Updated April 13, 2023

Definition of C++ hashset
HashSet can be an unordered collection that consists of unique elements. HashSet consists of standard operation collections such as Contains, Remove, and Add; it also constitutes standard set-based operations like symmetric difference, intersection, and union. An internal structure (hash) in the HashSet is very useful in searching and identifying the items. In the list consisting of duplicates, HashSet plays an important role in identifying and getting the distinct values and even the duplicate values. The time taken by all the unordered_set (HashSet) is O(1) which is constant in nature, but in the worst case, the time taken can be O(n) which is linear time. In this article, we will discuss the C++ hashset in detail.
Syntax:
The syntax to inset the unordered_set, which is a string type in C++, has been shown below:
int main()
{
unordered_set <string> CBA ;
CBA.insert("Data Science") ;
CBA.insert("Data Analyst") ;
...........
}C++ HashSet Examples with their working
HashSet (unordered_set), as the same suggests, is the set where the key is stored in any order. There are many functions for HashSet (unordered_set), but the most used functions are:
- Size: used for capacity
- Empty: used for capacity
- Find: used to search a key
- Erase: used for modification
- Insert: used for modification
Only unique keys are allowed by unordered_set, and duplicate keys are allowed through unordered_multiset.
Examples
The whole working of the C++ HashSet has been explained with the different examples below:
1. Basic example of C++ HashSet using {….}, an initialize list
Below is the basic example of using HashSet in C++, where we have initialized the set using initializer lists ‘{….}’. This example is majorly for C++11, and this code won’t be working in C++98, where the set is initialized using a constructor.
Code:
#include <iostream>
#include <unordered_set>
int main()
{
std::unordered_set<int> X { 2020, 2019, 2018 };
for (auto Y: X)
std::cout << Y << '\n';
return 0;
}Output:

2. Binary predicate used for passing comparison object
In the example below, comparison objects are passed using a binary predicate (std::set). Set ordering uses the same types of elements.
Code:
#include <iostream>
#include <set>
// std::set a Binary predicate
struct EDUCBA {
template<typename R>
bool operator()(const R& m, const R& a) const
{
return m > a;
}
};
int main()
{
// sorting of the elements is done according to the comparison object
std::set<int, EDUCBA> values = { 49, 25, 100 };
for (auto J: values)
std::cout << J << '\n';
return 0;
}Output:

Example #3 – Using iteration, insert, find, and declaration in HashSet (unordered_set)
In the example below, on average, the erase, insert, and find operations take constant time. When the key is not present in the set, the find() function in the code below returns the iterator to end(). If the key is present in the set, then the iterator returns to the key position. For getting the key, the iterator is useful as a pointer for the key values, and by dereferencing using the * operator, the key can be received.
// In this C++ code we get to know various functions of unordered_set
Code:
#include <bits/stdc++.h>
using namespace std;
int main()
{
// set to store the declared string data-type
unordered_set <string> CBA ;
// below various strings are inserted, and certain string are stored in a set
CBA.insert("Data Science") ;
CBA.insert("Data Analyst") ;
CBA.insert("Finance") ;
CBA.insert("Excel") ;
CBA.insert("Tableau") ;
string key = "EDUCBA" ;
// below the values are searched and displayed back with the value of desired key.
if (CBA.find(key) == CBA.end())
cout << key << " best training providers." << endl << endl ;
else
cout << "Fetched" << key << endl << endl ;
key = "Finance";
if (CBA.find(key) == CBA.end())
cout << key << "Unable to fetch\n" ;
else
cout << "Fetched " << key << endl ;
// whole content is printed below
cout << "\nAll constitutes are : " <<endl;
unordered_set<string> :: iterator itr;
for (itr = CBA.begin(); itr != CBA.end(); itr++)
cout << (*itr) << endl;
}Output:
- Output when key data is in the list:

- Output when key data is not in the list:

Example #4 – Finding the duplicate content using unordered_set
In the example below, we have provided the set of integers as the input and the duplicates in the set has been found and displayed in the output.
In this C++ code, we have used unordered_set to identify the duplicacy in the array.
Code:
#include <bits/stdc++.h>
using namespace std;
// using unordered_set, below duplicates are printed in rahul[0..n-1]
void printDuplicates(int rahul[], int L)
{
// below unordered_sets are declared to check and sort the duplicate values.
unordered_set<int> EDUCBA;
unordered_set<int> matched;
// below array elements are used for looping
for (int T = 0; T < L; T++)
{
// if the content is not found then insertered as
if (EDUCBA.find(rahul[T]) == EDUCBA.end())
EDUCBA.insert(rahul[T]);
// if the content already exists then then it is inserted in the duplicate set.
else
matched.insert(rahul[T]);
}
// the results gets printed
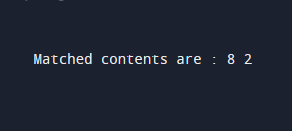
cout << "Matched contents are : ";
unordered_set<int> :: iterator start;
// iterator start looping from begining() till the ending()
for (start = matched.begin(); start != matched.end(); start++)
cout << *start << " ";
}
// code of driver
int main()
{
int rahul[] = {4, 8, 3, 5, 1, 2, 0, 9, 6, 7, 2, 8};
int L = sizeof(rahul) / sizeof(int);
printDuplicates(rahul, L);
return 0;
}Output:
Conclusion
On the basis of the above discussion, we have understood what HashSet is and how it is useful in C++. We have also understood the different applications of C++ HashSet in different examples along with the working. The use of a C++ HashSet helps in finding duplicate content and even the desired content very quickly.
Recommended Articles
This is a guide to C++ HashSet. Here we discuss the definition, syntax, and C++ HashSet Examples with their working and code implementation. You may also have a look at the following articles to learn more –

