Introduction to Data Preparation
When preparing data, whether for analysis, modeling, or any other purpose, laying a solid foundation is crucial for obtaining meaningful insights and achieving accurate results. Data preparation is cleaning and transforming raw data for machine learning and business analysis. This pre-processing involves acquiring, exploring, cleansing, and transforming data for quality data analytics. Data preparation is essential for drawing meaningful insight and quality output. Raw data often contain missing values, inaccurate entries, and errors that may hinder the analytical outcome’s accuracy and reliability. Processing raw data ensures top-quality, accurate, and successful data-driven decision-making.
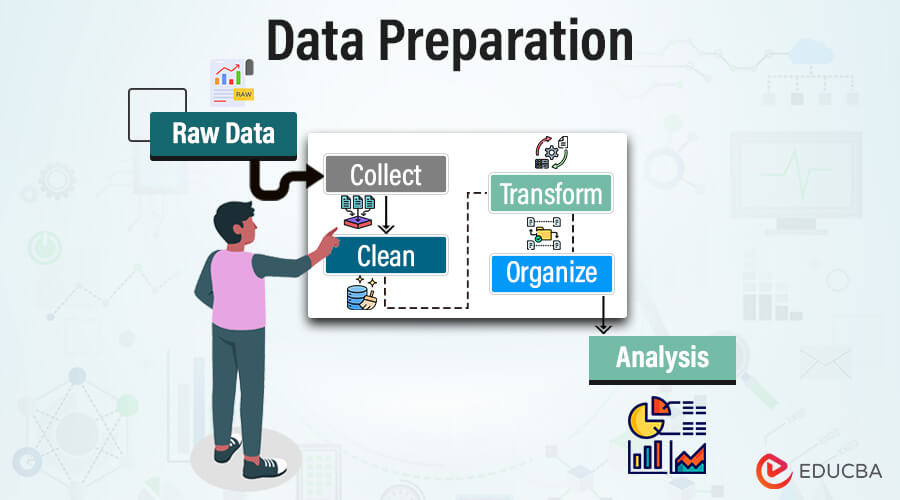
Table of Contents
Key Takeaways
- Data preparation ensures accuracy, consistency, and usability for performing analysis.
- Enhance data quality and improve decision-making.
- Cloud-based data storage ensures scalability, flexibility, and accessibility to store massive amounts of data.
- Pre-processing provides relevant data for business analysis and machine learning.
Purposes of data preparation
Data preparation is crucial to ensure data reliability and accuracy in data analysis and decision-making processes. The following outlines some of the main goals of data preparation:
Data Cleaning and Standardization:
Data cleaning includes identifying and resolving the raw data, which often brings in errors, missing points, inaccuracy, or inconsistency. Standardization provides uniformly formatted data, making comparing and analyzing different datasets easy. It involves converting currencies and measurement units and formatting data into a standardized format.
Data Integration:
We usually extract data from several sources into a single dataset. Data preparation includes integration processes like merging, joining, and blending to ensure that the data from different databases and files like multiple spreadsheets, APIs, and IoT devices combine to form one unified copy of data.
Data Transformation:
In data preparation, data transformation is manipulating raw data to make it relevant for data analysis. It involves reshaping data structure, aggregating data, or summarizing data to get meaningful insight from the dataset. Transformation techniques such as creating variables, calculating derived metrics, and mathematical operations are applied to raw data to extract required information.
Handle Missing Values:
Missing value is a critical issue in a dataset that significantly impacts the data analysis result. Different techniques are employed to handle these missing values, such as the imputation method and predictive modeling to estimate missing values. Handling missing values is essential to ensure data integrity and provide unbiased analysis.
Data Reduction:
Data reduction is an essential technique to reduce the dimensionality of the dataset while conserving the relevant information. It involves reducing noise or redundancy in data and extracting a subset of informative features for analysis. Data scientists employ dimensionality reduction techniques to enhance the effectiveness and performance of analytical models.
Enhance Data Quality:
Data preparation ensures the data quality by validating the datasets’ integrity, accuracy, and consistency. It includes applying quality control measures to check data completeness, business rules consistency, and resolving data anomalies. Data quality is essential for maintaining reliability and providing trustworthy analytical results for effective decision-making.
What are the benefits of data preparation?
The most significant benefit of data preparation is that the data scientist can focus more on data analysis and mining instead of data cleaning and structuring. Data preparation eliminates the biased result and allows multiple users to use the prepared data for deployment readily. Data preparation has several other benefits:
Data Cleanliness and Reliability:
Data preparation is the process of cleaning, validating, and transforming raw data before utilizing it in any analytical application. It involves removing duplicates, correcting errors, standardizing formats, and handling missing values to provide a usable data format with cleanliness and reliability. Clean data ensures meaningful insights and minimizes errors in analytical output.
Example:
A marketing team analyzes customer feedback data to understand the problem area and improve product features. The team removes duplicate data, corrects errors, and standardizes the date and time format using different tools and techniques for detecting outliers and correcting data. It ensures accurate insight into customer requirements and prioritizes improvement according to customer expectations.
Detect problem area:
Data preparation comprises cleaning and thoroughly examining data, which helps detect potential undetected problem areas. It allows data scientists to understand the data quality, structure, and possible issues that might raise a problem in data analysis. The organization ensures robust and reliable outcomes by detecting and addressing missing values, inconsistencies, and outliers.
Example:
A retail chain detects inconsistencies in the sales data while tracking weekly profits. After investigations, they revealed an incorrect date format, skewing the profit analysis. Early detection of potential issues allows them to resolve any inconsistencies before they affect the decision-making.
Better decision-making:
Effective and clean data preparation provides executive and operation–related professionals with timely, efficient, and high-quality business decision-making. High-quality data delivers insight with relevant information, allowing decision-makers to quickly respond to changing market conditions and competitive pressures. It improves the organization’s adaptability and agility, leading to better strategic and operational decisions.
Example:
A marketing team prepares reliable data on the customer’s demographics, purchase history, and engagement metrics. This information allows the marketing team to analyze data using predictive techniques and tailor the company’s advertisement campaigns according to the customer’s preference, and this ensures an increase in sales and customer satisfaction.
Reduce Costs:
Well-prepared data streamlines the analytics process and minimizes inefficiencies leading to cost reduction. Organizations can reduce the resources and time required for data management by automating repetitive tasks and eliminating manual errors. Additionally, optimizing the accuracy and efficiency reduces the analytics cost and refines productivity and scalability.
Maximize Return on Investment (ROI):
In data preparation, better decision-making and cost reduction maximize the return on investment from Business intelligence and analytics initiatives. Organizations that invest in clean and reliable data preparation generate accurate insights, mitigate risks, and optimize results. It enhances operational efficiency, drives business performance, and enhances ROI.
Example: A healthcare center invests in data preparation tools and techniques that ensure the accuracy and reliability of the information about patient records. It helps the healthcare team identify trends in patient results, aids the team in improving the healthcare protocols, reduces cost, and enhances patient care, treatment, and organizational return on investment.
Steps in the data preparation process:
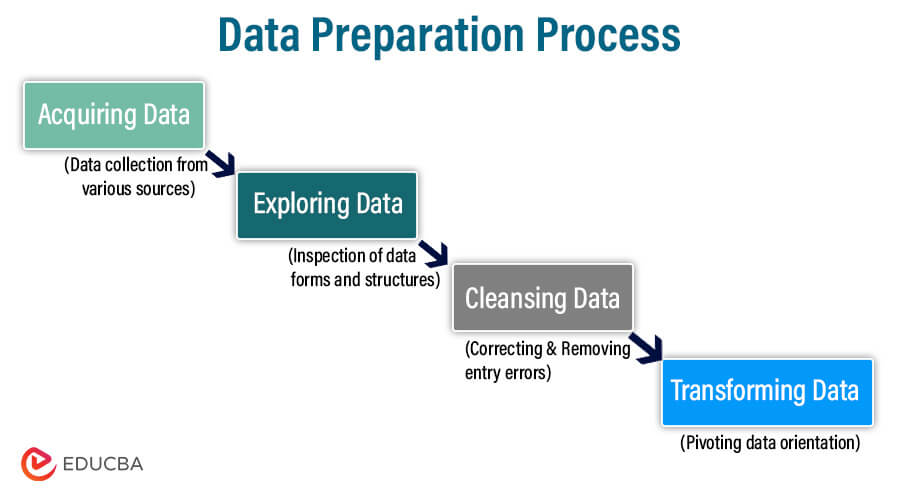
The data preparation can be time-intensive, iterative, and repetitive. The process may vary according to the industry requirement, and it is essential to ensure that each step in the data preparation process is understood, repeated, revisited, and revised by data analysts and scientists to minimize the time required for data preparation and maximize time for data analysis.
The four crucial steps for data preparation are as follows:
1) Acquiring Data:
Researchers need to collect data from different sources before analyzing it. The analysts don’t collect data themselves but rely on data-extracting IT experts or engineers who use special tools and platforms to collect data and deliver it to data analysts in the form of spreadsheets. But nowadays, as technology has enhanced, data analysts extract data themselves using tools like ETL, Microsoft Azure, IBM, SQL Server Management Studio, Oracle SQL Developer, etc.
2) Exploring Data:
After getting the data, analysts inspect the data closely to understand its forms and structures. If the data is too large, data scientists break it into smaller chunks or use tools that work with tiny bits. Analysts note incomplete data points during data examination and execute solutions to fix them. Sometimes, after data inspection, it is concluded that data or a part of data is irrelevant for further analysis.
3) Cleansing Data:
Data cleansing is a process of enhancing the quality and accuracy of the data. There are four significant steps executed to cleanse data.
- Correcting entry errors– Correcting spelling mistakes, text standardization, and proper naming conventions.
- Removing duplicates and outliers – The data may have two or more identical records. It can skew the data analysis. Hence it is made sure that data has identical records only. Outliers are records that are diverged from the rest of the data points. Outliers are identified and corrected.
- Eliminating missing data– Analysts interpret data using existing data and fill in the empty records. Analysts directly eliminate data if the missing information relates to non-valuable data.
- Masking confidential data– Data sets also include personal information like ID, password, and important numbers, and it becomes necessary to recognize and protect such data using standard protocols like HIPAA and GDPR.
4) Transforming Data:
This step involves transforming the data format, structure, or data points to become more suitable for further analysis. Three main steps are the following:
- Pivoting data orientation incorporates formatting the data into proper rows and columns and bringing it into an analytic format.
- Converting data types: Data analysts often convert data containing strings, integers, and booleans into a single data type for easier understanding and analysis.
- Aggregating data scales: Data aggregating or summarizing data across different periods to analyze trends, patterns, or performance over time. It could include calculating averages, sums, or other aggregate statistics across days, months, quarters, or years. It helps understand the overall performance or behavior of a system, process, or entity over time and facilitates time-series analysis.
Data Preparation for Machine Learning
In artificial intelligence, machine learning uses algorithms or models to learn data for making decisions and predictions. The algorithm requires massive structured and unstructured data to train and improve their performance. Integrating raw data with cloud and machine learning models is challenging, as invalid and missing values result in inaccurate models. Data scientists/analysts invest significant effort in data preparation to build efficient and accurate machine-learning models.
Data scientists spend 45% of their time cleaning and loading data, according to the survey by Anaconda. The self-service data preparation tools benefit data scientists by automating a significant amount of the data preparation process and ensuring they focus more on higher-value activities.
Data Preparation Trends
1. Automated data preparation:
With exploding data volume, organizations are shifting to automated data preparation tools for efficient data cleaning, transforming, and integrating. These leverage machine learning and artificial intelligence techniques to automate repetitive tasks, enhance efficiency, reduce manual teamwork, and cut the extra cost.
2. Self-service data preparation:
Self-service data preparation platforms empower businesses with features for preparing and analyzing data without technical expertise. These tools provide a user-friendly interface and drag-and-drop features for interacting with data visually and iteratively
3. Data quality management:
Poor quality data leads to ineffective analytics initiatives and decision-making processes. Advanced tools for data preparation provide built-in quality management capabilities for quickly identifying and resolving missing values, inconsistencies, outliers, and duplicate data issues. It ensures accurate, reliable, and complete data.
4. Advanced analytics and machine learning:
Data preparation is crucial to advanced analytics and machine learning initiatives. Adequate data preparation incorporates feature engineering, reprocessing, and normalization to ensure accurate and robust predictive models.
Benefits of Data Preparation in the Cloud
Big data environments store information in multiple ways. The data lakes allow users to store structured, unstructured, or semi-structured data at any scale. These enable the storage of vast amounts of data in their raw or natural condition from any sources for predictive analysis or machine learning, which require large swatches of data.
The organization typically stores these data lakes in on-premises data centers or cloud-based storage systems. The on-premises data centers limit the scalability, increase operational costs, and consume time for working with large datasets. As data exploded, the demand for cloud-based storage increased, allowing data scientists to access data easily via the internet, scale data usage on demand, and boost data preparation speed while leveraging the cloud’s improved security and governance.
As data and data processes increasingly move to the cloud, data preparation also moves for even more significant benefits:
Better Scalability:
Cloud-based storage provides unlimited computing resources on demand, allowing businesses to scale up their infrastructure or plan for long-term evolution according to their need. Cloud storage scales data preparation to process vast amounts of data and even handles sudden spikes in workload. Hence, the cloud-based data preparation tools ensure optimal performance by dynamically scaling up or down to varying demands.
Future-ready:
Cloud-native data preparation tools ensure that businesses are future-ready to seamlessly integrate upgrades and patches for bug fixes without manual intervention. Cloud-native tools streamline data preparation workflow, effective team collaboration, automatic updates, and integration with other cloud services. Contribute businesses with the latest features without incurring additional costs, and adapt continuously to technological advancement and changes.
Faster access and collaborative use of data:
Cloud-based data preparation facilitates quick access to data and empowers collaborative use among team members. The cloud-based ongoing process does not require any complex technical installation or setups. The cloud’s simplicity and accessibility provide quick output and decision-making with better teamwork and communication. The user-friendly interface offers seamless collaboration and easy data preparation with an intuitive graphical user interface. It enables teams with different skill levels to process data effectively to achieve common goals.
Security and Compliance
Cloud-based data preparation benefits the organization with security measures provided by service providers. Service providers invest in security protocols such as encryption, data masking, and access control, ensuring security for sensitive data from unauthorized access. Cloud platforms comply with the standards and regulations of the industry, such as GDPR and HIPAA, to ensure data handling practices meet legal requirements. The cloud security features mitigate security risks and maintain compliance more effectively.
Hybrid Approaches:
In data preparation, hybrid approaches integrate the scalability and flexibility of cloud-based solutions with the security and control of on-premises infrastructure. The organization benefits from the hybrid architecture to manage processing and data storage between cloud and on-premises environments. With a hybrid approach, the organization can retain sensitive data on-premises and utilize the cloud to scale and process large datasets for intensive analytics tasks. The hybrid approach optimizes performance and provides cost-effective solutions for specific requirements, benefiting both the on-premises and cloud environments.
Case Studies
Scenario
Consider an organization dealing with clients and customers. The company uses a relationship management tool to analyze and improve its conversations and transactions with its clients and customers.
Challenges
1) Companies collect customer feedback and conversations from various sources (calls, emails, video calls, feedback forms). This results in data with diverse forms and structures. Bringing all these data in one form for further analysis is difficult.
2) Data analysts (or systems) must correct inconsistencies, errors, and missing values in this information from different sources before processing it further.
3) Handling sensitive customer data requires strict compliance with regulations like GDPR or HIPAA, adding more complexity to data preparation.
4) With increasing data size, the complexity of data also grows. In this case, traditional data preparation methods need to be in handy.
Solutions
The process for data preparation:
1) An organization that deals with massive amounts of data often provides its employees with data integration tools like ETL (extract, transform, load). As the name suggests, the data is extracted from different sources, converted into desired forms, and provided to users.
2) The organization appoints experts to execute different algorithms like descriptive statistics and regression analysis, which are part of the statistical approach, and machine learning decision trees that can be used to clear errors and inconsistencies in the data.
3) Scripts or tools are developed to standardize data formats, convert categorical variables into numerical representations, and normalize numerical data.
4) The organization opts for security protocols and frameworks like the DGI (Data Governance Institute) framework, GDPR (General Data Protection Regulation), and COBIT (Control Objectives for Information and Related Technologies) for its data protection and safe transactions.
5) Visual methods are also used to ease the data preparation process. These methods mainly incorporate charts like histograms.
Best Practices
Best Practices for Efficient and Effective Data Preparation
- Understand consumers:
Always understand the data consumers. It’s crucial to know data consumers and the insight they are seeking. Organizations tailor the data preparation process by understanding the end user and their requirement. These ensure relevant, actionable, and accurate data for decision-making purposes.
- Know Data Sources:
Knowing the data origin and sources is essential for maintaining data quality and reliability. By acknowledging the data source, organizations can determine its relevance, credibility, and potential biases allowing data analysts to make informed decisions about the data use and interpretation.
- Preserve Raw Data:
Preserving Data in its raw or original form is essential for data audibility and reproducibility. Maintaining raw data allows data analysts to recreate data transformations and examine any errors or differences arising amidst the data preparation process. In addition, retaining raw data facilitates future analysis or reprocessing if required.
- Compliance and storage:
Organizations should store and maintain data and its processed output in compliance with laws and regulations. It ensures the insight of data privacy laws, data retention policies, and security requirements according to the organization’s operations. Maintaining both the natural and processed data provides data handling transparency and audibility.
- Data Pipeline Documenting and Monitoring:
Documenting and monitoring the data pipeline is crucial for adequate data preparation. Documenting data pipelines, including data source, transformation, and analysis codes, is essential for transparency, reproducibility, and collaboration. Data monitoring allows detecting and resolving inconsistencies and errors in data sets. Hence, it ensures data quality, reliability, and integrity of analytics outcomes.
- Proactive Data Governance:
Implementing proactive data governance is essential to data security and quality. These measures implement data masking or encryption techniques for protecting sensitive information and enforcing permissions based on controlling resource access.
Challenges of data preparation
Data preparation is a crucial aspect where datasets are obtained from several sources with multiple quality, accuracy, and consistency. To address these issues, data needs to be reworked to make it user-friendly and remove all the irreverent data. Some challenges faced during the data preparation process are as follows:
- Insufficient Data profiling:
Insufficient data profiling results in errors, anomalies, and issues during data analytics. Organizations may only produce reliable and accurate results with a comprehensive understanding of data structure, characteristics, and quality.
- Missing or incomplete Data:
More values and complete records are needed for efficient data analysis and decision-making. To avoid these obstacles measures such as imputation techniques, data cleansing, or revisiting datasets are essential for complete data processing.
- Invalid values:
Unexpected analytic errors arise due to invalid values in datasets, such as spelling mistakes, typos, or incorrect entries. Identifying and resolving these invalid values is essential for obtaining data accuracy and integrity.
- Name and Address Standardization:
Standardizing the names and addresses in data sets is essential to ensure consistency and accuracy during data analysis. Standardizing prevents inconsistencies and variances to provide efficient data interpretation and decision-making.
- Inconsistency across Systems:
Inconsistencies in data formats or identifiers across the system lead to significant challenges during the data preparation. Addressing these irregularities in data necessitates data transformation, mapping, and reconciliation to successfully sync data across different sources.
- Setting Up and Maintaining Data Prep Process:
Maintaining and enhancing the data preparation process for standardization and repeatability is crucial. It requires outlining a clear workflow for data preparation, robust implementation for data quality, and improving processes to adapt to the changing business requirements.
Conclusion
Data preparation is a crucial aspect of data analysis, which transforms raw data into a clean and structured format before processing. Data preparation provides meaningful insight into data and improves decision-making for businesses. Various algorithms are implemented to automate the processing process to minimize the time and cost requirements. Overall, data preparation enhances the quality and reliability of data, leading to accurate results.
Frequently Asked Questions (FAQs)
Q1) How is audio data processed in data preparation?
Answer: One of the commonly used techniques is Automatic speech recognition. Deepgram is a popular service provider that provides a robust solution for converting audio-like call recordings into formatted data. It uses neural networks that analyze audio data accurately and extract significant perceptions. Businesses widely use this technology in customer care services.
Q2) What are the majority and minority classes in the data preparation process?
Answer: Majority class and minority class categories of data sets have an extreme impact on data analysis.
Majority class: The data in this category has many instances and observations. It is used to predict the dominant results of data analysis.
Minority class: Unlike the Majority class, the minority class has the least number of instances and observations, and they don’t have a dominant impact on data preparation and visualization.
In the case of Machine learning, when the data set is imbalanced, results are mainly estimated using the majority class, and the minority class doesn’t play a crucial role. It leads to biased predictions. Hence, imbalanced data sets are first enhanced to get accurate predictions using minority and majority classes.
Q3) How are images and videos used in the data preparation process?
Answer: Images and videos can provide rich quality data, but the only challenge here is to extract accurate data from images and videos.
Some popular techniques for accurate data extraction are convolution neural networks (CNN), Data augmentation, annotations and labeling, semantic segmentation, etc., which are used to pre-process, extract, and transform data from images and videos.
Recommended Articles
We hope that this EDUCBA information on “Data preparation” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
