Updated July 4, 2023

Collect Stats in Teradata
Collect Stats in Teradata collect the statistics for one or even multiple columns of the base table specified. These statistics include the hash index, a join index, etc. The primary purpose is to collect statistical profiles of the required columns and store them in a data dictionary.
What is Collect stats in Teradata?
Collect Stats is used to gather the statistics on various columns as per the requirement. Thereafter Teradata’s optimizer creates an execution strategy that is based on these statistics collected by the COLLECT STATS command.
This COLLECT STATS command gathers data demographics and environment information, which the optimizer utilizes in order to optimize the plan for the SQL based on these tables.
Environment information consists of the below set of info:
- The amount of memory required
- The number of nodes
- AMP’s
- CPU’s
Data demographics consist of the below set of info:
- The row size of the table
- Number of rows in that table
- The entire range of values present in that table
- The number of rows available per table
- Number of Null values in that table
There is a variety of approaches available to collect statistics over a table.
- Using the sample option: This includes unique index columns, nearly unique indexes, or columns
- Full statistic collection methodology: This usually includes Non-Indexed columns, Partition for all tables whether permitted or not, and Collection of full stats over relevant columns.
- Most NUPIs refer to non-unique primary indexed columns, while UPIs stand for unique primary indexed columns.
- Apart from these, it also includes the single-column join constraints along with NUSI’s
- The Random AMP Sampling: It involves the USI’s or UPI’s if only used with equality predicates.
How to Collect Stats in Teradata?
Below is the syntax of COLLECT STATS statement in Teradata:
COLLECT [SUMMARY] STATISTICS
INDEX (name_of_the_index)
COLUMN (col_name)
ON <table_name>;Here the keyword SUMMARY is optional, and the user may skip it if not required.
Let’s take up some examples to understand how to collect stats in Teradata in detail:
COLLECT STATISTICS COLUMN(roll_number) ON Student_Table;- This will collect stats on the roll_number column of the student_table
- When the above query is executed, the below kind of output is produced
Let’s take an example to understand the optimization in detail.
Suppose we have two tables table1 and table2.
table1 contains the details of the students like id, name, age, marks, etc
whereas table2 contains the geographic info of the students like address, location along with the primary key as ID
SELECT
a.id,
a.name,
a.age,
a.marks,
b.address,
b.location
From table1 as a
left join table2 as b
on a.id = b.idLet’s consider two cases wherein the above-mentioned query gets executed.
CASE 1: When we do not have any information regarding the statistics of any columns from table1 and table2. In this case, the execution plan for the above query will be more costly.
CASE2: When we do have the specifically required information regarding the statistics of any columns from table1 and table2. In this case, the execution plan for the above query will be less costly.
The reason is, during the join, which is based on the id column from table1 and table2, it needs to be on the same AMP in order to join the data based on this column from table1 and table2
Suppose table1 contains 100 records having ID from 1 to 100 distributed evenly over 10 AMP in the below fashion.
- The records having the ID from 1 to 10 in AMP1
- The records having the ID from 11 to 20 in AMP2
- The records having the ID from 21 to 30 in AMP3
- The records having the ID from 31 to 40 in AMP4
- and so on…
- The records having the ID from 91 to 100 in AMP10
And table2 has only 80 records having ID from 1 to 100 with 20 missing ID’s
- The records having the ID from 1 to 8 in AMP1
- The records having the ID from 9 to 10 and 15 to 20 in AMP2
- The records having the ID from 21 to 28 in AMP3
- The records having the ID from 29 to 36 in AMP4
- and so on…
- The records having the ID from 92 to 100 in AMP8
Now for the join to happen, the ID’s should be available in the SAME AMP
Generally, the data from the smaller table is redistributed. So here, the redistribution will happen for table2
How can we see the statistics collected for the tables in Teradata?
The collected stats can be seen using the below query:
HELP STATISTICS <table_name>Let’s see the stats collected on Student_table
HELP STATISTICS student_tableWhen the above query is executed, The result will be something like this:
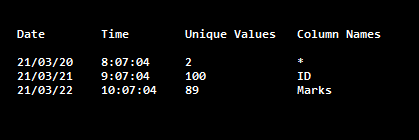
Conclusion
The COLLECT STATS command is used to gather statistics about tables, which can then be utilized to optimize queries involving those tables. These collected statistics provide valuable information about the distribution of data and can assist in generating efficient query execution plans.
Recommended Articles
We hope that this EDUCBA information on “Collect Stats in Teradata” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
