Introduction to BeautifulSoup find by class
BeautifulSoup find by class package that extracts information from HTML and XML files. It integrates with our preferred parser to offer fluent navigation, searching, and modification of the parse tree. As a result, it frequently saves programmers hours or even days. BeautifulSoup extracts meaningful information from web pages, HTML, and XML files to get the most out of publicly available data.

Table of Contents
- Introduction
- Overview
- How to find by class in BeautifulSoup?
- Examples
- BeautifulSoup find by class Elements
Overview of BeautifulSoup find by class
- Web scraping is quite valuable. Data from various sources, including websites, are required by everyone. We are using the BeautifulSoup library to parse HTML in this tutorial. BeautifulSoup package, extracting vital data much more straightforward.
- It is a Python program that can be quickly installed on our computer using Python’s pip utility.
- BeautifulSoup package aids in parsing and extracting information from HTML documents. It allows us to navigate, search, and extract data from an HTML file.
- Tags make up HTML. It keeps all of its data among that mess, which is the information we require. If we discover the correct titles, we can retrieve what we need.
- The search and find all methods in BeautifulSoup are used. The locate method finds the first tag with the required name and produces a bs4 element object.
- The find all method, on the other hand, specified tag name and returned a list of bs4 element tags result set because all the entries in the list are of the type bs4.element.
- Scraping data from websites is known as web data extraction. Several Python libraries are available, ranging from the basic BeautifulSoup to the more complex Scrapy, which includes scrawling and other capabilities. Because we only require simple web scraping to utilize BS4.
How to find by class in BeautifulSoup?
BeautifulSoup allows us to search for an HTML element by its class. The select method can search by class, with the class name as an input. This method applies a CSS Selector to the parsed page and returns all elements that match the criteria.
The below steps show how to find by class in BeautifulSoup:
Step 1: In this step, we are installing the bs4 package by using the pip command. The bs4 package is used to import all the BeautifulSoup modules. In the below example, we have already installed the bs4 package in our system, so it will show that the requirement is already satisfied, and then we do not need to do anything.
Code:
pip install bs4
Output:
Step 2: After installing the bs4 package in this step, we create the HTML page. We have created the below HTML page to find BeautifulSoup by class as follows.
Code:
<html>
<head>
<base href = 'http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id = 'images'>
<a href = 'image1.html'>Image 1 <br /><img src = 'image1_thumb.jpg' /></a>
<a href = 'image2.html'>Image 2 <br /><img src = 'image2_thumb.jpg' /></a>
<a href = 'image3.html'>Image 3 <br /><img src = 'image3_thumb.jpg' /></a>
<a href = 'image4.html'>Image 4 <br /><img src = 'image4_thumb.jpg' /></a>
<a href = 'image5.html'>Image 5 <br /><img src = 'image5_thumb.jpg' /></a>
</div>
</body>
</html>
Output:
Step 3: After creating the HTML code in this step, we open the Python shell using the python3 command.
Code:
python3
Output:

Step 4: After opening the Python shell, We import the beautifulsoup and request modules. We are importing the beautifulsoup module using the bs4 package as follows.
Code:
from bs4 import BeautifulSoup
import requests
Output:
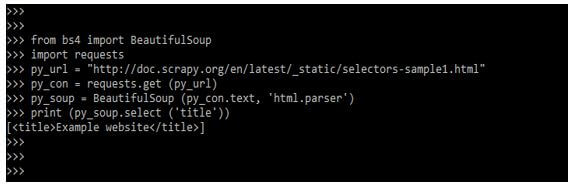
Step 5: After importing the beautifulsoup, os, and requests modules in this step, we are checking how to find beautifulsoup by class as follows.
Code:
from bs4 import BeautifulSoup
import requests
py_url = "http://doc.scrapy.org/en/latest/_static/selectors-sample1.html"
py_con = requests.get (py_url)
py_soup = BeautifulSoup (py_con.text, 'html.parser')
print (py_soup.select ('title'))
Output:
Examples of BeautifulSoup find by class
The below example shows BeautifulSoup by category by using the find_all method.
Example #1
Code:
from bs4 import BeautifulSoup
import requests
py_url = "http://doc.scrapy.org/en/latest/_static/selectors-sample1.html"
py_con = requests.get (py_url)
py_soup = BeautifulSoup (py_con.text, 'html.parser')
print (py_soup.find_all ('image_thumb.jpg'))
Output:
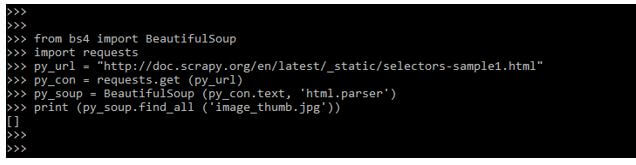
- In the above example, we can see that we have imported the bs4 and requests modules. After importing the module, we use the HTML page URL we created.
- After using the URL, we have to access this URL by using the requests and get method. Then, we print the title of an HTML web page using the beautifulsoup find method.
Example #2
The below example shows that beautifulsoup by class by using the select method.
Code:
from bs4 import BeautifulSoup
import requests
py_url = "http://doc.scrapy.org/en/latest/_static/selectors-sample1.html"
py_con = requests.get (py_url)
py_soup = BeautifulSoup (py_con.text, 'html.parser')
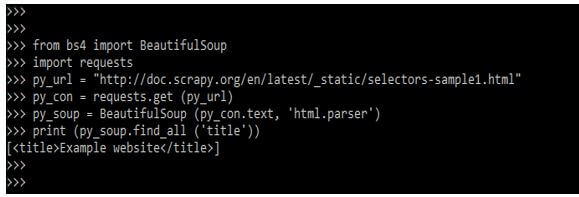
print (py_soup.find_all ('title'))
Output:
BeautifulSoup find by class Elements
- The webpage we wish to scrape will result in HTML content being returned. We can achieve this with Python’s Request library.
- Using BeautifulSoup, fetch and parse the data and save it in a data structure like a Dict or List.
- They examine HTML tags and their attributes, including class and attributes. Various file formats, including CSV, XLSX, and JSON, can save data.
- Beautifulsoup produces a parse tree from an HTML or XML document that has been parsed. Next, we will generate a BeautifulSoup object called soup using the previously obtained web page.
- We may use Python’s built-in HTML.parser to create the HTML page. The object represents the HTML page as a layered data structure.
- Beautifulsoup only enables parsing the answer into HTML/XML and does not support making server requests; hence, we need Requests.
- BeautifulSoup is a popular Python module for scraping data from the internet. Beautifulsoup find by class, is very important and valuable in Python.
The below example shows beautifulsoup find by class elements as follows.
Code:
from bs4 import BeautifulSoup
import requests
py_url = "http://doc.scrapy.org/en/latest/_static/selectors-sample1.html"
py_con = requests.get (py_url)
py_soup = BeautifulSoup (py_con.text, 'html.parser')
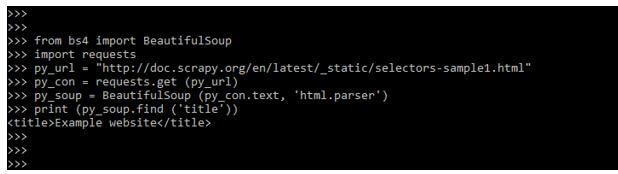
print (py_soup.find ('title'))
Output:
Conclusion
BeautifulSoup is a Python program that can be quickly installed on our computer using Python’s pip utility. Beautifulsoup find by class package that extracts information from HTML and XML files. It integrates with our preferred parser to offer fluent navigation, searching, and modification of the parse tree.
FAQs
Q1. How do I install BeautifulSoup?
Ans: You can install BeautifulSoup using pip, the Python package manager:
pip install beautifulsoup4Q2. Can I find elements by multiple classes?
Ans: Yes, you can find elements with multiple classes by passing a list of class names to the find_all() method. For example:
elements = soup.find_all(class_=['class1', 'class2'])Q3. How can I find elements with a specific class name and other attributes?
Ans: You can use CSS selectors with the select() method to find elements with specific class names and other attributes. For example:
elements = soup.select('.your-class-name[attr1="value"]')Recommended Articles
We hope that this EDUCBA information on “BeautifulSoup find by class” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

