
Introduction to BeautifulSoup Web Scraping
BeautifulSoup web scraping operations are performed in various programming languages and libraries, but python and the BeautifulSoup module contain effective options. In the following parts, we’ll go through the fundamentals of scraping in Python with BeautifulSoup. Our code sends a request to the server that hosts the destination page. BeautifulSoup code extracts only the items defined in the crawling task.
What is Web Scraping?
- The process of collecting data from the internet is known as web scraping. Web scraping includes the lyrics to our favorite music.
- On the other hand, the term “web scraping” typically refers to an automated operation. As a result, some websites dislike having their data scraped by automated scrapers, while others are unconcerned.
- The internet evolved naturally from a variety of sources. As a result, it incorporates a wide range of technology. To put it another way, the internet is a jumble! As a result, we will face various difficulties when scraping the Web.
- It also converts our documents into Unicode, so we don’t have to worry about encodings. Finally, this program not only scrapes data but also cleans it.
- BeautifulSoup works with the HTML parser available in python’s standard library and various third-party Python parsers such as lxml and hml5lib.
- Web data scraper is a method for obtaining vast volumes of information from web pages and saving it into the database. We can also save this information into the local file.
- We’ll utilize lxml, an extensive library for quick texts, and even messed-up tags. We’ll also use the Requests module rather than the built-in urllib2 module because it’s faster and easier to read. Finally, BeautifulSoup web scraping is very important and valuable in python to obtain information from web pages.
- Adding to our understanding of web scraping, let’s talk about the integral role of proxies. Using the best scraping proxies is quintessential for successful data extraction operations. Proxies offer a sort of cloaking mechanism, masking your IP address to combat potential blocking from websites. Particularly when dealing with larger scales or frequent scrapes, using top-rated scraping proxies can extensively enhance your process by bypassing access restrictions and ensuring smoother data collection. Thus, hand in hand with sophisticated tools like BeautifulSoup, these proxies optimize the overall effectiveness of web scraping efforts.
How to do BeautifulSoup Web Scraping?
We must install various packages first to do BeautifulSoup web scraping in our project.
Below steps shows how to use beautiful XPath:
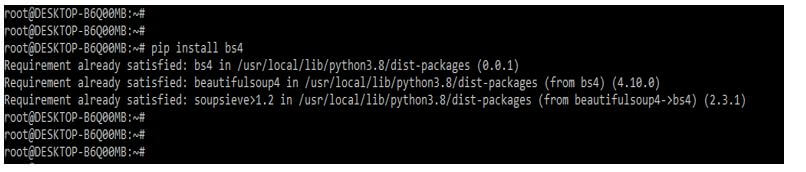
1. In this step, we are installing the bs4 package by using the pip command. Bs4 package is used to import all the beautifulsoup modules. In the below example, we have already installed the bs4 package in our system, so it will show that the requirement is already satisfied, so we do not need to do anything.
Code:
pip install bs4
Output:
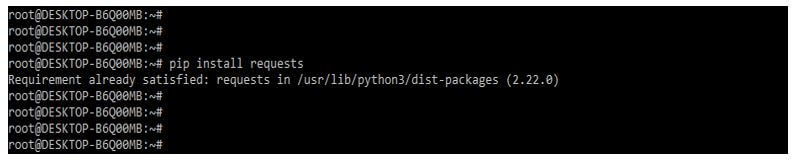
2. After installing the bs4 package in this step, we are installing the requests packages because the package is also required when using beautifulsoup in our project. In the below example, we have already installed the requests package in our system, so it will show that requirement is already satisfied, then we have no need to do anything.
Code:
pip install requests
Output:
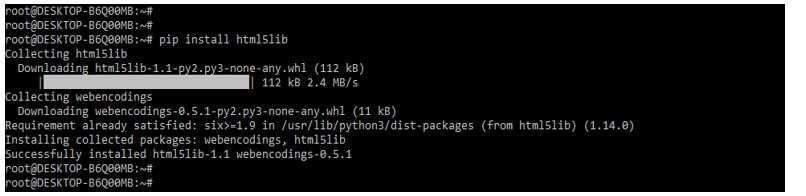
3. After installing the requests module in this step, we install the html5lib module using the pip command.
Code:
pip install html5lib
Output:
4. After installing all the modules, we open the python shell using the python3 command.
Code:
python3Output:

5. After logging into the python shell in the below example, we are accessing the html content from the web page. In the below example, we have imported the request module; after importing the module, we have accessed the url then we are printing the content of this url.
Code:
import requests
py_url = "https://realpython.com/beautiful-soup-web-scraper-python/"
py_req = requests.get(py_url)
print(py_req.content)
Output:

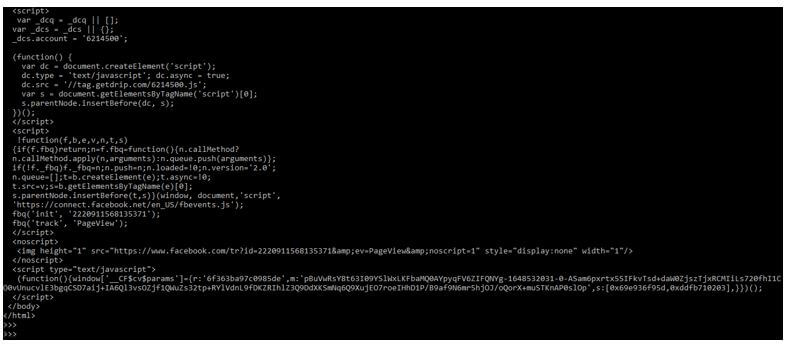
6. After accessing the content from the webpage in this step, we are parsing the html content as follows. In the below example, we have imported the request and bs4 module; after importing the module, we send the http request from the specified url.
Code:
import requests
from bs4 import BeautifulSoup
py_url = "https://realpython.com/beautiful-soup-web-scraper-python/"
py_req = requests.get(py_url)
soup = BeautifulSoup (py_req.content, 'html5lib')
print (soup.prettify())
Output:
Using Developer Web Scraping
The BeautifulSoup library is built on top of HTML parsing libraries such as html5lib, lxml, html.parser, and others. So we may create a BeautifulSoup object while also specifying the parser library.
Below are the steps we used at the time developer web scraping is as follows.
- Using the Requests library, extract the HTML content.
- Examine the HTML structure for tags containing our content.
- Using BeautifulSoup, extract the tags and store the information in a Python list.
The below example shows developer web scraping as follows.
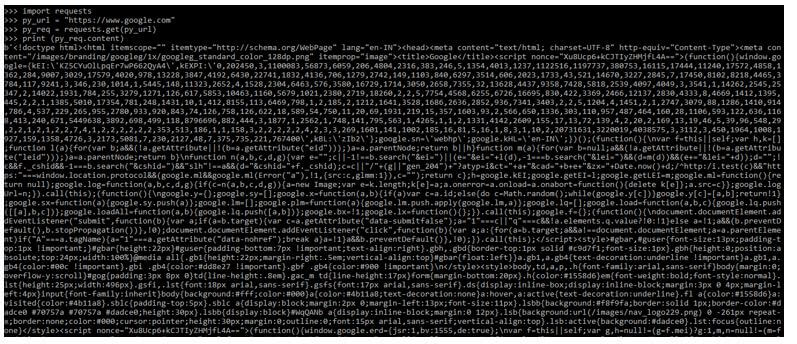
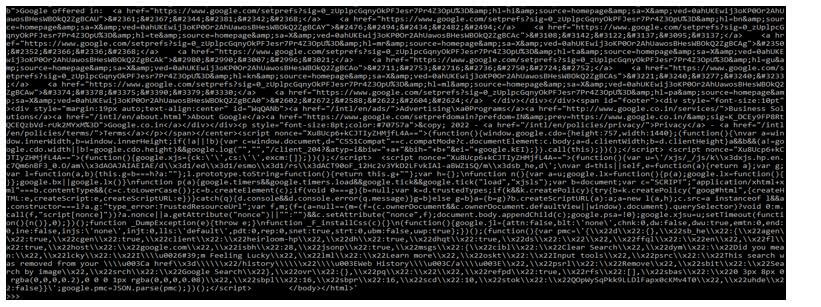
In the below example, we can see; that first, we imported the requests module, then accessed the google url to do the developer web scraping.
Code:
import requests
py_url = "https://www.google.com"
py_req = requests.get(py_url)
print (py_req.content)
Output:
HTML Class Elements
A class attribute for an element defines one or more class names. For example, the class element is commonly used to refer to a style sheet’s class. However, JavaScript can modify HTML components with a defined class.
An HTML element’s class is specified using the HTML class property. The same class can be applied to several HTML elements.
The below example shows html class elements are as follows.
Code:
<!DOCTYPE html>
<html>
<head>
<style>
h1.intro
{
color: red;
}
p.important
{
color: black;
}
</style>
</head>
<body>
<h1 class="BeautifulSoup"> BeautifulSoup </h1>
<p>Web scraping</p>
<p class="Web scraping"> BeautifulSoup Web scraping</p>
</body>
</html>
Output:

Method Function
The web page’s HTML content is sent by the server in response. We’ll utilize Requests because we’re utilizing python for our requests.
Each quote is contained within a div container with the class quote in the table element. As a result, we iterate over each div container with the quoted class. We can’t extract data from most HTML data using string processing because it’s nested. A parser is required to convert HTML data into a nested/tree structure. The most potent HTML parser library is html5lib, which is accessible in various formats.
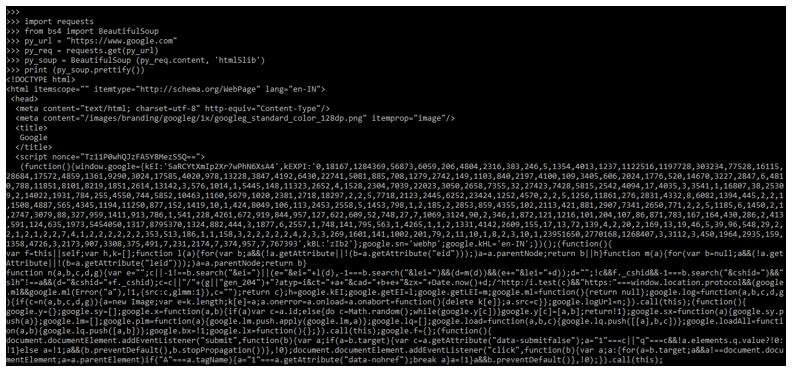
The below example shows the method function.
Code:
import requests
from bs4 import BeautifulSoup
py_url = "https://www.google.com"
py_req = requests.get(py_url)
py_soup = BeautifulSoup (py_req.content, 'html5lib')
print (py_soup.prettify())
Output:
Conclusion
BeautifulSoup provides simple techniques for changing a parse tree in HTML and XML files. BeautifulSoup web scraping operations are performed in various programming languages and libraries. The process of collecting data from the internet is known as web scraping.
Recommended Articles
This is a guide to BeautifulSoup Web Scraping. Here we discuss the introduction, how do BeautifulSoup web scraping? HTML class elements and method function. You may also have a look at the following articles to learn more –

