Updated March 20, 2023

Introduction to AWS Kinesis
Amazon Kinesis is a platform to collect, process, and analyzes your streaming data in Amazon Web Services so you can get timely, scheduled or event-based insights of your data and take action according to insights and like all other services, AWS Kinesis offers capabilities of cost-effective process streaming data at pace and scale, with the flexibility of choosing the tools which suit your application requirements either its a video, audio, or any other application requires streaming data to be processed.
AWS Kinesis Services
Before moving to the services, let us first understand some terminologies used in Kinesis:
| Term | Definition |
| Data Record | Data unit stored in the data stream of Kinesis. It consists of a data blob, sequence number, and a partition key. |
| Shard | Set of the sequence of data records. The number of shards can be increased or decreased if the data rate is increased. |
| Retention Period | The time period in which the data can be accessed after it is added to the stream. Default Retention Period: 24 hours. |
| Producer | It feds data records into Kinesis Stream. |
| Consumer | It gets records from Kinesis Stream and processes them. |
Kinesis provides 3 core services.
They are as follows:
1. Kinesis Streams
Kinesis Stream consists of a set of sequences of data records known as Shards. These Shards have a fixed capacity that can provide a maximum read rate of 2 MB/second and a 1 MB/second writing rate. The maximum capacity of a stream is the sum of the capacity of each shard.
Working of Kinesis:
- Data produced by IoT and other sources, which are known as Producers, are fed into the Kinesis Streams for storing in Shards.
- This data will be available in Shard for a maximum of 24 hours.
- If it needs to be stored for more than this default time, the user can increase to a retention period of 7 days.
- Once the data reaches the Shards, EC2 instances can take this data for different purposes.
- EC2 instances that retrieve data are known as Consumers.
- After data processing, it is fed into one of the Amazon Web Services such as Simple Storage Service(S3), DynamoDB, Redshift, etc.
2. Kinesis Firehose
Kinesis Firehose helps move data to Amazon web services such as Redshift, Simple Storage Service, Elastic Search, etc. It is a part of the streaming platform that does not manage any resources. Data producers are configured such that data have to be sent to Kinesis Firehose, and it then automatically sends it to the corresponding destination.
Working of Kinesis Firehose:
- As mentioned in the working of AWS Kinesis Streams, Kinesis Firehose also gets data from producers such as mobile phones, laptops, EC2, etc. But, this does not have to take data into shards or increase retention periods like Kinesis Streams. It is because Kinesis Firehose does it automatically.
- The data is then analyzed automatically and fed into Simple Storage Service.
- Since there is no retention period, data have to be either analyzed or send to any storage depends on the user’s requirement.
- If data has to be sent to Redshift, it must first be moved to Simple Storage Service and need to copy to Redshift from there.
- But, in Elastic Search, data can be directly fed into it, similar to Simple Storage Service.
3. Kinesis Analytics
Kinesis Firehose permits to run of the SQL queries in the data that is present in Kinesis Firehose. Using this SQL queries, data can be stored in Redshift, Simple Storage Service, ElasticSearch, etc.
AWS Kinesis Architecture
Given below is the AWS kinesis architecture:
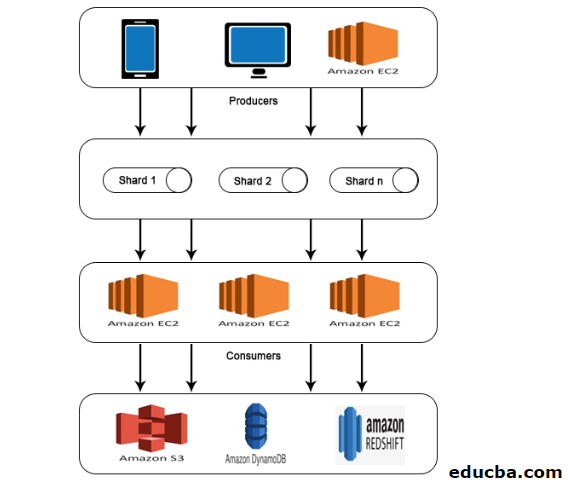
AWS Kinesis Architecture consists of:
- Producers
- Shards
- Consumers
- Storage
Similar to the working explained in AWS Kinesis Data Stream, data from Producers is fed into Shards where data is processed and analyzed. The analyzed data is then moved to EC2 instances for performing certain applications. Finally, data will be stored in any of the Amazon web services such as S3, Redshift, etc.
How to Use AWS Kinesis?
To work with AWS Kinesis, the following two steps need to be done:
1. Install the AWS Command Line Interface (CLI)
Installing the command-line interface is different for different Operating Systems. So, install CLI based on your operating system.
For Linux users, use the command sudo pip to install AWS CLI.
Make sure you have a python version 2.6.5 or higher. After downloading, configure it using AWS configure command.
Then, the following details will be asked, as shown below.
AWS Access Key ID [None]: #########################
AWS Secret Access Key [None]: #########################
Default region name [None]: ##################
Default output format [None]: ###########
For Windows users, Download the appropriate MSI Installer and run it.
2. Perform Kinesis Operations Using CLI
Please note that Kinesis data streams are not available for AWS free tier. So, Kinesis streams created will be charged.
Now let us see some kinesis operations in CLI.
- Create Stream
Create a stream KStream with Shard count 2 using the following command.
Code:
aws kinesis create-stream --stream-name KStream --shard-count 2
Check whether the stream has created.
Code:
aws kinesis describe-stream --stream-name KStream
If it is created, an output similar to the following example will have appeared.
Output:
{
“StreamDescription”: {
“StreamStatus”: “ACTIVE”,
“StreamName”: ” KStream “,
“StreamARN”: ####################,
“Shards”: [
{
“ShardId”: #################,
“HashKeyRange”: {
“EndingHashKey”: ###################,
“StartingHashKey”: “0”
},
“SequenceNumberRange”: {
“StartingSequenceNumber”: “###################”
}
}
]
}
}
- Put record
Now, a data record can be inserted using the put-record command. Here, a record containing a data test is inserted into the stream.
Code:
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
If the insertion is successful, the output will be displayed, as shown below.
Output:
{
“ShardId”: “#############”,
“SequenceNumber”: “##################”
}
- Get Record
First, the user needs to get the shard iterator representing the stream’s position for the shard.
Code:
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Then, run the command using the shard iterator obtained.
Code:
aws kinesis get-records --shard-iterator ###########
A sample output will be obtained, as shown below.
Output:
{
“Records”:[ {
“Data”:”######”,
“PartitionKey”:”456”,
“ApproximateArrivalTimestamp”: 1.441215410867E9,
“SequenceNumber”:”##########”
} ],
“MillisBehindLatest”:24000,
“NextShardIterator”:”#######”
}
- Clean Up
To avoid charges, the created stream can be deleted using the below command.
Code:
aws kinesis delete-stream --stream-name KStream
Conclusion
AWS Kinesis is a platform that collects, processes, and analyses streaming data for several applications like machine learning, predictive analytics, etc. Streaming data can be of any format such as audio, video, sensor data, etc.
Recommended Articles
This is a guide to AWS Kinesis. Here we discuss how to use AWS Kinesis and also its service with working and architecture. You may also look at the following article to learn more –

