Updated March 15, 2023

Introduction to Cloudera Data Platform
Cloudera Data Platform is a Hybrid Cloud Platform designed for any cloud, analytics, and data. Cloudera Data Platform manages and secures data lifecycle across major public and private clouds. CDP seamlessly connects on-premise environments to public clouds for a hybrid cloud experience. Cloudera Data Platform is a big platform for the Business and IT field as it is simple to use and is secured by design. Let us dig deeper into CDP and see through its services, Architecture, and Benefits.
Cloudera Data Platform Overview?
As an extensible and open platform, it is mostly used by data engineers and scientists. In addition, CDP is available on-premises and public cloud and is both manual and automated.
CDP is a platform with two form factors: CDP Public Cloud and CDP Private Cloud
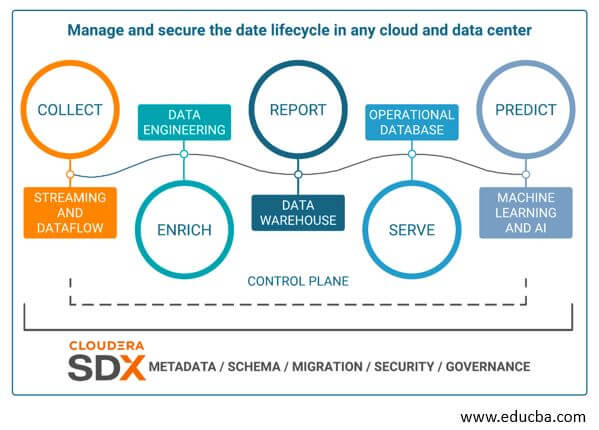
CDP gives a data-driven decision that makes connecting with real-life cycle data easier, quicker, and safer. Data moves in the lifecycle with five phases.
CDP provides visibility into all data with no blind spots; the control plane allows managing data, analytics, infrastructure, and workload across multi-cloud environments with all Cloudera shared experiences providing security consistently and governance across the life cycle.
Cloudera Data Platform Services
In the Public Cloud of CDP, we have cloud services designed to address enterprise data cloud use cases, including Data Hub by Cloudera Runtime, self-service applications like Machine Learning, Data Warehouse, Data Flow, and Data Engineering. Management Console as Administrative Layer and Data Lake, Replication Manager, Workload Manager, and Data Catalog as SDX services.
Administrative Layer: Management Console is the general service used by CDP to manage, orchestrate, and monitor CDP services from a single glass pane across environments. Suppose the user has any deployment in the data center and the multiple public clouds. In that case, the user can manage all in one place, i.e., creating, provisioning, monitoring, and destroying the services.
Workload Clusters: Data hub is the service for launching and maintaining workload clusters provided by Cloudera Runtime; it is an open-source distribution that includes CDH and HDP. It provides complete isolation of workload and elasticity so that each workload, application, and department can have a cluster with different software versions, configurations, and infrastructure. Furthermore, as data hubs are easier to launch with an automated lifecycle, users can create on-demand, and if not needed, users can return resources to the cloud.
Workload Services
Data Engineering, a serverless service, allows users to submit Spark jobs to auto-scaling clusters.
Data Flow enables users to import and deploy data flow definitions securely and efficiently. It is cloud-native and has end-to-end data flow management that gives the users a flow-centric experience than the traditional cluster-centric approach. It also reduces operational and cluster management overhead.
Data Warehouse manages and creates a self-service data warehouse for data analyst teams. This service allows users to quickly create a data warehouse and terminate once the task is done.
Machine Learning is used to create and manage a self-service Machine Learning workspace. It enables data scientist teams to develop, train, test, and deploy machine learning models to build predictive applications on data under management in the enterprise data cloud.
An operational Database is self-service for the creation of the operational database. It is an autonomous database by Apache HBase and Phoenix. Users can use it for low latency and high throughput use cases with access layers and the same storage that are familiar with CDH and HDP.
Security and Governance, Shared Data Experience, is a suite of technologies that allows enterprise users to pull all the data to one place. Users can share it with various teams and services securely and governed manner. SDX, Shared Data Experience, has four different services, i.e., Data Lake, Replication Manager, Data Catalog, and the Workload Manager.
Data Lake is a function that creates a safe, secured and governed data lake that provides a protective ring surrounding data wherever it is stored in HDFS or cloud storage.
Data Catalog is used for organizing, searching, governing data, and securing within the enterprise cloud. In addition, it is used for stewards to search, browse, and tag the content of the data lake and manage and create authorization policies.
Replication Manager is for copying, migration, snapshotting, and restoring data between environments within the data cloud. Data stewards and administrators use it to move, copy, backup, replicate and restore data in lakes or between lakes.
Workload Manager is for optimizing and analyzing the workload within the enterprise cloud and is used by database administrators for troubleshooting, optimizing workload, and analyses to improve the performance cost.
Cloudera Data Platform Architecture
If users want to create Virtual Private Cluster, they need to understand the Architecture of Compute Clusters and how it relates to Data Contexts.
- Compute clusters have been configured with compute resources like Hive or Spark execution.
- Data context is a connector to the regular cluster, designated as a Base cluster; it defines data, security services, and metadata deployed in the Base cluster required to access data.
- The Base and Compute clusters are managed by the same instance of the Cloudera Manager.
- The base cluster must have an HDFS service to be deployed and contain the Cloudera Runtime service. But, only HDFS, Atlas, Hive, Amazon S3, Ranger, and Microsoft ADLS can be shared using data context.
- HDFS or core config service is required on the compute clusters as persistent and temporary space.
- Compute clusters use services to store temporary files that are used in multi-stage Map Reduce jobs.
- Below services can be deployed to CDP as needed,
Hue, Hive Execution Service, Spark 2, Kafka, YARN, Oozie, and HDFS as requisite.
Cloudera Data Platform Benefits
- CDP can view data lineage across transient clusters and clouds.
- CDP can control the cloud costs with resume, auto-scaling, and suspend.
- CDP optimizes the workload based on analytics and machine learning
- CDP uses a single glass pane across the hybrid and multi-cloud
- CDP can scale to petabytes of data and thousands of various users.
Conclusion
With this, we shall conclude the topic “Cloudera Data Platform.” We have seen what Cloudera Data Platform (CDP) means and its services, which include Administrative Layer, Data Hub, Workload Services, and SDX services. Also looked into the Architecture of CDP, which consists of Cloudera Manager, Base Cluster, Data Context, etc. Finally, have listed out a few of the CDP Benefits to make users understand the concept better. Thanks! Happy Learning!!
Recommended Articles
This is a guide to the Cloudera Data Platform. Here we discuss a few CDP Benefits to make users understand the concept better. You may also look at the following articles to learn more –

