the data by using avro.
First, we must write the schema and save it with the ‘.avsc’ extension.
Example:
Code:
{
"namespace": "avro serialization",
"type": "record",
"name": "stud",
"fields": [
{"name": "name", "type": "string"},
{"name": "id", "type": "int"},
{"name": "marks", "type": "int"},
{"name": "percentage", "type": "int"},
{"name": "subject", "type": "string"}
]
}
After that, we have to compile the schema with the help of the avro utility; then, we will receive the data for communicating with the schema,
‘java -jar <path/to/avro-tools-1.7.7.jar> compile schema <path/to/schema-file> <destination-folder>’
After that, the terminal will open in the home folder, and a new directory can be generated with the help of the below command.
Code:
‘$ mkdir Avro_Work’,
In the new directory, we can also generate the sub-directories, in which we have the schema for keeping the schema, and another name will be ‘with_code_gen’ for storing the created code. Then we can able to store the jar files using jars named schema.
Code:
$ mkdir schema
$ mkdir with_code_gen
$ mkdir jars
The schema has been occupied with the data.
And then, it can be able to serialize with the help of the avro library.
Avro Serialization Types
There are two types of avro serialization:
1. Binary Encoding
The binary encoding has been utilized by using many applications, and it is faster than JSON, in which in binary encoding, the primitive data types have been encoded as:
- Zero bytes coded as null.
- A single-byte coded as Boolean has either 0 for false or 1 for true.
- Additionally, with the help of variable-length coded as int and long values should be written.
- For 4-byte, we have to write a ‘float,’ with the help of a method equivalent to Java’s floatToIntBits; the float can be transformed into a 32-bit integer encoded as a little-endian format.
- The UTF-8 character data has been encoded as character data, and a string is also encoded.
2. JSON Encoding
This encoding has been used for debugging and web-based applications; this encoding is similar as we can use the encode field for default values excluding the unions; in JSON, the value of a union can be encoded as:
- The JSON value is encoded as null if it has a null type.
- If the union can have value as pair, then it can be encoded as a JSON object in which the name is a type name, and the value will be encoded repetitively; we have to keep in mind for the avro name, we need to use the user-specified name.
For example, the union of schema is [“null,” “string,” “zoo”], in which zoo is the name of the record it can be encoded as:
1. Null as null.
2. The string “b” can be {“string”: “b”}.
3. The zoo can be encoded as {“zoo”: {…}}, where {…} can be JSON encoding.
4. The JSON encoding does not consider the dissimilarity between map and records.
- If we want to reserve a single avro serialized value for a long time, then we have to reserve the record for different avro records; we can encode the single value with the help of binary coding the object of avro can be encoded.
3. Deployment Avro Serialization
Let us see the deployment of the Debezium connector, which can utilize the avro serialization, for we have to perform three jobs.
- We have to deploy the Apicurio API and the schema registry examination.
- A plug-in directory has an installation package through it; we have to install the avro converter.
- After that, we have to configure the debezium connector to use the avro serialization by setting the configuration properties, which are given below.
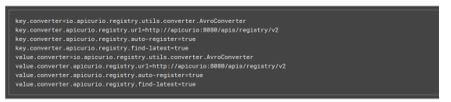
- Internally, Kafka can utilize the JSON value or JSON key every time for reserving the configuration and offsets.
- We can also deploy with Debezium Containers; we have to utilize the debezium image for deploying the debezium connectors, and the avro serialization can utilize that.
1. We have to deploy the registry of Apicurio in which we have to utilize the non-production, in-instance of the Apicurio registry:

2. We must run the Debezium container image to connect Kafka. Then it will give the avro connector by authorizing Apicurio through enabling variable, ‘ENABLE_APICURIO_CONVERTERS=true,’ which can be the environment variable.
Conclusion
In this article, we conclude that the avro is a schema-based data serialization application which is a fast process it can allow to serialize of the data in binary and JSON format, so this article includes the points related to the avro serialization that types of serialization and deployment of the avro serialization.
Recommended Articles
This is a guide to Avro Serialization. Here we discuss the introduction, overview, avro serialization steps, and types. You may also have a look at the following articles to learn more –
