Updated February 18, 2023

Definition of BeautifulSoup XPath
Beautifulsoup xpath functions in the same way as a standard file system. BeautifulSoup, by default, is not supporting the xpath. Therefore, our soup object must be converted into the thing of etree. XPath 1.0 is supported by an alternative library called lxml. It includes a BeautifulSoup compatible mode that attempts to parse broken HTML in the same way that Soup does; Beautifulsoup xpath is very useful and essential in python.
What is BeautifulSoup XPath?
- On the other hand, the default lxml HTML parser does a similar job of parsing broken HTML and is faster. We can use the xpath function to look for elements once we have parsed our page into the lxml tree.
- Using lxml to get data from a webpage element necessitates using Xpaths. XPath functions similarly to a typical file system.
- Scraping is the only way to create an initial grinding that may be used to transmit that accuracy to other surfaces. However, because they affect isolated high or low places, lapping and grinding cannot produce the long-distance flatness that scraping may.
How to use BeautifulSoup XPath?
- We need to install various packages to use beautiful xpath in our project. The below steps show how to use beautiful xpath as follows.
- In this step, we are installing the bs4 package by using the pip command. Bs4 package is used to import all the beautifulsoup modules. In the below example, we have already installed the bs4 package in our system, so it will show that the requirement is already satisfied, so we do not need to do anything.
pip install bs4
2. After installing the bs4 package in this step, we are installing the requests packages because the requests package is also required when using beautifulsoup xpath in our project. In the below example, we have already installed the requests package in our system, so it will show that requirement is already satisfied, then we have no need to do anything.
pip install requests
3. After installing the requests package in this step, we are installing the lxml packages because the lxml package is also required when using beautifulsoup xpath in our project. In the below example, we have already installed the requests package in our system, so it will show that requirement is already satisfied, then we have no need to do anything.
# pip install lxml
4. We can find the xpath of a particular element using the following methods. First, we need to right-click on the element we want to inspect and then click on the elements tab; we need to copy xpath.
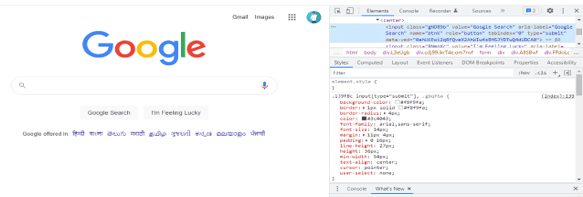
5. After installing all the modules, we open the python shell by using the python3 command.
python3
6. After opening the python shell, we import the beautifulsoup, etree, and requests modules. We are importing the beautifulsoup module by using the bs4 package as follows.
from bs4 import BeautifulSoup
from lxml import etree
import requests
- After importing the module in the next step, we take content from a website and repurpose it. Because BeautifulSoup does not enable dealing with XPath by default, we must change the etree object to use it. Lxml, on the other hand, supports XPath 1.0. In addition, it includes a BeautifulSoup-compatible mode that attempts to parse broken HTML in the same way that Soup does. To copy an element’s XPath, inspect the element, then right-click on its HTML and look for the XPath. After that, we use the xpath method from the etree class of the lxml module.
Code –
from bs4 import BeautifulSoup
from lxml import etree
import requests
py_url = "https://en.wikipedia.org/wiki/Main_Page/Welcome_to_Wikipedia,"
py_headers = ({'User-Agent':
'Safari/537.36',\
'Accept-Language': 'en-US, en;q=0.5'})
py_wpage = requests.get (py_url, headers=py_headers)
py_soup = BeautifulSoup (py_wpage.content, "html.parser")
dom = etree.HTML (str(py_soup))
print (dom.xpath ('//*[@id="firstHeading"]')[0].text)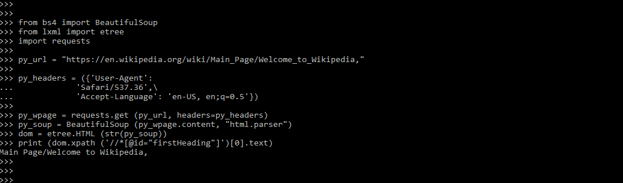
- The above example shows that we first imported the bs4, etree, and requests modules. After importing the module, we are using url.
- After using the URL, we scrape the content from the webpage; then, for converting the soup object, we use the xpath.
BeautifulSoup XPath Methods
- Scrapy is the first package that brings to mind when we think of web scraping in python. Scrapy, on the other hand, is better suited to larger scraping projects.
- Scrapy, however, has a learning curve that takes time. As a result, Scrapy can be overkill for minor scraping problems where we only need to gather data from a webpage.
- We can rapidly scrape the required content using requests and Beautiful Soup/lxml packages in this situation.
- These instructions include demonstrations of all of the primary features. The below example shows methods of beautifulsoup xpath are as follows.
Code –
from bs4 import BeautifulSoup
from lxml import etree
import requests
soup_url = "https://en.wikipedia.org/wiki/Wikipedia:About"
soup_headers = ({'User-Agent':
'Safari/537.36',\
'Accept-Language': 'en-US, en;q=0.5'})
soup_wpage = requests.get (soup_url, headers = soup_headers)
py_soup = BeautifulSoup (py_wpage.content, "html.parser")
dom = etree.HTML (str(py_soup))
print (dom.xpath ('//*[@id="firstHeading"]')[0].text)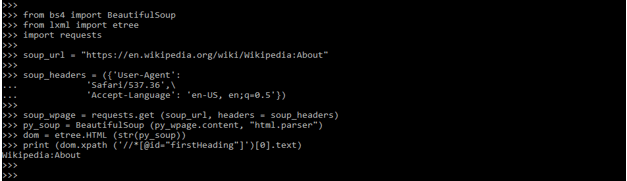
BeautifulSoup XPath Examples
- The below example shows beautifulsoup xpath is as follows. In the below example, we are using the url of Wikipedia as follows.
Code –
from bs4 import BeautifulSoup
from lxml import etree
import requests
xpath_url = "https://en.wikipedia.org/wiki/Wikipedia:About"
xpath_headers = ({'User-Agent':
'Safari/537.36',\
'Accept-Language': 'en-US, en;q=0.5'})
xpath_wpage = requests.get (xpath_url, headers = xpath_headers)
xpath_soup = BeautifulSoup (xpath_wpage.content, "html.parser")
dom = etree.HTML (str(xpath_soup))
print (dom.xpath ('//*[@id="firstHeading"]')[0].text)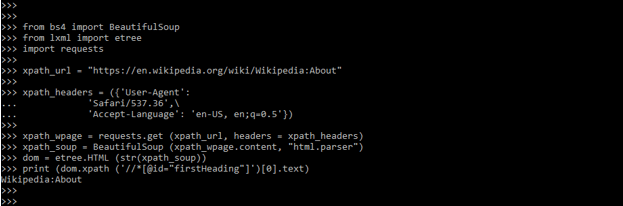
- We have imported the bs4, etree, and requests modules in the above example. After importing the module, we are using url. Also, we are using the Wikipedia url to scrap the content from the webpage.
Conclusion
We can use the xpath function to look for elements once we have parsed our page into the lxml tree. Beautifulsoup xpath functions similarly to a standard file system. BeautifulSoup, by default, is not supporting the xpath. Instead, our soup object must be converted into the thing of etree.
Recommended Articles
This is a guide to BeautifulSoup XPath. Here we discuss the Definition, What BeautifulSoup XPath is, How to use BeautifulSoup XPath, and examples with code. You may also have a look at the following articles to learn more –

