
Introduction to BeautifulSoup Table
BeautifulSoup table is nothing but a scraping webpage; we are likely to come across HTML tables, and extracting usable data might be difficult if we don’t know what we are doing. Therefore, the BeautifulSoup table is referred to as scraping. The code we write while scraping a page delivers our request that hosts the destination page. Then we download the webpage, extracting only the components defined in the crawling task at the time.
What is a BeautifulSoup Table?
- We don’t always have access to the well-organized CSV-formatted dataset; sometimes, the information we need is available on the internet, and we must be able to acquire it. Fortunately, python provides a library called Beautiful Soup that can help us.
- Pandas is a data analysis library that, in many circumstances, is used when working on a data set, especially if we want to analyze it. The Pandas for Data Analysis lesson series is a great place to start if we are interested in data analysis. Also, the BeautifulSoup table is essential in Python.
Web-scraping BeautifulSoup Table
- XML, like HTML, uses tags, but it differs differently. To parse XML, we can use several libraries.
- As a result, we’ll show how to use a library to scrape any table from any website.
- We don’t even need to evaluate website elements with this method; we only need to provide the website’s URL. That’s all there is to it; the job will be completed in seconds.
Below are the steps that were used in the web scraping of the beautifulsoup table:
1. In this step, we are installing the bs4 package by using the pip command. We have already installed the bs4 package in our system, so it will show that the requirement is already satisfied. Then, we do not need to do anything.
Code:
pip install bs4
Output:

2. After installing the bs4 package in this step, we are installing the request packages. In the below example, we have already installed the requests package in our system, so it will show that the requirement is already satisfied, so we do not need to do anything.
Code:
pip install requests
Output:
3. After installing all the modules, we open the python shell by using the python3 command.
Code:
python3
Output:

4. After logging into the Python shell in this step, we check bs4, and the requests package is installed in our system.
Code:
import bs4
import requests
Output:
5. After checking all the prerequisites in this step, we import the library of bs4 and request packages.
Code:
from bs4 import BeautifulSoup
import requests
Output:

6. Below example shows a web scraping beautifulsoup table. In the following example, we are using the web url of Python.
Code:
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
py_url = "https://www.python.org/"
py_wpage = requests.get (py_url)
py_soup = BeautifulSoup (py_wpage.text, 'html.parser')
print (py_soup.prettify ())
Output:

BeautifulSoup Table Parsing HTML
- We don’t need to set scraper to obtain some tables off a website if all we want is some tables because Pandas can do it all by itself. For example, the pandas.read html function returns a collection of DataFrames containing all of the tables on a page; we only need to provide the page’s URL.
- This function takes a few parameters to assist in finding the proper table. First, we use a regex that the table should match and a header to receive the table with our defined headers.
- Pandas is a fantastic program, but it does not answer all our issues. For example, there will be occasions when we need to scrape elements, whether because we don’t want the complete table or because they are inconsistent with the database’s structure.
- We’ll locate the table in the example below. We may get the first table accessible, but the page could have multiple tables, which is frequent on Wikipedia sites. As a result, we must examine all tables to determine which is correct. But we can’t just keep going. Take a look at how HTML is structured.
Code:
import requests
import pandas as pd
from bs4 import BeautifulSoup
py_url = "https://pt.wikipedia.org/wiki/Lista_de_bairros_de_Manaus"
py_data = requests.get(py_url).text
py_soup = BeautifulSoup (py_data, 'html.parser')
print ('Classes of each table:')
for table in py_soup.find_all ('table'):
print (table.get ('class'))
Output:
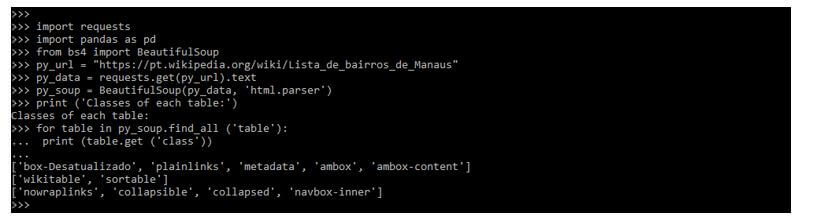
BeautifulSoup Table Scraping
- To do the beautifulsoup table scraping, we need to install the bs4 module in our system. We have already installed the bs4 and request module in the above example.
- Before scraping a table, we need to check the web page on which BeautifulSoup is applied. First, go to the Wikipedia page using the link before the tools.
- The target table can be found under the page’s html code using developer tools. The below example shows you inspect the beautifulsoup table scraping page.
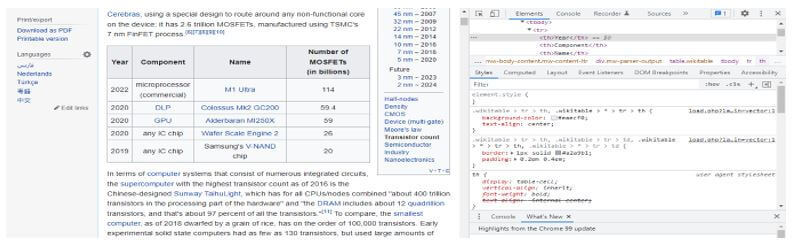
The below code shows an overview of beautifulsoup table scraping.
Code:
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
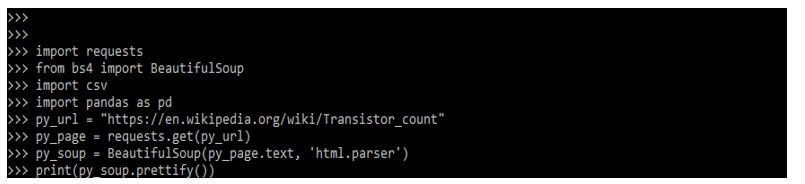
py_url = "https://en.wikipedia.org/wiki/Transistor_count"
py_page = requests.get(py_url)
py_soup = BeautifulSoup (py_page.text, 'html.parser')
print (py_soup.prettify())
Output:
- We may believe that we do not need to declare the table class. This time, it exists with a different class name, box-More, as shown in the figure below.
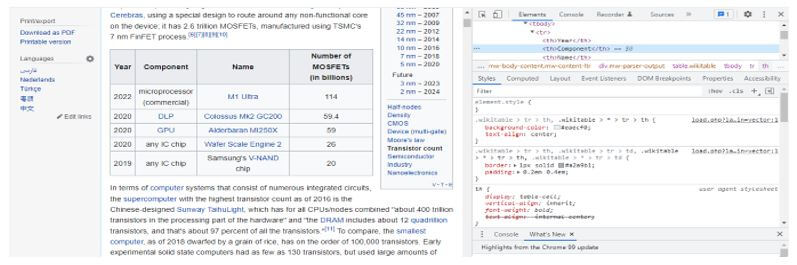
The below example shows extracts of the table body as follows.
Code:
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
py_url = "https://en.wikipedia.org/wiki/Transistor_count"
py_page = requests.get (py_url)
py_soup = BeautifulSoup (py_page.text, 'html.parser')
py_table = soup.find ('table', {'class':'wikitable'}).tbody
py_rows = py_table.find_all ('tr')
print (rows[0])
print (rows[1])
Output:
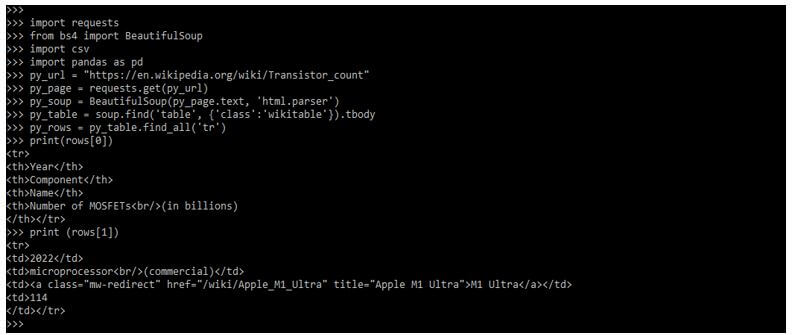
The example below shows how to create the data frame in beautifulsoup table scraping.
Code:
import requests
from bs4 import BeautifulSoup
import csv
import pandas as pd
py_url = "https://en.wikipedia.org/wiki/Transistor_count"
py_page = requests.get(py_url)
py_soup = BeautifulSoup(py_page.text, 'html.parser')
py_table = soup.find('table', {'class':'wikitable'}).tbody
py_col = [v.text for v in rows[0].find_all('th')]
print (py_col)
Output:
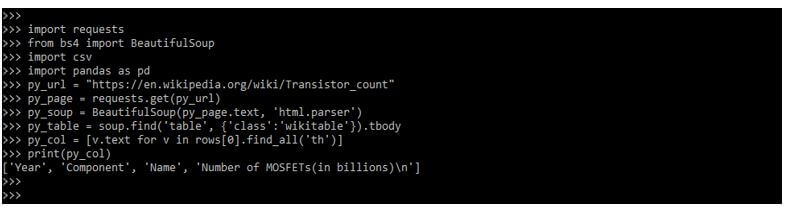
Conclusion
The essential data collection concept is web scraping is a beautifulsoup table. For web scraping in Python are BeautifulSoup, Selenium, and XPath. Scraping is a vital skill for anyone who wants to extract. However, if we use the standard Beautiful soup parser, it’s a time-consuming task.
Recommended Articles
This is a guide to BeautifulSoup Table. Here we discuss the introduction, web-scraping BeautifulSoup table, parsing HTML, and scraping. You may also have a look at the following articles to learn more –

