Updated March 17, 2023
Introduction to Azure Data Factory Pipeline
Azure data factory pipeline is a logical grouping of activities that we use to complete a task. The pipeline is the collection of activities that were used to ingest and log the data. It allows us to manage activities as a group rather than individually. Instead of acting separately, we can deploy and schedule the pipeline; activities within the pipeline define action.
Key Takeaways
- We are using data flow for notebook data bricks activity to transform and process the data from blob storage to the synapse analytics pool of azure.
- It takes inbound data from the folder of Data Lake and moves the same into archive storage.
What is Azure Data Factory Pipeline?
We are using an Azure Data Factory pipeline to copy data from the SQL server to azure BLOB storage. Azure Synapse Analytics and Azure Data Factory contain three types of activities i.e. control activities, data transformation activities, and data movement activities.
The pipeline activity’s input is represented by the input dataset. Azure data factory is an orchestrator and ETL that is part of the Microsoft Azure cloud. The Azure data factory collects data from the outside and transforms it for delivery to another location. It is a high-level concept with which we are working. Pipelines are made up of various activities, and data flow arrows.
How to Create Azure Data Factory Pipeline?
To create the azure data factory pipeline, we need access to the Azure portal.
Below steps shows how we can create the azure data factory pipeline as follows:
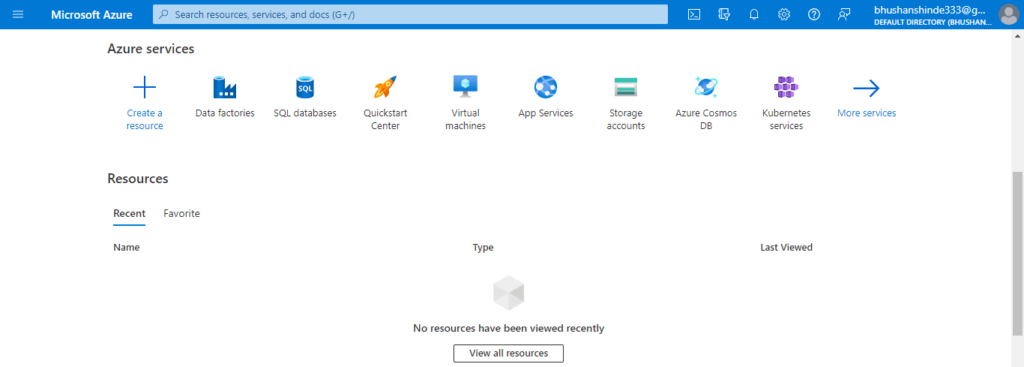
1. In the first step, we login into the Azure portal by using the specified credentials of the azure portal as follows.
2. After logging in to the Azure portal, we need to click on create a resource tab to create the azure data factory.
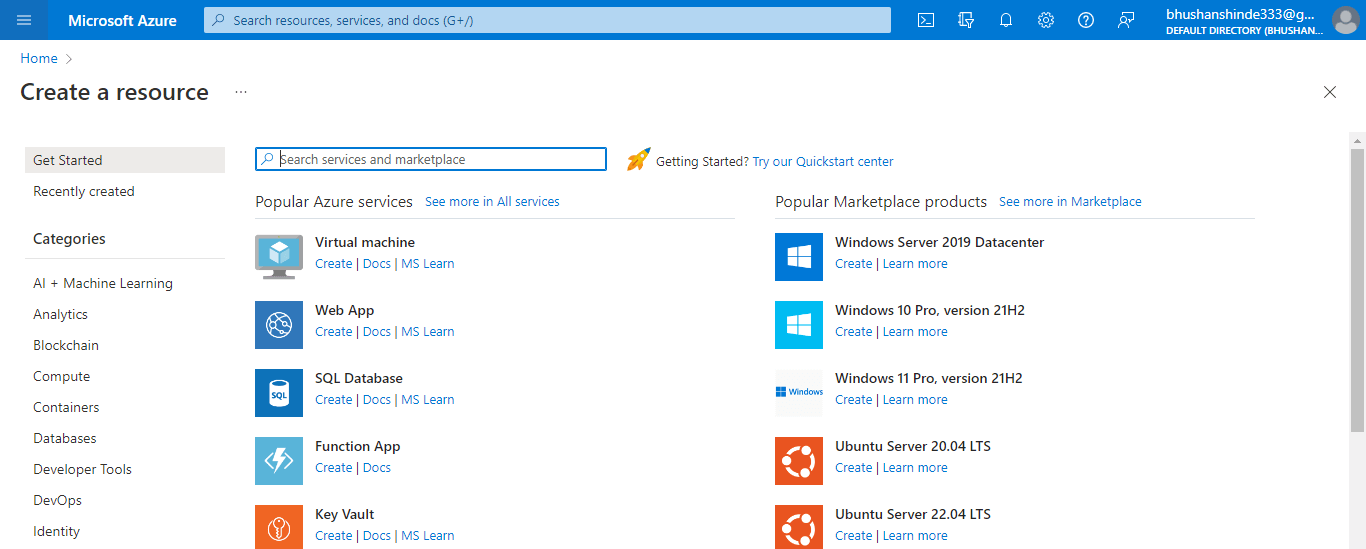
3. After clicking on create resource tab now in this step we need to select the integration and in that we need to select the data factory as follows.

4. After selecting the data factory now in this step we are creating the data factory name as tevpro-adf.
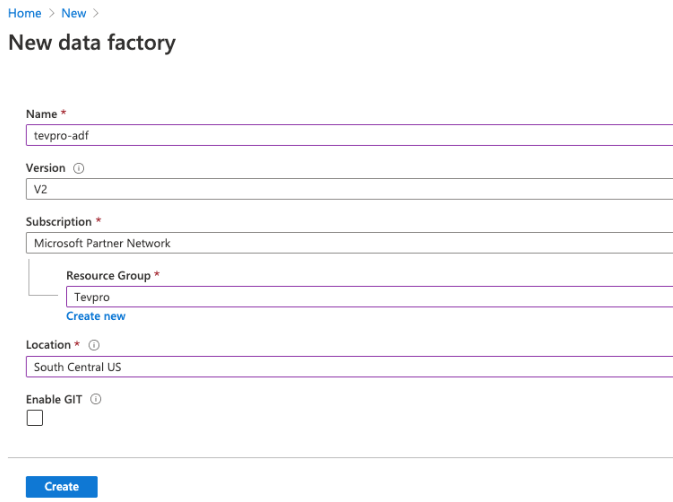
5. After clicking on create button we can see that our azure data factory is created. We can check the same by clicking on the same.
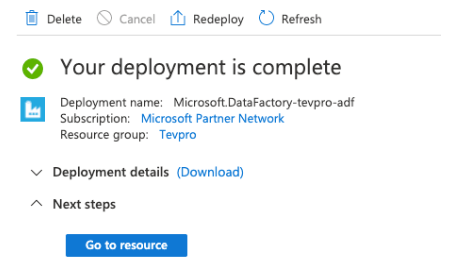
6. After creating the azure data factory now, we need to create the azure data factory pipeline. we need to click on the author and monitor options as follows.
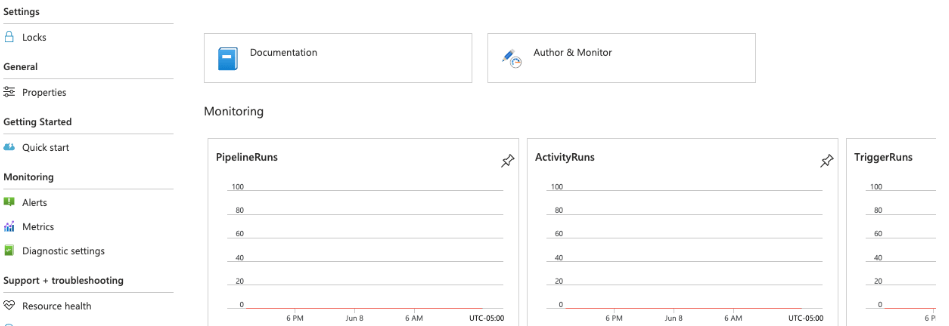
7. After clicking on the author and monitor tab the below page will open where we need to click on create a pipeline to create the new pipeline as follows.
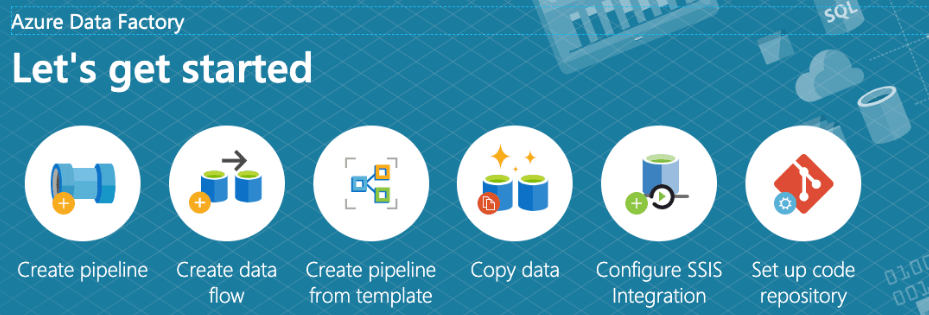
8. After clicking on create pipeline tab, we will create and rename the pipeline as follows.
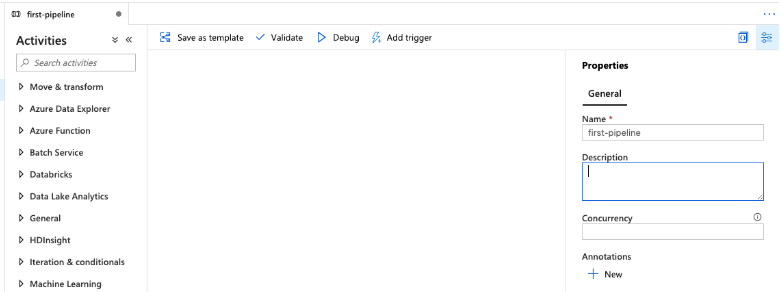
9. After renaming the pipeline now in this step we are copying the data from the specified pipeline as follows.
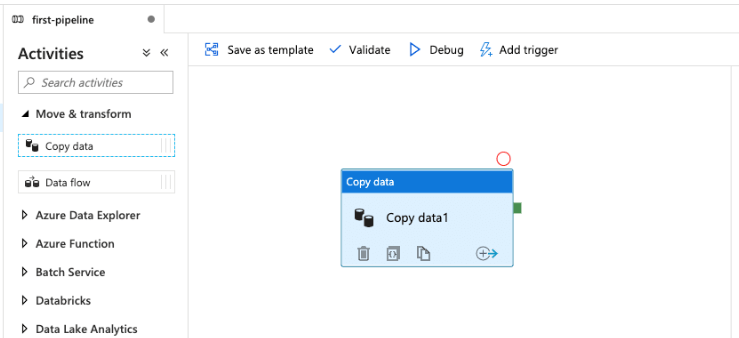
10. After copying the data from the pipeline now in this step we setup the source, for this setup we are configuring the API endpoint.
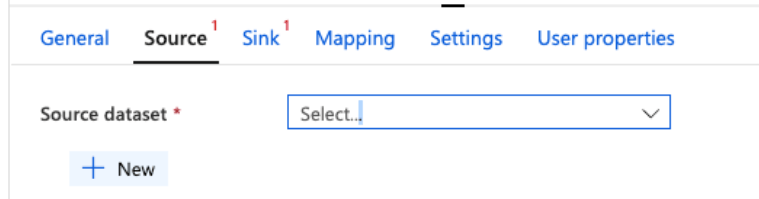
11. After clicking on the new source dataset, the below window opens. From this window, we need to select the REST options.

12. After selecting the source dataset options now, in this step, we configure the connection information for the specified dataset.
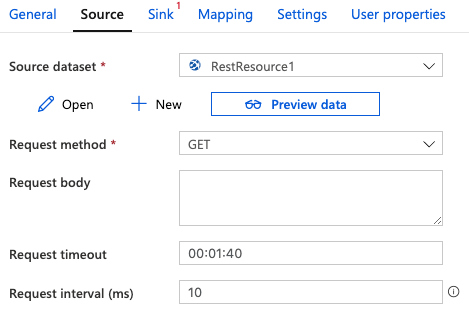
13. After defining the connection information now in this step we are creating a new linked service as follows.

14. After setup of the linked service now in this step we can preview the data by clicking on the preview data options as follows.
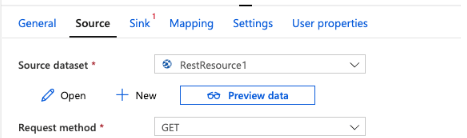
15. After previewing the data we will set up the sink target as follows.
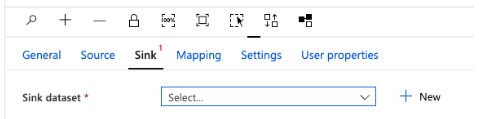
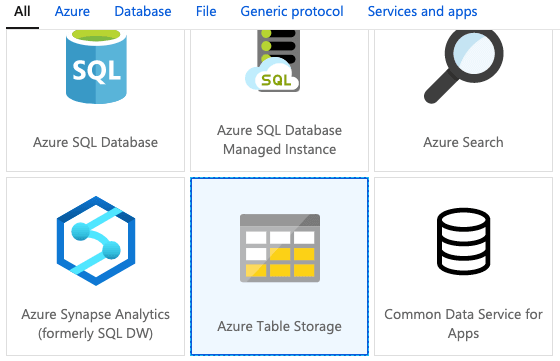
16. When we click on the new sink dataset, the window below opens, and we click on azure table storage as shown below.
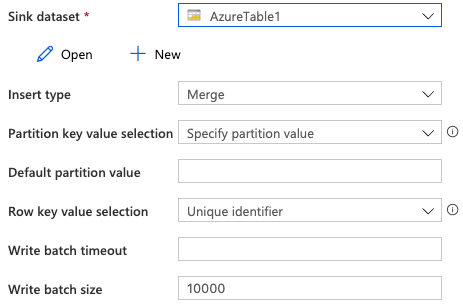
17. After selecting the sink dataset now, in this step, we create the sink dataset.
18. After creating the sink dataset, now in this step, we are checking the sink of the azure table as follows.
19. After checking the data sync, now in this step we are doing the dataset mappings as follows.
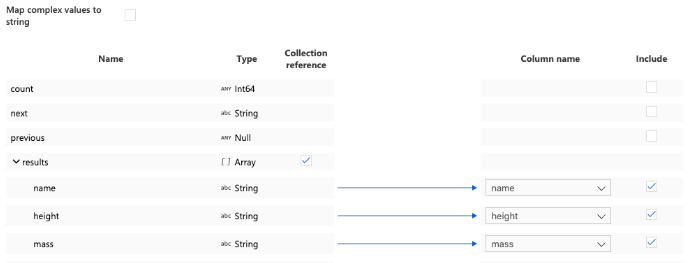
20. After mapping, now in this step we are validating and publishing the test as follows.
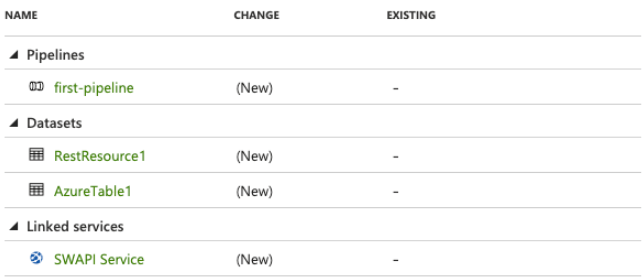
Azure Data Factory Pipeline ADF
Azure data factory is the commonly used service which is used to construct the data pipeline for jobs. Below steps shows how we can run the azure data factory pipeline with airflow as follows:
1. In the first step, we login to the Azure portal by using the specified credentials of the Azure portal.
2. After login into the azure portal, we need to go to the active directory and need to click on registered apps as follows.
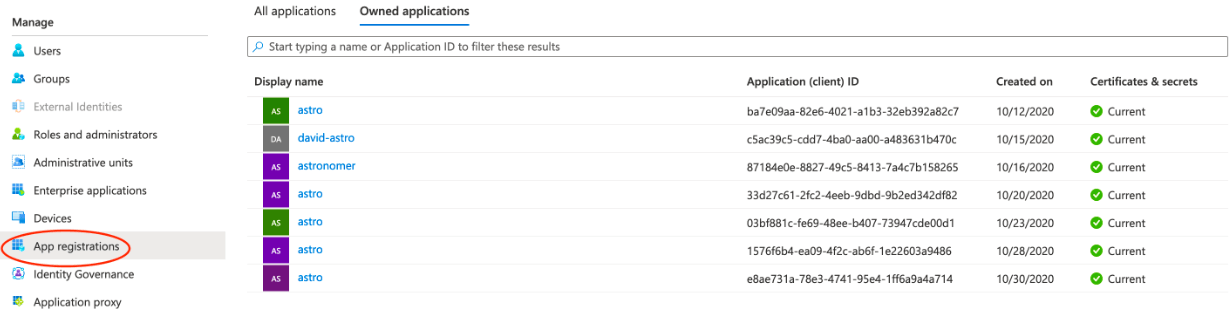
3. After opening the registered apps now, in this step we open the app which was associated with the client ID.

4. After opening the app now, in this step, we are creating the new client secret as follows.
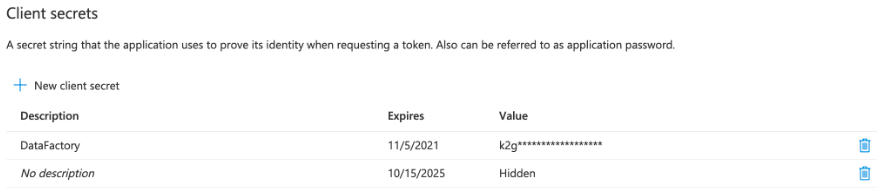
5. After creating the client secret now, in this step, we are opening the access control and add the role assignments.
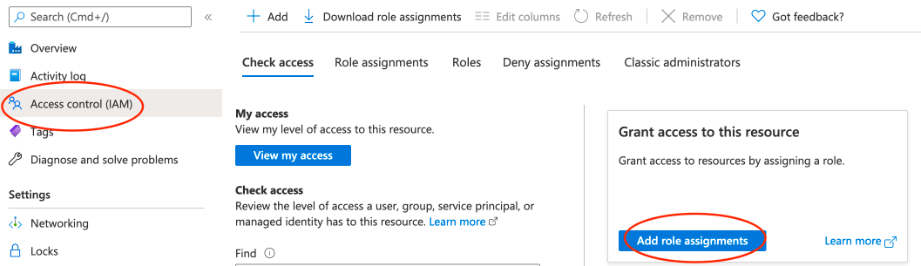
6. After clicking on role assignment we are adding the role assignment as shown below.

7. After adding the role assignment now we are creating a new astro project as follows.
Command:
mkdir astro-adf-tutorial && cd astro-adf-tutorial
astro dev initOutput:
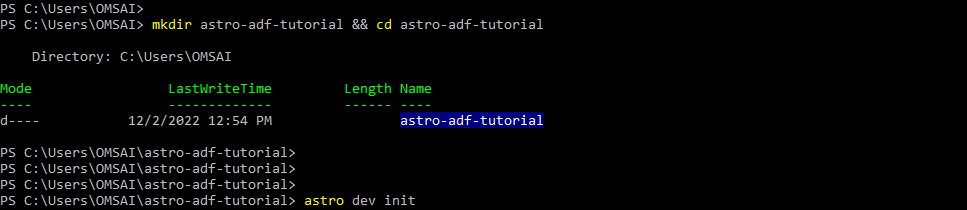
8. After creating the astro project we are executing the below command to start the project.
Command:
astro dev startOutput:
9. After starting the project now in this step, we create a new folder in the astro project, and in that, we create the adf-pipeline.py file and add the below code in it.
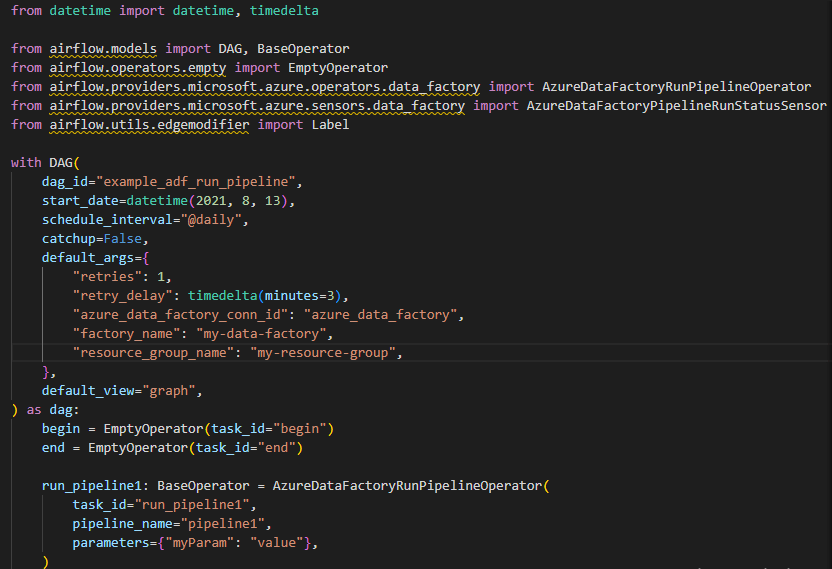
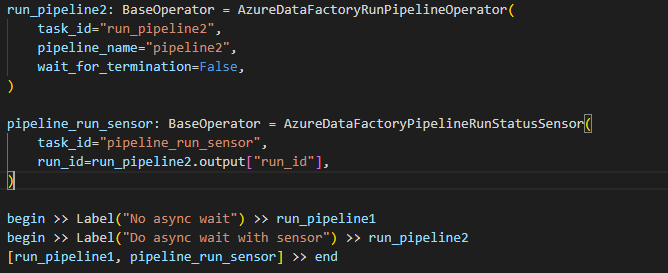
10. After adding the code in the adf-pipeline.py file now, in this step, we are running the DAG for executing the pipelines of ADF.
Azure Data Factory Pipeline Configuration
We are using the source-sink pattern in the azure data factory pipeline configuration in the data movement activities. In azure data factory, we are using the copy activity to copy the data entity from one location to another location.
The below steps show how we can configure it.
1. In the first step, we are creating the sink datasets and generic sinks for configuring the azure data factory pipeline as follows.
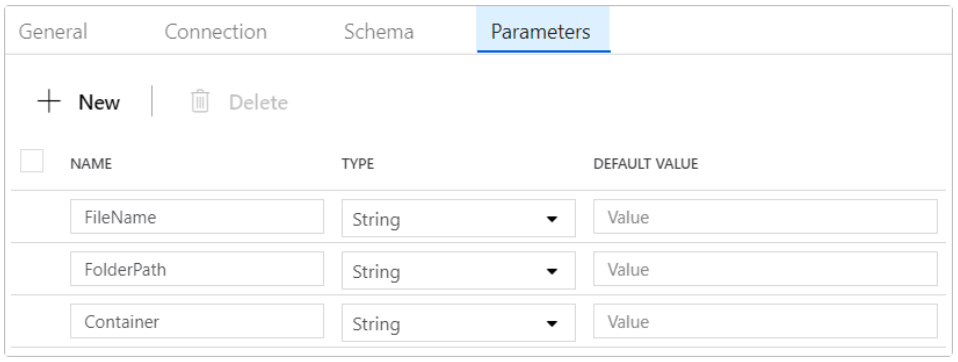
2. After configuring the sink dataset now in the below example, we are configuring the generic sinks as follows.

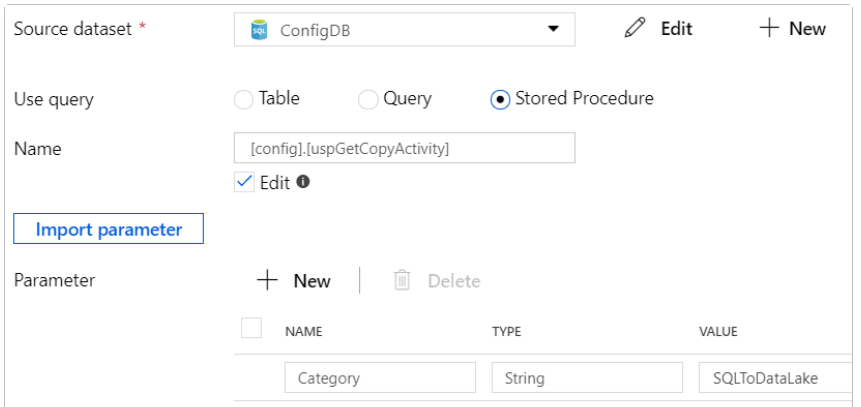
3. After configuring the generic sinks, now in this step, we are using lookup activity for fetching the source-sink settings as follows.
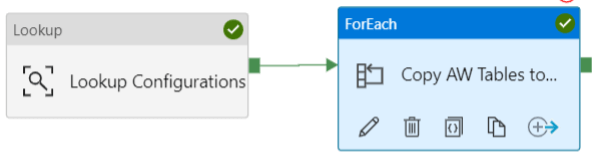
4. After using the lookup activity, now we are using data entities to copy the data as follows.
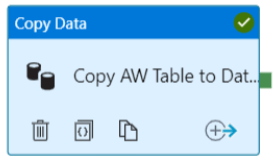
5. After using the data entities, we are adding the copy activity of generic as follows.
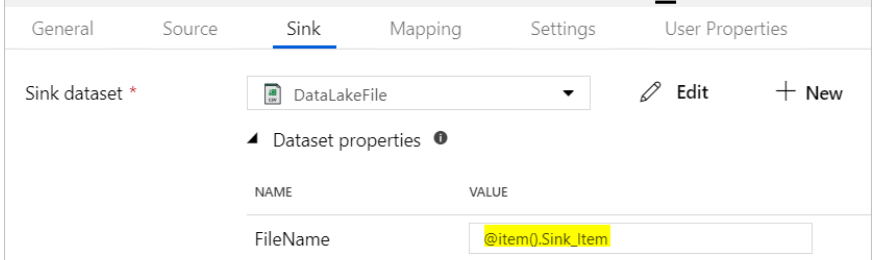
Conclusion
We are using an Azure Data Factory pipeline to copy data from the SQL server to Azure BLOB storage. It is a logical grouping of activities that we use to complete a task. The pipeline is a collection of activities that were used to ingest and log data.
Recommended Articles
This is a guide to Azure Data Factory Pipeline. Here we discuss the introduction, how to create an azure data factory pipeline, and configuration. You can also look at the following articles to learn more –

