Updated March 17, 2023
Introduction to Azure Data Factory Architecture
The Azure data factory architecture shows how we perform incremental loading in the transform pipeline and extract load. It will use the Azure Data Factory to automate the ELT pipeline. The azure data factory pipeline is incrementally moving the latest OLTP data from the SQL database server to the azure synapse. Transactional data is transformed into table analysis modular data. Azure data factory is a service that is managed.
Key Takeaways
- Azure data factory is used to create and schedule the data-driven workflows; we are using the same for ingesting the data from multiple data stores.
- Azure data architecture is nothing but a collection of tools and services which was enabling the process and collect data by using cloud computing.
Azure Data Factory Architecture Pipeline
As we all know, an Azure Data Factory is a logical group of activities used to coordinate a task. At the time of publication, the pipeline is either in continuous integration and delivery into git mode or directly into live mode. When we run an automated ELT or ETL process, it will be more efficient to load the changes that were previously run.
The below figure shows the azure data factory pipeline architecture as follows:
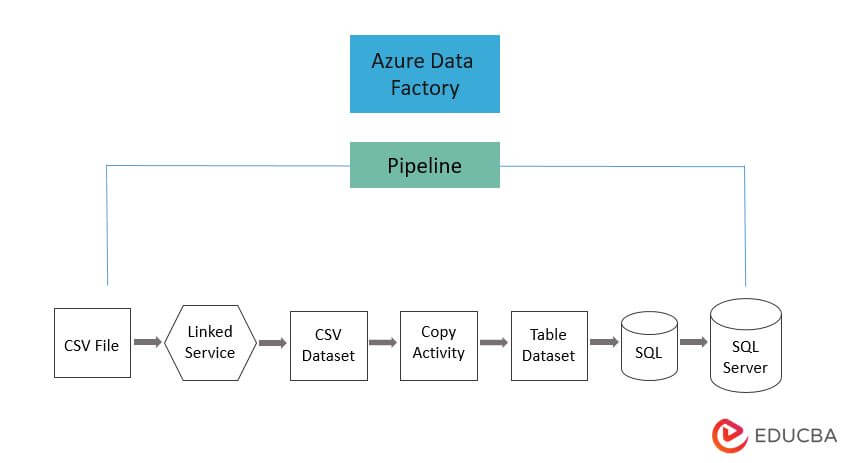
The synapse workspace or data factory contains one or more pipelines. It contains the logical group of activities used to perform the task. The pipeline contains the set of activities that were ingesting and cleaning the log data, and then it will kick off the flow of mapping data that was used to analyze the log data.
Azure data factory pipeline manages the activity in a set. We can schedule and deploy the pipeline instead of doing the same independently. Azure synapse analytics and azure data factory contain three grouping of activities like data transformation, data movement, and control activities. The activity takes zero or multiple inputs.
The below figure shows the relationship between pipelines as follows:
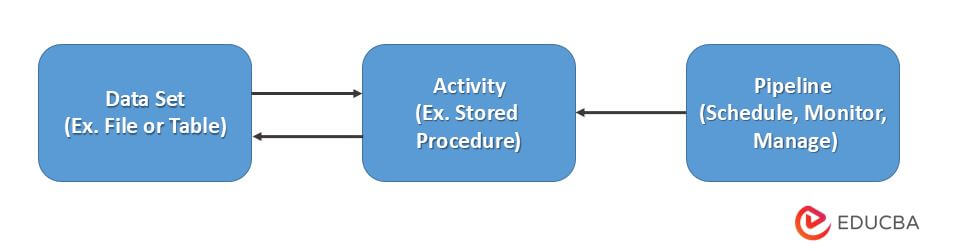
The activity in the pipeline defines actions to be performed on our data. We are using the copy activity to copy data from the SQL server to the Azure BLOB storage. We are using the data flow activity or databricks. Notebook activity is used to process and transform data from blob storage to the analytics tool Azure Synapse.
Azure Data Cloud Factory Architecture
We can realize tremendous cost savings, flexibility, scalability, and performance gains by migrating our SQL server database to the cloud. While reworking the ETL process and building while SQL server integration is a migration roadblock. The load process requires the use of specific data tool components as well as complex logic, which is supported by Azure Data Factory.
One of the most commonly used SSIS capabilities is the fuzzy grouped transformation, which was used in a CDC. We require a hybrid ETL approach to facilitate the migration of shift and lift for existing SQL databases. The data factory is required as the primary orchestration engine in the hybrid approach.
SSIS will contain the ETL tool for multiple SQL servers for loading and data transformation. In multiple times third-party plugins and SSIS features accelerate the development effort. Basically, customers are looking for low impact approach while migrating the database.
Below are several on-premises use cases as follows:
- Load the logs of the network router for the analysis of databases.
- Prepare the employment of human resources for the reporting, which was analytical.
- Load the sales and product data into the sales forecasting and data warehouse.
- Automate a load of data warehouse and operational data stores for accounting and finance.
- Automate the process of pipeline.
The below figure shows azure cloud data factory architecture as follows. This architecture is divided into two parts.
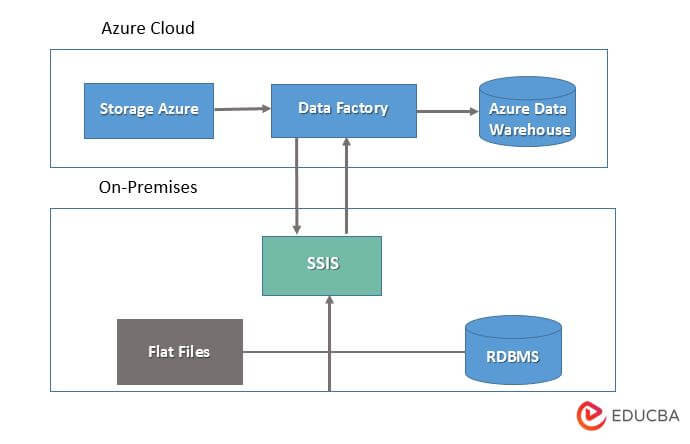
In the above example, the data flow from blob storage to the data directory. The data factory pipeline calls a stored procedure to execute an SSIS job that was hosted on-premises. The data cleansing jobs were run to prepare the data for downstream consumption. When the data cleansing task is successfully completed, the copy task is executed while the data is being loaded and cleaned onto the Azure cloud.
Blob storage is used to store files and data from the data factory. SQL integration service will make use of an on-premises ETL package that was used to execute the specific loads. Azure data factory is a cloud orchestration engine that collects data from a variety of sources.
Microsoft Azure Data Factory Architecture
The solution of the azure data factory is represented by the azure data factory architecture. The Azure data factory diagram allows us to design data-driven workflows that orchestrate data movement and transformation at scale. The workflows are created and scheduled using Azure Data Factory.
The azure data factory adds the below features, which were important to the scenario of warehousing.
The below example shows the architecture of the azure data factory as follows:
- Data factory pipeline automation.
- Incremental loading.
- Load the binary data like images and geospatial data.
- Integrate multiple data sources.
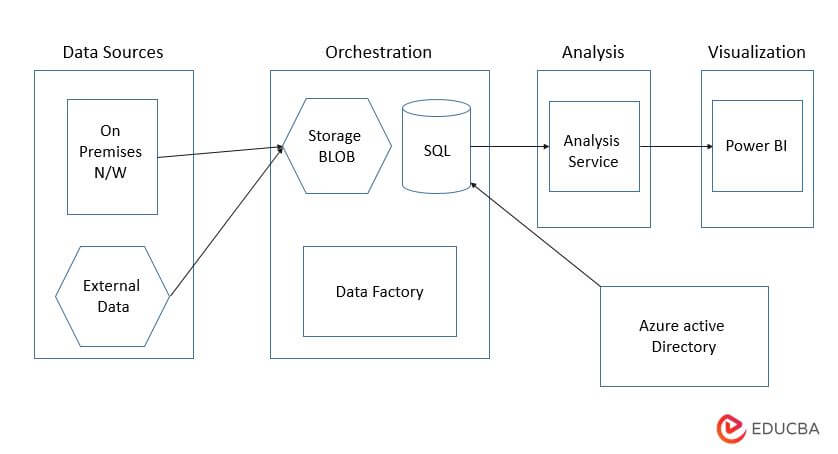
The azure data factory architecture consists of the following components and services as follows:
- Data sources – The source data is located on the SQL server. For stimulating the environment of on-premises, provision of deployment script is installed.
- External data – The data warehouse common scenario will integrate the multiple scenarios. The reference architecture loads the external dataset, which contains the data from OLTP database.
- Blob storage – Blob storage is used as a staging area for the data source before it is loaded into the Azure Synapse.
- Azure synapse – This is a distributed system that was used to perform analytics on large amounts of data. It will support parallel processing, which is appropriate for parallel processing.
- Azure data factory – It is managed service which was used to automate data movement and data transformation.
- Azure analysis service – It is a fully managed service which was providing the data modeling capabilities. Semantic model is loaded by using an analysis service.
- Power BI – It is a suite of business analytics tools that were used to analyze the data for business insights.
- Azure active directory – This is used to authenticate the users who were connecting to the analysis services through BI.
The architecture shows how we load data using the Azure Data Factory pipeline. This is used for automating the ELT pipeline using Azure Data Factory. The data is being transferred from an on-premises SQL server database to an Azure synapse via the pipeline.
FAQs
Given below are the FAQs mentioned:
Q1. What is the use of azure data factory?
Answer: It is a managed azure cloud service that was designed to extract and transform the load into the project of data integration.
Q2. What is the use of data sources component in an azure data factory architecture?
Answer: The source data is located in SQL server on-premises database. We are stimulating the same from on-premises to the azure cloud by using data sources.
Q3. Which authentication method are we using in azure data factory architecture?
Answer: We are using the azure active directory for authenticating the user who is connecting to the analysis services through Power BI.
Conclusion
The Azure data factory diagram allowed us to design data-driven workflows that orchestrated data movement and transformation on a large scale. The Azure data factory architecture demonstrates how incremental loading is performed in the transform pipeline and extract load. The azure data factory will be used to automate the ELT pipeline.
Recommended Articles
This is a guide to Azure Data Factory Architecture. Here we discuss the introduction, azure data factory architecture pipeline, and Microsoft azure data factory architecture. You can also look at the following articles to learn more –

