Updated March 27, 2023
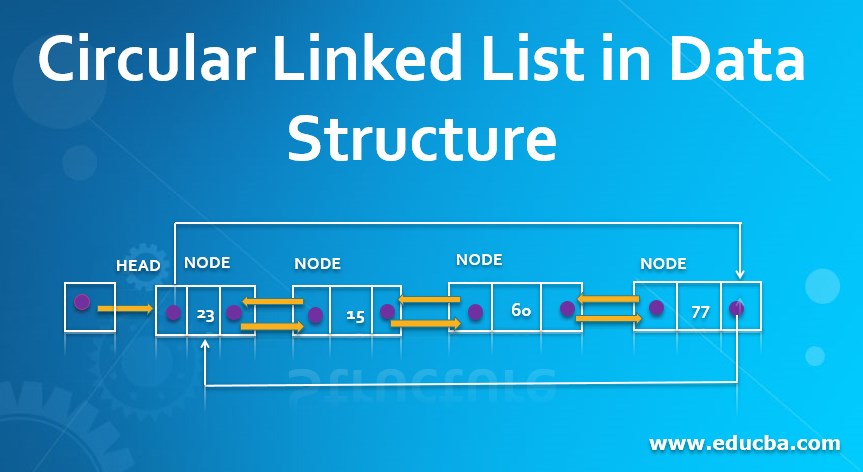
Introduction to Circular Linked List
A circular linked list data structure is formed to store the collection of elements, by pointing the start element’s location to next of the last element, which is known to form a circular linked list. Most operating system operations are required to be performed repeatedly, thus needing to be maintained in a queue where it can wait if any of the required resources are currently acquired by other ongoing processes. Instead of maintaining FIRST and the LAST pointer, only one pointer needs to be maintained HEAD to detect the visited node.
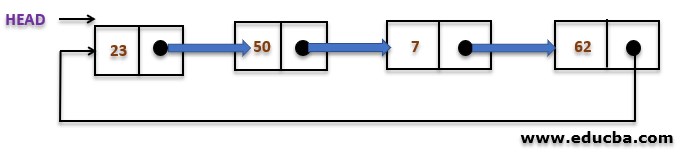
Types of Circular Linked List in Data Structure
Circular Linked list is a linked list with no end thus used to perform various continuous operations. With this one HEAD pointer of Node, a type is maintained to identify if all the list nodes have been visited. A circular linked list can be easily made by allocating the first node’s address to the next of the last node. Below is the pseudo-code for its nodes.
There are 2 Types of Circular Linked Lists:
- Singly Circular Linked List
- Doubly Circular Linked List
1. Singly Circular Linked List
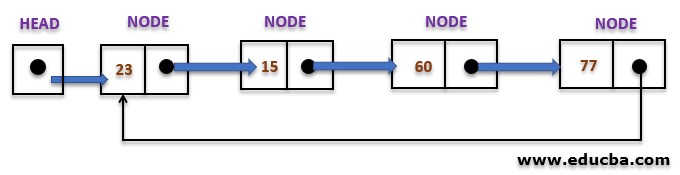
The type of circular linked list whose every node has a pointer to its next node only is known as a singly circular linked list.
Syntax:
struct Node{
char data;
struct Node* next;
}
Here next is the pointer that points to the next node in the list.
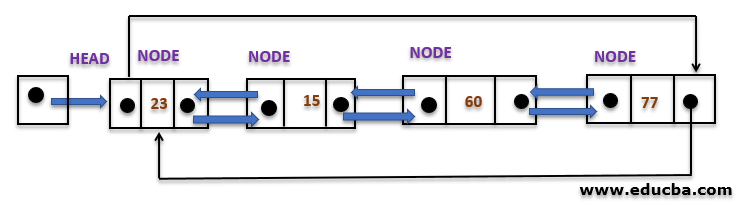
2. Doubly Circular Linked List
The type of circular linked list whose every node contains the pointer that points to its next and the next node in the list. And since it is a circular list, the last node contains the first node’s address in its next pointer, and the first node contains the address of the last node in the previous pointer.
Syntax:
struct Node{
char data;
struct Node* next;
struct Node* prev;
}
Here, a pointer points to the previous node in the linked list and next pointer points to the next node in the list. Such type of linked list in implementation of various other complex data structures.
Operations of Circular Linked List in Data Structure
Operations that can be performed on a circular linked list:
1. Insertion
INSERTFROMSTART(A,n,Head,LOC)
- Create a node T.
- Insert data to be inserted such as, T[data] =data and T[next] = HEAD[next].
- IF HEAD =NULL, i.e. empty list, Set HEAD =T and exit.
- Else if LOC = length of A, ie. Insertion of the last node, then traverse till last of list A using ptr and then T->next = ptr->next, ptr->next =T.
- Else if LOC =1, in the beginning, T->next =HEAD and HEAD=T.
- Else if traverse to the LOC and T->next = A[LOC] ->next A[LOC] -> next =T.
This algorithm takes a circular linked list A and HEAD pointer as well as n as a data to be inserted and LOC points to the location where n needs to be inserted. Here we assume, that LOC has been calculated by traversing the whole list once and maintaining a counter LOC that is updated till we find the node after which we need to insert a new node. Then a new node T is created. The first list is checked if it is null then, HEAD is updated, and it indicates there is only one element in the list after insertion. Otherwise, relevant pointers are updated to insert the node at the beginning or end or in between.
2. Deletion
DELETE(A,n,HEAD,LOC)
- Check if list A is empty the return -1 [UnderFlow].
- Otherwise call traverse the list to location LOC of a node with Node[data]=n.
- If LOC =-1, return -1 and exit.
- Else If LOC == 1 .ie first node:- Set Head =NULL and exit.
- Else A[LOC -1]->next = A[LOC]->next.
This algorithm checks first if the given list is empty then indicates, and Underflow situation otherwise checks at which location deletion needs to be performed and update the pointer accordingly.
3. Traversal
TRAVERSE(A, HEAD)
- take a ptr =HEAD
- Repeat Steps 3 and 4 till ptr->next !=HEAD
- Print[ptr]
- ptr=ptr->next
This algorithm is used to traverse the whole circular linked list and perform a print operation for each node using a pointer ptr that points to the current node of the list. The condition ptr->next !=HEAD is used to observe if any node is not traversed twice.
Benefits of Circular Linked List in Data Structure
- One can start traversal of the complete linked list from any node since all nodes are lined, and there is no endpoint. While traversal, we need to observe not to traverse one node twice.
- Such data structure is most often used for implementing a queue, and since it is a circular list, only one pointer needs to be maintained, i.e. HEAD to store the last inserted node that marks as REAR and FRONT can easily be found.
- Doubly Circular linked lists can also be used to implement various complex data structures such as Fibonacci Heap.
- OS also uses it to maintain the execution of the various process to run the list continuously. A continuous queue is maintained running with a continuous loop, where each process enters once the CPU is busy and not available. Such a queue is also known as the waiting queue. Various other queues such as priority queue or resources queue are also maintained using this data structure.
- Such data structure can also be used in case of multiplayer games where all the players are entered in a continuous circular linked list and the pointer gets incremented once every player’s chance is over.
Conclusion
A circular linked list is a type of data structure where a loop is maintained used by storing the first node of the list in the last node of the linked list, thus named circular. Such a list helps build a continuous loop used in various games or complex data structures such as the Fibonacci series.
Recommended Articles
This is a guide to Circular Linked List in Data Structure. Here we discuss Circular Linked List operations in Data Structure and its types along with its Code Implementation. You can also go through our other suggested articles to learn more –
