Updated November 15, 2023
Introduction to Classification vs Clustering
Data analysis and machine learning are two key fields that heavily rely on classification and clustering techniques. These two techniques are fundamental in their respective fields, aiding in the organization, analysis, and interpretation of large data sets. Classification involves grouping data into predefined categories based on certain features, which allows for predictive tasks like identifying objects or assigning labels. On the other hand, clustering groups data based on similarity without predefined categories, revealing hidden patterns or structures within the data. Both classification and clustering methods are crucial in organizing and extracting insights from large datasets, aiding decision-making and pattern recognition in various domains, ranging from image recognition to customer segmentation.
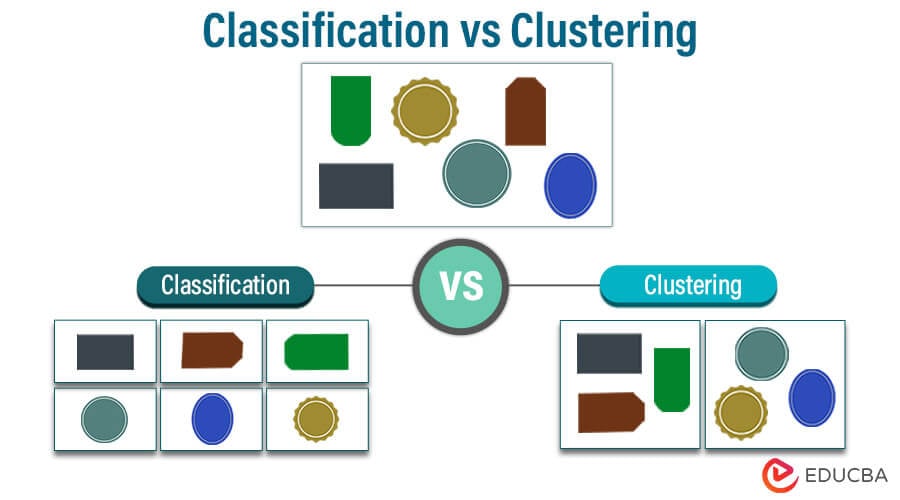
Table of Contents
- Introduction
- Classification- a supervised Learning Technique
- Clustering – an unsupervised Learning Technique
- Difference Between Classification and Clustering
- Similarities Between Classification and Clustering
- Should I use classification or clustering
Classification – Supervised Learning Technique
Classification is a supervised learning technique in machine learning. It involves assigning data points to categories based on their features. It involves training a model on a labeled dataset, where each data point is associated with a known category. The model learns to predict new, unlabeled data by generalizing from the training examples. Several popular classification algorithms include decision trees, support vector machines, and neural networks. These algorithms help categorize data and make predictions based on past data patterns. Classification is widely used in applications such as spam detection, image recognition, sentiment analysis, and medical diagnosis. It helps automate decision-making and categorization tasks in diverse fields.
Types of Classification
Classification tasks come in various forms to address different data scenarios. Here are descriptions of five common types of classification:
1. Binary Classification
Data is categorized into two mutually exclusive classes in binary classification. For instance, it can predict whether an email is spam (class 1) or not spam (class 2). Common algorithms include logistic regression and support vector machines.
2. Multiclass Classification
Multiclass classification extends the binary classification concept to scenarios with more than two classes. Here, data is assigned to one of several possible categories. For example, classifying images of animals into categories like dogs, cats, and birds. Regarding multiclass classification, algorithms such as decision trees and neural networks are commonly used.
3. Multi-label Classification
Each data point can simultaneously belong to one or more classes in multi-label classification. This is suitable for problems where data can have multiple attributes or labels. For instance, classifying articles into various topics like “science,” “technology,” and “health.” Multi-label classification can use techniques like binary relevance or label powerset.
4. Imbalanced Classification
Imbalanced classification deals with datasets where one class significantly outnumbers the other. Biased models can result from favoring the majority class, leading to potential problems. Techniques like resampling, using different evaluation metrics (e.g., F1 score), and modifying algorithm parameters can address this issue and make the model more sensitive to the minority class.
5. Hierarchical Classification
In hierarchical classification, data is categorized hierarchically, with classes organized into a tree or network structure. This allows for a more granular and structured way of classifying data. For example, classifying animals hierarchically might start with the broad category of “mammals” and then further classify them into “primates,” “canines,” and “felines.” Hierarchical classification can help manage complex and nested classification problems.
Classification Algorithms
Below, you will find concise explanations of commonly used classification algorithms:
- Logistic Regression: A linear model used for binary and multiclass classification by modeling the probability of a data point belonging to a particular class.
- Decision Trees: Tree-like structures are used to make decisions by splitting data based on features and are often used for binary and multiclass classification.
- Random Forest: An ensemble technique that integrates numerous decision trees to enhance precision and mitigate overfitting in classification assignments.
- Support Vector Machines (SVM): A method that finds a hyperplane to separate data into different classes, aiming to maximize the margin between them.
- K-Nearest Neighbors (K-NN): Assigns a class to a data point based on the classes of its nearest neighbors in the feature space.
- Naive Bayes: A probabilistic algorithm that relies on Bayes’ theorem to classify data based on the likelihood of certain features occurring in each class.
- Neural Networks: Deep learning models with multiple layers of interconnected nodes are used for complex classification tasks, such as image recognition.
- Gradient Boosting: An ensemble technique that combines weak learners into strong ones, often using decision trees, to improve classification accuracy.
- Ensemble Methods: Techniques like AdaBoost and Gradient Boosting combine multiple models to enhance classification performance.
- Categorical Algorithms: Specialized algorithms like XGBoost and CatBoost are designed to handle categorical data efficiently in classification problems.
- Deep Learning: Image and sequence-based tasks employ deep neural networks, such as CNNs for image classification and RNNs for sequence-based tasks.
Applications of Classification
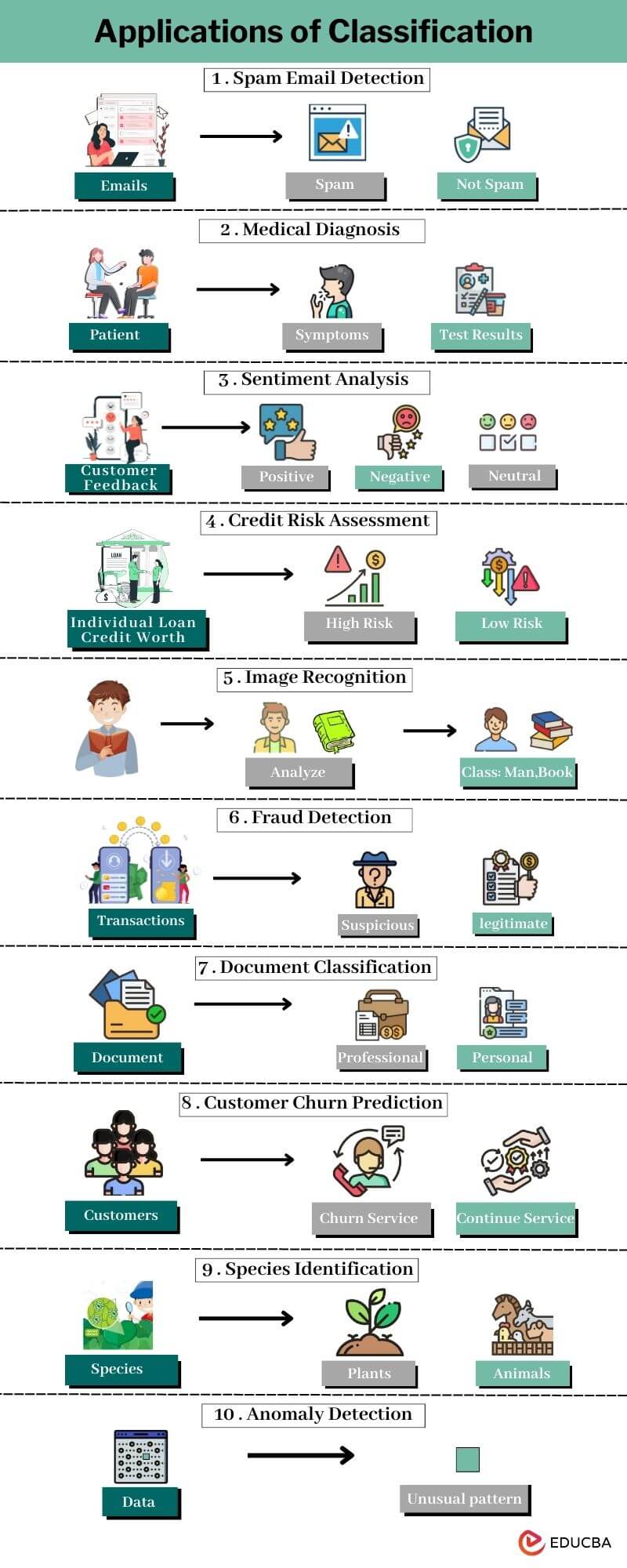
Below are some important applications of classification:
- Spam Email Detection: Classify emails as spam or not to protect users from unwanted or malicious messages.
- Medical Diagnosis: Aid in diagnosing diseases by classifying patient symptoms and test results into specific medical conditions.
- Sentiment Analysis: Determine the sentiment (positive, negative, or neutral) of text data, which helps analyze customer feedback and social media content.
- Credit Risk Assessment: Assess the creditworthiness of individuals or businesses, classifying them as high or low risk for lending purposes.
- Image Recognition: Identify objects or patterns in images, enabling applications like facial recognition and autonomous vehicles.
- Fraud Detection: Detect fraudulent transactions or activities by classifying them as suspicious or legitimate.
- Document Classification: Automatically categorize documents into predefined classes, streamlining information retrieval and management.
- Customer Churn Prediction: Predict which customers will likely leave a service or product, allowing for targeted retention efforts.
- Species Identification: Classify plants and animals based on characteristics, aiding in biodiversity and ecological studies.
- Anomaly Detection: Identify unusual patterns or events in data essential for cybersecurity and quality control in manufacturing.
Clustering – Unsupervised Learning Technique
Clustering is an unsupervised learning technique in machine learning that involves grouping similar data points into clusters or categories without prior knowledge of class labels. It seeks to uncover hidden patterns and structures within datasets by analyzing data similarities and differences. Clustering algorithms like K-Means and hierarchical clustering are commonly used for customer segmentation, image segmentation, and anomaly detection tasks. Clustering is crucial in exploratory data analysis, data compression, and simplifying complex datasets, facilitating better understanding and decision-making in various fields.
Types of Clustering
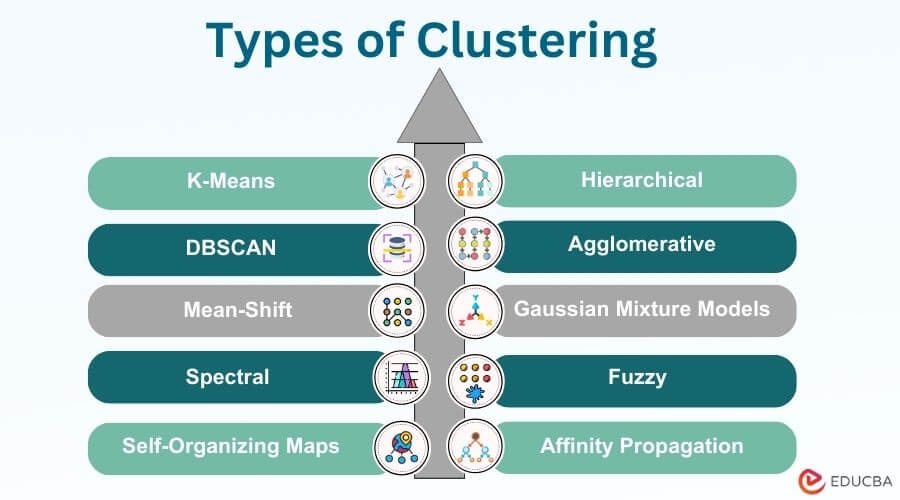
Various clustering methods are available, each designed for specific data characteristics and objectives.
- K-Means Clustering: Groups data points into a predetermined number of clusters, aiming to minimize the variance within each cluster. It’s widely used and efficient but assumes clusters are spherical and equally sized.
- Hierarchical Clustering: Forms a tree-like structure of clusters, allowing for both agglomerative (bottom-up) and divisive (top-down) approaches. It provides insights into hierarchical relationships among data points.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Identifies clusters based on data density, forming clusters of varying shapes and sizes. It can uncover outliers as well.
- Agglomerative Clustering: A hierarchical clustering method commences by considering individual data points as clusters and subsequently merges them step by step according to their similarity until a predefined stopping condition is satisfied.
- Mean-Shift Clustering: Shifts cluster centroids to areas with high data point density, making it suitable for irregularly shaped clusters.
- Gaussian Mixture Models (GMM): Multiple Gaussian distributions are used to model data, allowing for soft assignments of data points based on probabilities.
- Spectral Clustering: Utilizes the eigenvectors of the similarity matrix to identify clusters, often effective for graph-based data or data with non-linear relationships.
- Fuzzy Clustering: Clusters are assigned degrees of membership, indicating data points’ extent of belonging to multiple clusters, useful in ambiguous cases.
- Self-Organizing Maps (SOM): Organizes data points on a grid, preserving the topology of the input space. It’s used for visualization and feature extraction.
- Affinity Propagation: This algorithm is suitable for scenarios where the number of clusters is unknown in advance, as it identifies the best exemplars that represent each cluster.
Applications of Clustering
- Customer Segmentation: Clustering helps businesses group customers with similar behavior, enabling targeted marketing and product customization.
- Image Segmentation: In computer vision, images are partitioned into meaningful regions, aiding object recognition and image processing.
- Anomaly Detection: Identify outliers or unusual patterns in data, which is critical for fraud detection and network security.
- Genomic Analysis: Cluster genes or proteins based on similarities, revealing insights into genetic relationships and functions.
- Recommendation Systems: To offer tailored recommendations for products, services, or content, it’s possible to group users with similar preferences into clusters.
- Text Document Clustering: Categorize large document collections into topics, simplifying information retrieval and organization.
- Social Network Analysis: Aiding in detecting communities and network analysis, group individuals with similar connections and interests.
- Market Basket Analysis: Identify groups of products frequently purchased together, which helps optimize inventory and promotions in retail.
- Natural Language Processing (NLP): Cluster text data to uncover themes, trends, or document similarities in textual datasets.
- Medical Image Analysis: Medical images are clustered to aid in disease diagnosis and treatment planning, especially in radiology and pathology.
Differences Between Classification and Clustering
| Aspect | Classification | Clustering |
| Objective | Categorize data points into pre-defined groups based on their features. | Group data points based on similarity without predefined categories. |
| Supervision | Supervised learning: Requires labeled data for training. | Unsupervised learning: Does not require labeled data. |
| Output | Assigns data points to specific classes or categories. | Forms clusters or groups based on similarity. |
| Use Cases | Used for tasks like spam detection, image recognition, and medical diagnosis. | Applied in customer segmentation, anomaly detection, and document organization. |
| Training Data | Requires labeled data with known categories. | Operates on unlabeled data or does not rely on predefined categories. |
| Evaluation Metrics | Commonly evaluated using metrics like accuracy, precision, and recall. | Assessed with metrics like silhouette score and Davies-Bouldin index. |
| Algorithm Examples | Logistic Regression, Decision Trees, Support Vector Machines. | K-Means, Hierarchical Clustering, DBSCAN. |
Similarities Between Classification and Clustering
Both classification and clustering are data analysis techniques, however, they have several similarities:
- Pattern Recognition: Both classification and clustering aim to identify patterns or structures in data. Classification identifies patterns to assign data points to predefined categories, while clustering identifies patterns to group data points based on similarities.
- Data Exploration: You can use them for exploring data and gaining insights into datasets. Classification helps understand the relationships between features and class labels, while clustering uncovers hidden structures in the absence of predefined labels.
- Machine Learning: Both techniques are fundamental in the field of machine learning. Classification is a supervised learning task, while clustering is an unsupervised learning task, but they share fundamental principles and algorithms.
- Preprocessing: In some cases, preprocessing steps such as feature selection or dimensionality reduction can be applied to both classification and clustering to improve their effectiveness in handling complex data.
- Real-World Applications: Both are applied to a wide range of real-world applications, including image analysis, customer segmentation, and anomaly detection, where understanding patterns and relationships in data is essential.
Should I use classification or clustering?
Whether to use classification or clustering depends on the specific goals and characteristics of your data analysis task:
Use Classification When
- You Have Labeled Data: If your dataset includes predefined categories or class labels for each data point, and your goal is to assign new data points to these known categories, classification is the appropriate choice. For example, a task involves categorizing emails into either spam or non-spam.
- Predictive Tasks: When your primary objective is to make predictions and assign labels to new, unlabeled data, such as customer churn prediction or sentiment analysis, classification is ideal.
- Decision-Making: Classification is crucial if your analysis involves making decisions or recommendations based on the categorized data. For instance, credit risk assessment for loan approval.
Use Clustering When
- You Lack Labeled Data: If your dataset does not contain predefined categories or class labels and aims to discover natural groupings or patterns within the data, clustering is the appropriate approach. This is common in exploratory data analysis.
- Data Exploration: When you want to gain insights into the underlying structure of your data, uncover hidden patterns, or identify relationships among data points without the need for predictive modeling.
- Feature Engineering: On the other hand, if you require more predefined labels and aim to uncover natural groupings and patterns within data, you would use clustering.
- Anomaly Detection: Clustering can also be used for anomaly detection, where data points that don’t belong to any cluster are considered anomalies.
Conclusion
Classification and Clustering are fundamental techniques in data analysis and machine learning, each serving distinct purposes. Classification is suitable when you have labeled data and want to predict and assign data points to predefined categories. On the other hand, if you require more predefined labels and aim to uncover natural groupings and patterns within data, you would use clustering. The choice between classification and clustering should be based on your specific goals, the nature of your dataset, and the need for predictive modeling or exploratory data analysis. In some cases, combining both techniques may be the most appropriate approach to gain deeper insights and make data-driven decisions.
Frequently Asked Questions
Q1. What are some challenges in classification and clustering?
Answer: Challenges in classification include dealing with imbalanced data and selecting appropriate evaluation metrics. Clustering challenges involve determining the optimal number of clusters and handling data with varying shapes and densities.
Q2. Can clustering be used for predictive modeling?
Answer: While clustering itself is not a predictive modeling technique, the resulting clusters can serve as a feature engineering step to improve the performance of subsequent classification or regression models.
Q3. What are some common evaluation metrics for classification and clustering?
Answer: Common metrics for classification are accuracy, precision, recall, and F1 score. Clustering uses metrics like silhouette score, Davies-Bouldin index, and Rand Index to assess cluster quality.
Q4. How can I determine whether my data is better suited for classification or clustering?
Answer: Consider your objectives. If you want to assign data points to predefined categories or predict outcomes, use classification. Choose clustering if you want to explore the structure within your data or group similar data points. The nature of your data, whether it’s labeled or unlabeled, also plays a significant role in this decision.
Recommended Article
We hope that this EDUCBA information on “Classification vs Clustering” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

