Definition of Data Preprocessing
Data preprocessing is a crucial step in data mining. Raw data is cleaned, transformed, and organized for usability. This preparatory phase aims to manipulate and adjust collected data to enhance its quality and compatibility for subsequent analysis. This process includes handling missing values, removing duplicates, normalizing, transforming, and reducing data dimensionality. The ultimate goal of data preprocessing is to ensure that the data is accurate, consistent, and suitable for efficient analysis by machine learning algorithms or other data mining techniques. In short, data preprocessing is a necessary step that ensures the data is ready for modeling and analysis.
Table of Contents
- Definition of Data Preprocessing
- Importance of Data Preprocessing in Data Mining
- Steps in Data Preprocessing
- Case Studies
- Future Trends in Data Preprocessing
Importance of Data Preprocessing in Data Mining
Data preprocessing plays a pivotal role in the effectiveness of data mining for several reasons:
- Improved Data Quality: It helps clean noisy data, handle missing values, and resolve inconsistencies, which significantly enhances the quality and reliability of the dataset.
- Increased Accuracy of Results: Quality data leads to more accurate analysis and better insights. Removing outliers and irrelevant information improves the accuracy of predictive models or mining algorithms.
- Enhanced Data Consistency: Preprocessing ensures uniformity in data representation, making comparing and analyzing different datasets easier. Consistent data allows for more reliable patterns and trends to be identified.
- Reduced Overfitting: Dimensionality reduction and feature selection techniques help focus on the most relevant attributes, thereby reducing the risk of overfitting models to noisy or irrelevant data.
- Time and Resource Efficiency: By cleaning and organizing data beforehand, preprocessing reduces the computational burden and time required for subsequent analysis. This efficiency can be critical when dealing with large datasets.
- Compatibility with Algorithms: Many machine learning algorithms have specific data requirements. Preprocessing prepares the data to meet these requirements, ensuring compatibility with various modeling techniques.
- Facilitating Interpretation: Well-preprocessed data is more accessible to interpret and understand. It helps extract meaningful patterns and relationships, aiding in better decision-making processes.
Steps in Data Preprocessing
Here are the fundamental steps involved in data preprocessing:
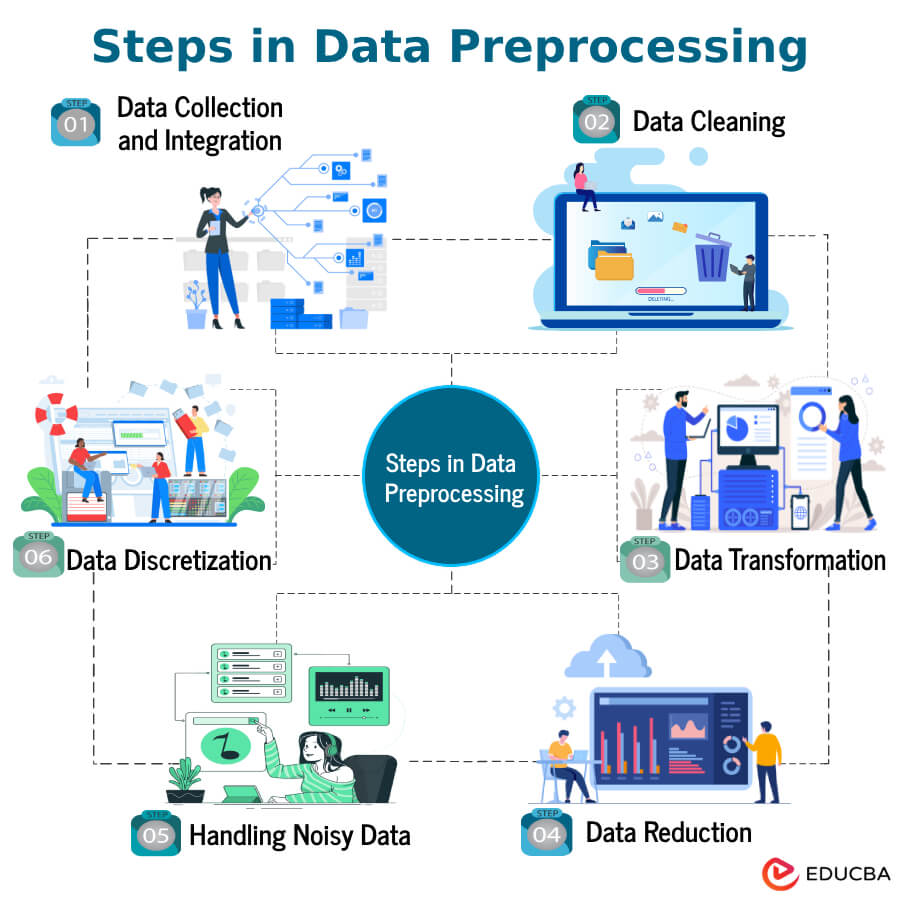
A. Data Collection and Integration
Data Collection Methods
1. Sources of Raw Data:
- Databases: Extracting data from relational databases like MySQL, PostgreSQL, or NoSQL databases like MongoDB.
- Files: Collect data from various file formats, such as CSV, Excel, JSON, XML, or text files.
- APIs (Application Programming Interfaces): Accessing data from web services and APIs that provide structured information.
- Sensors and IoT Devices: Gathering real-time data from sensors and Internet of Things (IoT) devices.
- Surveys and Questionnaires: Obtaining data through surveys and questionnaires to gather specific information from respondents.
- Logs and Event Data: Analyzing logs and event data generated by applications, systems, or network devices.
2. Data Collection Techniques:
- Web Scraping: Extracting data from websites by parsing HTML and XML documents.
- Sampling: Collecting a representative subset of data to reduce processing time and resources.
- Experimentation: Conducting controlled experiments to gather data systematically.
- Observational Studies: Collecting data by observing and recording natural behaviors without intervention.
- Crowdsourcing: Obtaining data from a large group of individuals or contributors, often through online platforms.
- Social Media Mining: Extracting insights from social media platforms by analyzing user-generated content.
Data Integration
1. Combining Multiple Datasets:
- Concatenation: Appending rows or columns of one dataset to another.
- Merge/Join Operations: Combining datasets based on common attributes or keys.
- Union: Combining datasets with similar structures by stacking them vertically.
- Linking: Establishing relationships between records from different datasets to create a cohesive dataset.
2. Addressing Data Inconsistencies:
- Schema Matching: Identifying and aligning the attributes of different datasets to create a unified schema.
- Data Cleaning: Removing duplicates, handling missing values, and addressing other issues to ensure consistency.
- Conflict Resolution: Resolving data values or unit discrepancies to create a harmonized dataset.
- Entity Resolution: Identifying and linking records that refer to the same real-world entity across multiple datasets.
- Data Transformation: Converting data into a standard format or unit to ensure uniformity.
B. Data Cleaning
Handling Missing Data
1. Imputation Techniques:
- Mean/Median Imputation: This involves replacing missing values with the mean or median of the respective variable. This method is helpful for numerical data that follows a normal distribution.
- Mode Imputation: Replaces missing categorical values with the variable’s mode (most frequent value).
- Regression Imputation: Regression models predict missing values by analyzing their relationship with other variables.
- K-Nearest Neighbors (KNN) Imputation: Impute missing values by considering the values of k-nearest neighbors in the dataset.
- Multiple Imputation: Generate multiple imputed datasets to account for uncertainty in imputed values.
2. Removal of Incomplete Records:
- Listwise Deletion: Remove all records (rows) containing any missing values. Simple but may lead to significant data loss.
- Pairwise Deletion: Use available data for specific analyses, allowing for the inclusion of records with missing values in some variables.
- Threshold-based Removal: Remove records with a certain percentage or number of missing values exceeding a predefined threshold.
Outlier Detection and Treatment
1. Identification of Outliers:
- Visual Inspection: Plotting data using box plots, scatter plots, or histograms to identify data points deviating from the norm visually.
- Statistical Methods: Using statistical measures such as z-scores to identify data points outside a certain range.
- Clustering Techniques: Applying clustering algorithms to identify data points that do not conform to the majority cluster.
2. Strategies for Outlier Handling:
- Data Transformation: Apply mathematical transformations (e.g., log transformation) to reduce the impact of outliers.
- Winsorizing: Limit extreme values by replacing them with the maximum or minimum values within a specified range.
- Imputation: Replace outlier values with imputed values based on statistical measures like the mean or median.
- Trimming: Remove a certain percentage of extreme values from both distribution ends.
- Model-Based Handling: Use robust models that are less sensitive to outliers during analysis.
C. Data Transformation
Data Normalization
1. Min-Max Scaling:
- Objective: Rescale numerical features to a specific range, usually [0, 1].
- Formula:
Xnormalized = X-Xmin/Xmax-Xmin
- Benefits: Maintains the relative differences between data points and is suitable for algorithms sensitive to the scale of input features.
2. Z-Score Normalization:
- Objective: Standardize numerical features with a mean of 0 and a standard deviation of 1.
- Formula:
Xnormalized = X – μ / σ
where μ is the mean and σ is the standard deviation
- Benefits: Useful for algorithms that assume a Gaussian distribution and mitigate the impact of outliers.
Data Encoding
1. One-Hot Encoding:
- Objective: Convert categorical variables into binary vectors with 0s and 1s.
- Process: Each category is represented by a binary digit, and only one bit is ‘hot’ (1) to indicate the category.
- Benefits: Prevents ordinal encoding misconceptions and is essential for algorithms that require numerical input.
2. Label Encoding:
- Objective: Convert categorical variables into numerical labels.
- Process: Assign a unique integer to each category.
- Consideration: Suitable for ordinal data but may introduce ordinal relationships that don’t exist in the original data.
Feature Engineering
1. Creation of New Features:
- Objective: Develop new features that enhance the model’s predictive power.
- Examples: Combining existing features, creating interaction terms, or extracting information from date/time variables.
- Benefits: Can uncover hidden patterns and relationships in the data, improving model performance.
2. Dimensionality Reduction Techniques:
- Objective: Reduce the number of features while retaining essential information.
- Methods:
- Principal Component Analysis (PCA): Transform features into new variables that capture most variance and are uncorrelated (principal components).
- T-Distributed Stochastic Neighbor Embedding (t-SNE): Visualize high-dimensional data in two or three dimensions while preserving local similarities.
- Benefits: Reduces computational complexity, avoids overfitting, and can enhance model interpretability.
D. Data Reduction
Techniques for Reducing Data Size
1. Sampling Methods:
- Random Sampling: Selecting a random subset of data points from the entire dataset.
- Stratified Sampling: Dividing the dataset into strata and then randomly sampling from each stratum to ensure representation of different groups.
- Systematic Sampling: Choosing every kth item from the dataset after a random starting point.
- Cluster Sampling: Dividing the dataset into clusters and randomly selecting entire clusters for sampling.
2. Binning and Histogram Analysis:
- Binning: Grouping continuous data into intervals or bins.
- Histogram Analysis: Representing data distribution through a visual representation of bin frequencies.
- Benefits: Reduces the granularity of the data, simplifies patterns, and aids in identifying trends and outliers.
- Consideration: Loss of precision due to grouping data into bins.
Principal Component Analysis (PCA)
1. Dimensionality Reduction with PCA:
- Objective: Transforming high-dimensional data into a lower-dimensional representation while retaining the most important information.
- Process: Identifies principal components in linear combinations of original features that capture the maximum variance.
- Mathematical Concept: Eigenvalue decomposition or singular value decomposition.
- Formula:
Xnew= X*W
where X is the original data matrix, and W contains the eigenvectors.
- Benefits: Reduces multicollinearity, improves computational efficiency, and aids in visualizing data.
2. Application in Data Mining:
- Feature Extraction: Use PCA to extract essential features that contribute the most to the variance in the data.
- Noise Reduction: PCA can help filter out Noise and retain the most critical information, improving model generalization.
- Visualization: Visualize complex, high-dimensional data to identify patterns and clusters in a lower-dimensional space.
- Model Performance: Enhance the performance of data mining models by reducing the dimensionality of the input features.
E. Handling Noisy Data
Identifying and Understanding Noise
1. Identifying Noise:
- Visual Inspection: When examining data plots such as scatter plots or histograms, it is essential to identify data points that deviate significantly from the overall pattern.
- Statistical Analysis: Using measures like standard deviation, mean absolute deviation, or z-scores to detect outliers or erratic values.
- Domain Knowledge: Understanding the context of the data and recognizing inconsistencies or anomalies based on domain expertise.
Techniques for Noise Reduction
1. Smoothing Methods:
- Moving Averages: Replacing each data point with the average of neighboring points within a window.
- Exponential Smoothing: Assigning exponentially decreasing weights to older observations, giving more weight to recent data.
- Median Filtering: Replacing each data point with the median value in its neighborhood, which is more robust to outliers than the mean.
2. Aggregation and Discretization:
- Aggregation: Multiple data points can be combined into a single representation by taking the mean, sum, or max of a group of values.
- Discretization: Converting continuous data into discrete intervals or categories reduces the impact of minor fluctuations.
- Benefits: Reduces granularity and focuses on the broader trends in the data, minimizing the effect of individual noisy points.
F. Data Discretization
Definition: Data discretization is converting continuous data into discrete intervals or categories.
Purpose:
- Simplification: Reducing the complexity of data by converting continuous attributes into a finite set of intervals.
- Handling Ordinal Data: Making data suitable for algorithms that require categorical or ordinal input.
- Reducing Sensitivity to Outliers: Making the data less sensitive to extreme values by grouping them into discrete bins.
Methods of Data Discretization
1. Equal Width Discretization:
- Process: Dividing the range of values into a fixed number of equal-width intervals or bins.
- Formula:
Bin_Width = max-min / Number of Bins
- Advantages: Simple and easy to implement; suitable for uniformly distributed data.
- Challenges: Sensitive to outliers; may result in uneven data distribution in bins.
2. Equal Frequency Discretization:
- Process: One way to group data is to divide it into bins with equal data point numbers.
- Advantages: Reduces the impact of outliers; provides a more balanced distribution.
- Challenges: Complexity increases with unevenly distributed data; may not be suitable for skewed datasets.
- Algorithm: Sort the data, then assign equal-sized portions to each bin.
- Formula:
Bin_Size = Total Data Points / Number of Bins
- Example: For 100 data points and five bins, each bin would ideally contain 20 data points.
Benefits of Data Discretization:
- Improved Interpretability: Simplifying data makes it more interpretable for users and models.
- Handling Nonlinear Relationships: Making data suitable for algorithms assuming linear relationships within intervals.
- Reduced Computational Complexity: Discretization can reduce the computational demands of specific algorithms.
Case Studies
1. Predictive Maintenance in Manufacturing
Problem: A manufacturing plant wants to implement a predictive maintenance system to reduce downtime and increase operational efficiency.
Data Preprocessing Steps:
- Data Collection: Gather sensor data from machinery, including temperature, vibration, and operational hours.
- Data Cleaning: Handle missing values and remove outliers to ensure the accuracy of sensor readings.
- Feature Engineering: Create new features such as rolling averages of sensor readings or cumulative operating hours.
- Data Transformation: Normalize sensor data to a standard scale for consistent analysis.
- Data Reduction: Apply dimensionality reduction techniques like PCA to capture essential features.
- Modeling: Implement machine learning algorithms for predictive maintenance based on preprocessed data.
2. Customer Churn Prediction in Telecom:
Problem: A telecom company wants to predict customer churn to retain customers and reduce attrition proactively.
Data Preprocessing Steps:
- Data Collection: Gather customer data, including usage patterns, customer service interactions, and billing information.
- Data Cleaning: Address missing values, remove duplicate records, and identify outliers in customer data.
- Feature Engineering: Create features like customer tenure, average usage, and frequency of customer service calls.
- Data Transformation: Encode categorical variables and normalize numerical features for modeling.
- Data Reduction: Apply feature selection techniques to identify the most relevant features for churn prediction.
- Modeling: Utilize machine learning models to predict customer churn based on preprocessed data.
3. Fraud Detection in Financial Transactions:
Problem: A financial institution aims to detect fraudulent transactions to enhance security and protect customer accounts.
Data Preprocessing Steps:
- Data Collection: Collect transaction data, including transaction amounts, timestamps, and account details.
- Data Cleaning: Identify and correct missing or inconsistent transaction data and detect abnormal patterns that may suggest errors.
- Feature Engineering: Create features such as transaction frequency, average transaction amount, and account activity trends.
- Data Transformation: Normalize transaction amounts and encode categorical variables for analysis.
- Data Reduction: Apply outlier detection techniques to identify potentially fraudulent transactions.
- Modeling: Implement machine learning models for fraud detection using the preprocessed data.
Future Trends in Data Preprocessing
1. Automated Data Preprocessing
- Prediction and Imputation: Increased use of machine learning algorithms for automated prediction and imputation of missing values.
- Smart Data Cleaning: Integrating artificial intelligence (AI) to automate data cleaning tasks based on learning from historical data.
2. Integration of Explainable AI
- Interpretable Models: There is a growing emphasis on using interpretable models during preprocessing to enhance the transparency and interpretability of data-driven models.
- Model-agnostic Explainability: Integration of model-agnostic explainability techniques to provide insights into feature importance and model decisions.
3. Privacy-Preserving Preprocessing
- Differential Privacy: Implement differential privacy techniques to ensure data preprocessing methods do not compromise individual privacy.
- Secure Multiparty Computation: Techniques allowing data preprocessing across multiple parties without sharing sensitive information.
4. Streaming Data Preprocessing
- Real-time Processing: Development of preprocessing techniques tailored for streaming data to enable real-time analysis.
- Adaptive Methods: Implementation of adaptive preprocessing methods that adjust to changing data distributions in real-time.
5. Preprocessing for Federated Learning
- Distributed Data Processing: Adoption of preprocessing methods suitable for federated learning environments where data is distributed across multiple devices or servers.
- Privacy-Preserving Techniques: Integration of preprocessing steps that maintain privacy and security in federated learning setups.
6. Preprocessing for Edge Computing
- Edge Device Optimization: Development of preprocessing techniques optimized for edge devices with limited computational resources.
- Decentralized Processing: Techniques that allow data preprocessing to be performed closer to the data source, reducing the need for extensive data transfers.
Conclusion
Ensuring data quality and suitability for analysis, data preprocessing remains a crucial step in the data mining pipeline. As technology advances, trends in automated preprocessing, privacy preservation, and dynamic adaptation will shape future practices. The field continues progressing, emphasizing transparency and interpretability, leading to more efficient and effective data-driven insights.
Recommended Articles
We hope this EDUCBA information on “Data Preprocessing in Data Mining” benefits you. You can view EEDUCBA’s recommended articles for more information.

