Updated April 13, 2023
Definition of C++ Hash Table
A Hash table is basically a data structure that is used to store the key value pair. In C++, a hash table uses the hash function to compute the index in an array at which the value needs to be stored or searched. This process of computing the index is called hashing. Values in a hash table are not stored in the sorted order and there are huge chances of collisions in the hash table which is generally solved by the chaining process (creation of a linked list having all the values and the keys associated with it).
Algorithm of Hash Table in C++
Below given is the step by step procedure which is followed to implement the hash table in C++ using the hash function:
- Initializing the table size to some integer value.
- Creating a hash table structure hashTableEntry for the declaration of key and value pairs.
- Creating constructor of hashMapTable.
- Create the hashFunction() and finding the hash value which will be an index to store the actual data in the hash table using the formula:
hash_value = hashFunction(key);
index = hash_value% (table_size)- Respective functions like Insert(), searchKey(), and Remove() are used for the insertion of the element at the key, searching of the element at the key, and removing the element at the key respectively.
- Destructor is called to destroy all the objects of hashMapTable.
How does a Hash Table Work in C++?
As discussed above, hash tables store the pointers to the actual data/ values. It uses the key to find the index at which the data/ value needs to be stored. Let us understand this with the help of the diagram given below:
Consider the hash table size be 10
| Key | Index (using a hash function) | Data |
| 12 | 12%10 = 2 | 23 |
| 10 | 10%10 = 0 | 34 |
| 6 | 6% 10 = 6 | 54 |
| 23 | 23 % 10 = 3 | 76 |
| 54 | 54 %10 = 4 | 75 |
| 82 | 81 %10 = 1 | 87 |
The element position in the hash table will be:
0 1 2 3 4 5 6 7 8 9
| 34 | 87 | 23 | 76 | 75 | 54 |
As we can see above, there are high chances of collision as there could be 2 or more keys that compute the same hash code resulting in the same index of elements in the hash table. A collision cannot be avoided in case of hashing even if we have a large table size. We can prevent a collision by choosing the good hash function and the implementation method.
Though there are a lot of implementation techniques used for it like Linear probing, open hashing, etc. We will understand and implement the basic Open hashing technique also called separate chaining. In this technique, a linked list is used for the chaining of values. Every entry in the hash table is a linked list. So, when the new entry needs to be done, the index is computed using the key and table size. Once computed, it is inserted in the list corresponding to that index. When there are 2 or more values having the same hash value/ index, both entries are inserted corresponding to that index linked with each other. For example,
| 2 —> 12 —–>22 —->32 |
Where,
2 is the index of the hash table retrieved using the hash function
12, 22, 32 are the data values that will be inserted linked with each other
Example of C++ Hash Table
Let us implement the hash table using the above described Open hashing or Separate technique:
Code:
#include <iostream>
#include <list>
using namespace std;
class HashMapTable
{
// size of the hash table
inttable_size;
// Pointer to an array containing the keys
list<int> *table;
public:
// creating constructor of the above class containing all the methods
HashMapTable(int key);
// hash function to compute the index using table_size and key
inthashFunction(int key) {
return (key % table_size);
}
// inserting the key in the hash table
void insertElement(int key);
// deleting the key in the hash table
void deleteElement(int key);
// displaying the full hash table
void displayHashTable();
};
//creating the hash table with the given table size
HashMapTable::HashMapTable(intts)
{
this->table_size = ts;
table = new list<int>[table_size];
}
// insert function to push the keys in hash table
void HashMapTable::insertElement(int key)
{
int index = hashFunction(key);
table[index].push_back(key);
}
// delete function to delete the element from the hash table
void HashMapTable::deleteElement(int key)
{
int index = hashFunction(key);
// finding the key at the computed index
list <int> :: iterator i;
for (i = table[index].begin(); i != table[index].end(); i++)
{
if (*i == key)
break;
}
// removing the key from hash table if found
if (i != table[index].end())
table[index].erase(i);
}
// display function to showcase the whole hash table
void HashMapTable::displayHashTable() {
for (inti = 0; i<table_size; i++) {
cout<<i;
// traversing at the recent/ current index
for (auto j : table[i])
cout<< " ==> " << j;
cout<<endl;
}
}
// Main function
intmain()
{
// array of all the keys to be inserted in hash table
intarr[] = {20, 34, 56, 54, 76, 87};
int n = sizeof(arr)/sizeof(arr[0]);
// table_size of hash table as 6
HashMapTableht(6);
for (inti = 0; i< n; i++)
ht.insertElement(arr[i]);
// deleting element 34 from the hash table
ht.deleteElement(34);
// displaying the final data of hash table
ht.displayHashTable();
return 0;
}Output:
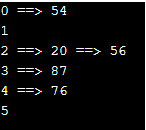
Explanation: In the above code, an array is created for all the keys that need to be inserted in the has table. Class and constructors are created for hashMapTable to calculate the hash function using the formula mentioned above. The list is created as the pointer to the array of key values. Specific functions are created for the insertion, deletion, and display of the hash table and called from the main method. While insertion, if 2 or more elements have the same index, they are inserted using the list one after the other.
Conclusion
The above description clearly explains what a hash table in C++ and how it is used in programs to store the key value pairs. Hash tables are used as they are very fast to access and process the data. There are many chances of collisions while calculating the index using a hash function. We should always look for the methods that will help in preventing the collision. So one needs to be very careful while implementing it in the program.
Recommended Articles
This is a guide to C++ Hash Table. Here we also discuss the definition and algorithm of a hash table in c++ along with different examples and its code implementation. You may also have a look at the following articles to learn more –

