Updated April 19, 2023

Introduction to Cassandra Partition Key
The following article provides an outline for Cassandra Partition Key. Let’s see about the role of keys in Cassandra tables, normally keys don’t strike you in relational data modeling as a super important thing. Most people will make a surrogate primary key field that’s a single auto-incrementing column or a UUID. You give a lot of thought to relational databases to index structure because you’re going to build all these indices. In Cassandra, all of that attention is focused on the key. All reads and writes to a table are based on the key. You don’t get to build indexes on other columns that will let you leave the primary key out of the picture, so the key is central.
How to Use Cassandra Partition Key?
The primary key in its entirety uniquely identifies a row. Primary keys are composed of two parts– the partition key and the clustering key, or clustering keys. There can be many columns in a Cassandra primary key. In Cassandra, it’s very typical to have multiple columns in the primary key.
Let us say we have a table of movies with the following column names in it.
movie_id, release_year, title
Let’s get a more elaborate table called movies_by_actor.
Now, already we see denormalization happening. In a relational database, obviously, you’d have movies and you’d have actors and there’d be a foreign key. That’s not how we do it here. We are going to copy data between tables. We’re going to have a table that satisfies this record of movies. And now if we want to look up movies by actor, we make an entirely different table. A movie can usually participate in more than one genre. In a set, of course, you can’t repeat elements. So it doesn’t make any sense to be a comedy twice. But you could be a comedy and a horror movie, or a drama and an action movie, or something like that. This table apparently is rateable so that’s our schema. Now, note this primary key. It’s got three columns in it. And actor gets an extra set of parentheses around it. So, what that means is an actor is what we call the partition key.
Now the partition is a group of rows in the table that is guaranteed to be local to a node. It’s a distributed database and there’s going to be multiple servers that are acting like one database. The partition key, what that says is every actor–every time the actor column has the same value all of those rows are guaranteed to be located on the same node. All of the Brad Pitt rows, all of the Emma Stone rows, all of those will be on the same server. Those are called partitions. A partition is a group of rows with a common partition key. Partition key makes sure that they’re all node-local and because they’re node-local, we can do some fun things with them that we can’t do between nodes and that’s what the clustering columns are for.
So, looking at the code, release_year and movie_id are clustering columns. So what clustering columns do is, provide order to the rows in the table. It’ll help when you insert some data into the table. All of the rows in a given actor partition, so all of the, say, Brad Pitt movies, those will be ordered by release here. We can do range queries on a clustering column to see all the Brad Pitt movies after 2001 and before 2019. You can expect that to be a performant query because it’s happening inside one node. You can also identify a single year. You want to see all the Brad Pitt movies in 2012, for example. And wherever those films are, you would get those results. Now a partition can have tens or maybe even hundreds of thousands of rows in them. So these can be big. These could be hundreds of megabytes of data and hundreds of thousands of rows.
There are some trade-offs there, right? There’s a space limitation. And there’s kind of a size limitation, a height limitation to a partition. But potentially, they can be big clusters of data. And inside those big clusters of data, those partitions, we’re able to do interesting things with range queries on clustering columns. We can have multiple clustering columns. Now, suppose the clustering column is UUID to make sure that we’ve got uniqueness. We’re not going to do range queries on a UUID. That makes no sense at all. It’s common in Cassandra when you see a primary key that has the clustering column component to kind of tack on that UUID on the end just to individuate the row and make sure it refers uniquely to one thing.
Clustering keys are things we add to the primary key. That gives the order to that partition of rows. And in this case, we’re sorting them by release year. Partition key, clustering key, together they make up the primary key and that is, if you will, a key part of table design in Cassandra.
Syntax:
Cassandra uses the first column name as the partition key.
CREATE TABLE users ( user_name varchar PRIMARY KEY, password vachar, gender varchar, state varchar,Age int);Example of Cassandra Partition Key
Given below is the example mentioned:
Code:
create table movie (Genre, release_year, movie_name,
primary key (Genre));
insert into movie (Genre, release_year, movie_name) values (Sci-fi,2011,'Thor');
insert into movie (Genre, release_year, movie_name) values(Action,2014,'Fury');select * from movie;Output:
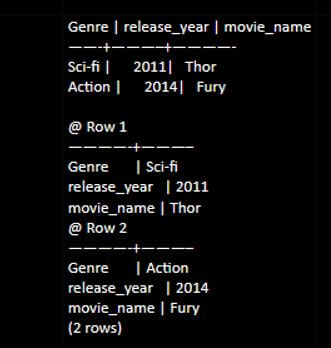
Code:
select token(Genre) from movie;Output:
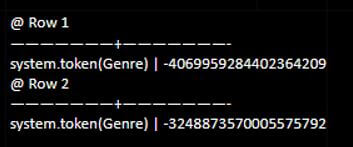
Code:
create table actor(movie_name,actor_name, Genre,release_year
primary key (Genre,actor_name));
insert into actor(movie_name,actor_name, Genre,release_year) values (‘Troy’ ,’Bradd Pitt’ ,’Drama’,2004);
insert into actor (movie_name,actor_name, Genre,release_year) values (‘Thor’, ‘Chris Hemsworth’,’Sci-fi’ ,2012);
insert into actor (movie_name,actor_name, Genre,release_year) values (‘Fury’,’Brad Pitt′,Action ,’2014’);select * from actor;Output:
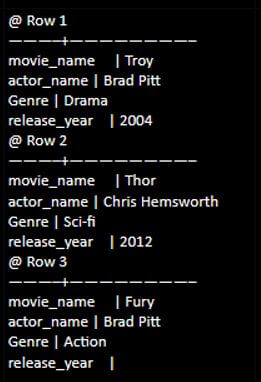
Conclusion
To conclude we understood that Cassandra treats the first column declared in the primary key in a definition as the partition key and the remaining columns are clustering columns. The best performance from Cassandra can be realized when the data needed to satisfy a particular query is located in the same partition key. Cassandra stores an entire row of data on a node by this partition key. So, to spread the data over multiple nodes, you define a composite partition key.
Recommended Articles
This is a guide to Cassandra Partition Key. Here we discuss the introduction, how to use cassandra partition key? and example respectively. You may also have a look at the following articles to learn more –

