
Introduction to BeautifulSoup Requests
BeautifulSoup request is used to create spiders and scrapes data from various websites with minimal repetition. BeautifulSoup request is instrumental in python. BeautifulSoup requests to a webpage, usually with Requests which were returned (usually with BeautifulSoup) to obtain the needed information—using Selenium and other automated software testing tools to access a website’s content programmatically. Websites that require Javascript inaccessible via HTML are an everyday use case.
The code we write to scrape a page delivers our request to the server’s hosts that target the page—extracting only the items defined in the crawling task earlier. Beautiful Soup provides simple techniques for changing a parse tree in HTML and XML files. In other instances, we must manually acquire text from the internet. It also converts Unicode automatically, so we don’t have to worry about encodings. This program not only scrapes data but also cleans it. Beautiful Soup supports the HTML parser contained in python’s standard library.
How do BeautifulSoup Requests work?
- We often wish to engage with data programmatically to make sense of it because the web offers data.
- Website creators may offer us data in the form of.csv or comma-separated values files. The Requests module allows us to connect our Python programs to web services.
- These days data is more important, and how it may help us discover new patterns and insights. The correct data assist a company in improving its marketing approach, which can boost overall sales. Python’s BeautifulSoup package for scraping data from the web is a popular choice.
The below steps show how to work with beautifulsoup requests.
1. In this step, we are installing the bs4 package by using the pip command. In the below example, we have already installed the bs4 package in our system, so it will show that the requirement is already satisfied, so we do not need to do anything.
Code:
pip install bs4
Output:

2. After installing the bs4 package in this step, we install the requested packages. In the below example, we have already installed the requests package in our system, so it will show that the requirement is already satisfied, so we do not need to do anything.
Code:
pip install requests
Output:

3. After installing all the modules, we open the python shell by using the python3 command.
Code:
python3
Output:

4. After logging into the python shell in this step, we check bs4, and the requests package is installed in our system.
Code:
import bs4
import requests
Output:
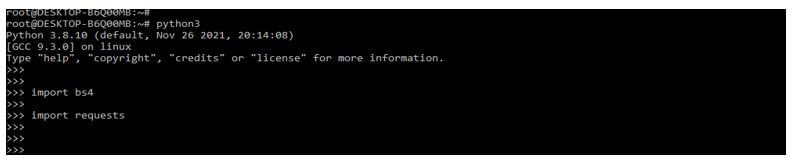
5. After checking all the prerequisites in this step, we import the library of bs4 and requests packages.
Code:
from bs4 import BeautifulSoup
import requests
Output:

6. In the below example, we collect the web page with requests. We are using the python url.
Code:
import requests
from bs4 import BeautifulSoup
py_url = 'https://www.python.org/about/'
py_page = requests.get (py_url)
py_page
py_page.status_code
py_page.text
Output:
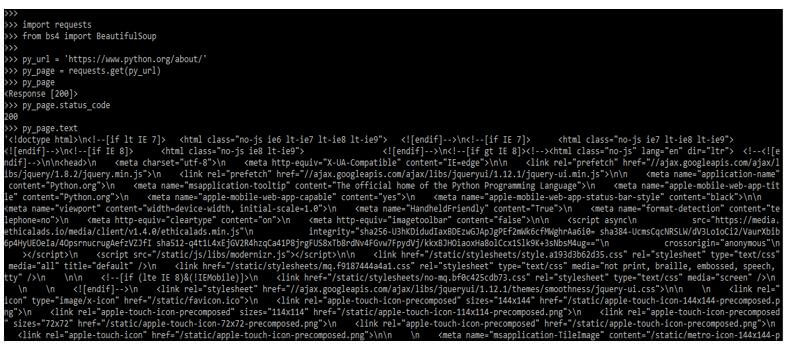
- The Beautiful Soup software builds a parse tree from parsed HTML and XML documents. As a result, the text on the web page will be more readable due to this functionality instead of what we observed with the Requests module.
- In the below example, we are using the beautifulsoup request. Also, we are using the html.parser with the py_page variable.
Code:
import requests
from bs4 import BeautifulSoup
py_url = 'https://www.python.org/about/'
py_page = requests.get(py_url)
py_page
py_page.status_code
py_soup = BeautifulSoup(py_page.text, 'html.parser')
print(py_soup.prettify())
Output:
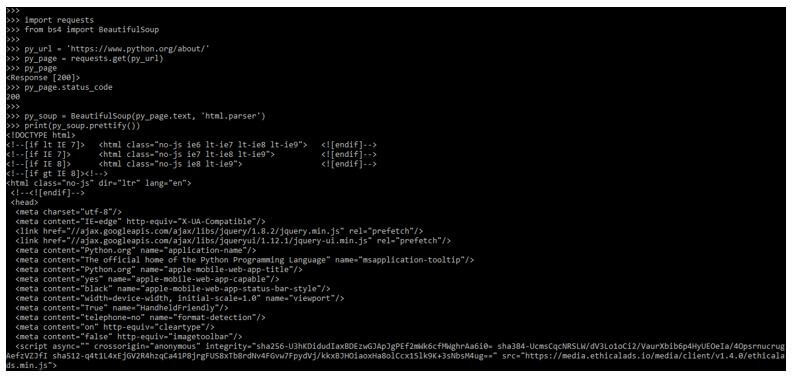

- In the above example, we first imported the request and bs4 module. After importing the module, we get the python URL to make beautifulsoup requests. After getting the request in the next step, we use the request method to send the request via URL.
- Then we print the status code of the printing URL. After getting the status code in the next step, we use the beautifulsoup method with html.parser.
BeautifulSoup Installing Requests
- The below steps shows installing the beautifulsoup requests. To use beautifulsoup requests, we mainly need bs4 and the requests module.
- We need to check where the pip command is located to install the request package.
The below example shows to check the pip command location.
Code:
which pip
Output:

- To deal with web pages, we’ll need to request the page. The Requests package makes it possible to use HTTP in a human-readable fashion in Python projects. We’ll use pip to install Requests once we’ve set up our development environment.
Code:
pip install requests
Output:
- In the above example, we can see that the message is showing requirement was already satisfied because we have already installed requests in our system.
- Generally, we are using the lxml for speed; if suppose we are using an older version of python, it is recommended to install lxml and html5lib in our system.
- In the above example, we have installed the requests module, and now in the below example, we are installing the beautifulsoup module. We are installing the beautifulsoup by using the pip command.
- The below example shows install beautifulsoup4 in our system. In the below example, we are installing the beautifulsoup 4.10.0 version.
Code:
pip install beautifulsoup4
Output:

BeautifulSoup Web Page Requests
- We can get content from a URL using the requests library, and the beautiful soup library can help us parse it and get the details we want. We may use a lovely soup library to get data via Html tags, classes, ids, CSS selectors, and various other methods.
- The following is the output, which includes the page title. The below example shows beautifulsoup web page requests as follows. We are using a python web page for requests. We can see in the below example we have used bs4 and the requests module. We are printing the status code of a webpage.
Code:
import requests
from bs4 import BeautifulSoup
py_res = requests.get ('https://www.python.org/about/')
print ("Status ", py_res.status_code)
print ("\n")
py_data = BeautifulSoup (py_res.text, 'html.parser')
print (py_data.title)
Output:

Conclusion
Beautiful Soup provides simple techniques for changing a parse tree in HTML and XML files. Beautifulsoup requests to a webpage, usually with Requests which were returned to obtain the needed information. The code we write to scrape a page delivers our request to the server’s hosts that target the page.
Recommended Articles
This is a guide to BeautifulSoup Requests. Here we discuss the introduction, working, installing requests, and web page requests. You may also have a look at the following articles to learn more –

