Updated December 7, 2023
Introduction of Data Reduction in Data Mining
Data reduction is a fundamental concept in data mining that aims to reduce the size and complexity of datasets while retaining important information. It involves techniques like dimensionality reduction and feature selection to eliminate redundant or irrelevant data. By consolidating data size, organizations can improve analysis speed, optimize storage requirements, and extract meaningful insights more effectively.
Table of Content
- Introduction
- Need for Data Reduction
- Different Data Reduction Techniques
- Illustrative Examples of Data Reduction Techniques
- Methods of Data Reduction in Data Mining
- Advantages of Data Reduction in Data Mining
- Disadvantages of Data Reduction in Data Mining
- Examples of Data Reduction in Data Mining
- Challenges and Considerations
- Future Trends and Innovations
Key Takeaways
- Data reduction minimizes the size of a dataset while preserving its essential information.
- Data reduction techniques enhance data processing efficiency, reduce noise, improve data visualization, and manage memory effectively.
- Data reduction techniques include dimensionality reduction, numerosity reduction, and data compression.
- Data reduction objectives encompass data cleaning, feature selection, transformation, aggregation, and generalization.
- Data reduction plays a crucial role in data mining by enabling efficient analysis of large and complex datasets for valuable insights.
Need for Data Reduction
- Improved Efficiency: Data reduction techniques help reduce the dataset’s size, making data mining algorithms faster and more efficient in processing and analysis.
- Enhanced Accuracy: Data reduction improves the dataset’s quality by removing superfluous or irrelevant information, producing more accurate and trustworthy data mining results.
- Storage Optimization: Data reduction techniques reduce the storage requirements by eliminating unnecessary data, which is especially beneficial when dealing with large datasets.
- Overcoming Curse of Dimensionality: Dimensionality reduction techniques address the curse of dimensionality by reducing the number of variables or features, making the data mining process more manageable and effective.
- Noise Reduction: By eliminating noisy or irrelevant data, data reduction techniques help to improve the signal-to-noise ratio, focusing on the important patterns and relationships within the dataset.
- Improved Interpretability: Data reduction simplifies the dataset, making it easier to interpret and understand the underlying patterns and insights, facilitating decision-making processes in data mining.
Different Data Reduction Techniques
Here are some common data reduction techniques:
A. Dimensionality Reduction
Reducing the number of features or variables in a dataset is a crucial step in the data analysis and machine learning process known as “dimensionality reduction. The goal is to simplify the dataset while retaining as much relevant information as possible. High-dimensional datasets with many features can suffer from the curse of dimensionality, leading to increased computational complexity, potential overfitting, and difficulties in visualization and interpretation.
1. Wavelet Transform
Overview: The wavelet transform decomposes a signal into different frequency components. It can truncate data by keeping the most significant wavelet coefficients in dimensionality reduction.
Application: Particularly effective for handling data with varying frequencies or resolutions, such as in signal processing and image compression.
2. Principal Component Analysis (PCA)
Overview: PCA is a linear transformation method that identifies the principal components of linear combinations of the original features. These components capture the largest variance in the data.
Application: Used for feature extraction and data compression. It is effective when dealing with correlated features.
3. Attribute Subset Selection
Definition: Attribute subset selection involves choosing a relevant subset of attributes from a more extensive set in a dataset. The aim is to eliminate irrelevant or redundant attributes, thereby reducing data volume and improving analysis efficiency. This process ensures that the selected subset retains essential information while discarding unnecessary details.
Overview: Attribute subset selection methods include step-wise forward selection, step-wise backward selection, and combinations of both. These methods iteratively evaluate the importance of each attribute based on statistical measures or other criteria. The final reduced attribute set enhances interpretability and computational efficiency, making it easier to perform data mining tasks and build more effective models.
Methods
1. Step-wise Forward Selection
Consider a hypothetical dataset with the following attributes: {Age, Income, Education, Work Experience, Communication Skills, Performance Score}. We want to use step-wise forward selection to identify a subset of attributes most relevant to predicting job performance.
Initial attribute Set: {Age, Income, Education, Work Experience, Communication Skills, Performance Score}
Initial reduced attribute set: {}
Now, let’s go through the steps:
Step 1: {Age}
- Evaluate the statistical significance or other relevant criteria.
- Suppose Age is found to be the most significant attribute.
Step 2: {Age, Work Experience}
- Add Work Experience as it complements Age in predicting job performance.
Step 3: {Age, Work Experience, Communication Skills}
- Include communication skills, as they provide additional valuable information.
Final reduced attribute set: {Age, Work Experience, Communication Skills}
In this example, the step-wise forward selection process identified the subset {Age, Work Experience, Communication Skills} as the final reduced attribute set. We chose these attributes based on their individual and collective significance in predicting job performance. The outcome is a more focused set of features suitable for analysis, enhancing efficiency and interpretability.
2. Step-wise Backward Selection
Let’s use the same hypothetical dataset with attributes {Age, Income, Education, Work Experience, Communication Skills, Performance Score} to illustrate step-wise backward selection for predicting job performance.
Initial attribute Set: {Age, Income, Education, Work Experience, Communication Skills, Performance Score}
Initial reduced attribute set: {Age, Income, Education, Work Experience, Communication Skills, Performance Score}
Now, let’s go through the steps:
Step 1: {Age, Income, Education, Work Experience, Communication Skills}
- Evaluate the least significant attribute, perhaps Income.
- Remove Income, resulting in {Age, Education, Work Experience, Communication Skills, Performance Score}.
Step 2: {Age, Education, Work Experience, Communication Skills}
- Continue removing the least significant attribute, Education.
- Remove Education, resulting in {Age, Work Experience, Communication Skills, Performance Score}.
Step 3: {Age, Work Experience, Communication Skills}
- Continue until the desired reduced attribute set is reached, considering the statistical significance or other relevant criteria.
Final reduced attribute set: {Age, Work Experience, Communication Skills}
In this example, the step-wise backward selection process identified the subset {Age, Work Experience, Communication Skills} as the final reduced attribute set. The algorithm iteratively removed the least significant attributes, streamlining the feature set for predicting job performance.
B. Numerosity Reduction
Numerosity reduction techniques reduce the number of records or instances in a dataset. This can be useful when the dataset is vast and processing some data is only feasible.
Two primary approaches to numerosity reduction include parametric and non-parametric methods.
Parametric numerosity reduction is a technique that involves storing only the essential parameters of data instead of the entire original dataset. One approach within this method is using regression and log-linear methods.
Regression, particularly linear regression, works by creating a model representing the relationship between two attributes through a linear equation. In this equation (y = wx + b), ‘y’ represents the outcome attribute, ‘x’ signifies the predictor attribute, while ‘w’ and ‘b’ are the coefficients of the regression. When we apply this concept to data mining, ‘x’ and ‘y’ are the numerical attributes within the database.
Multiple linear regression extends the idea of modeling the response variable by considering linear relationships among two or more predictor variables.
On the other hand, researchers use the log-linear model to reveal relationships between discrete attributes in a database. Imagine a collection of tuples represented in n-dimensional space; the log-linear model is utilized to analyze the likelihood of each tuple occurring within this multidimensional context.
Non-parametric: Non-parametric numerosity reduction techniques don’t rely on specific models. Instead, they aim to reduce data more broadly without assuming a particular structure within the data. While they offer a uniform reduction across various data sizes, parametric techniques might achieve a lower reduction rate than they do. Some standard non-parametric techniques include histograms, clustering methods, sampling, data cube aggregation, and data compression. These methods work without making strict assumptions about the underlying data distribution or parameters.
Histogram: A histogram is like a graph showing how often different values appear in your data. It organizes these values into groups called bins or buckets using a method called binning. This graph helps you see if your data is closely packed, spread out, evenly spread, or lopsided in one direction. It’s not just for one thing either – you can use a histogram to show this for more than one characteristic at a time. Typically, it does an excellent job of looking at up to five different traits simultaneously.
Clustering: Clustering techniques group similar things in your data so that items in one group are alike but different. They use a “distance” idea to measure how much things resemble each other within a cluster. The more alike they are, the closer they stick together in that group. The “quality” of a cluster depends on how far apart the things within it are – the more significant the gap between the farthest items, the wider the cluster.
When we talk about representing data with clusters, it means that instead of showing each original piece of data, we offer these groups of similar things. This method works best when your data naturally falls into clear, separate groups.
Sampling: Sampling is a technique to make big datasets smaller. There are various ways to do this:
Simple random sample without replacement (SRSWOR) of size s: You pick several tuples (s) from a dataset (D) with N tuples, making sure s is more minor than N. Each tuple has an equal chance of being picked, and once it’s decided, it’s not put back in the dataset.
Simple random sample with replacement (SRSWR) of size s: Similar to SRSWOR, but after picking a tuple, it’s put back in the dataset to be selected again.
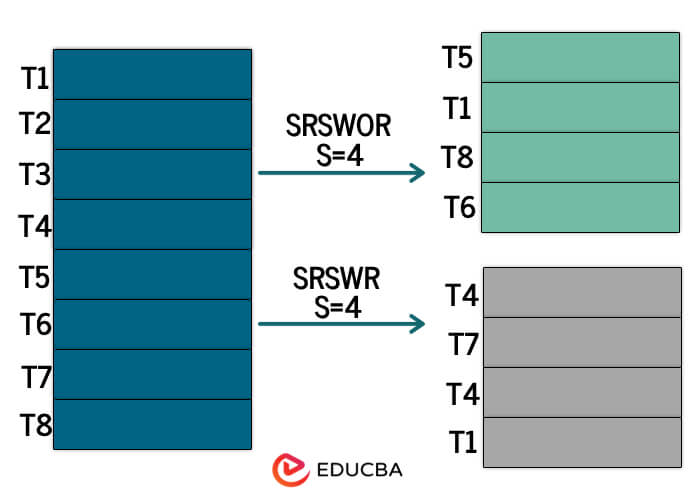
Cluster sample: Here, you group the tuples in D into different sets. Then, you apply SRSWOR to these groups to create a smaller sample.
Stratified sample: In this method, the large dataset is divided into separate groups called ‘strata.’ A random sampling is taken. This method works well for data that are not evenly distributed.
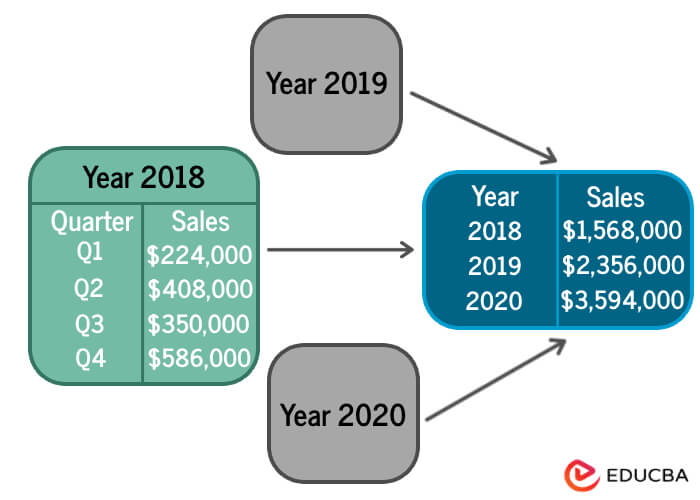
C. Data Cube Aggregation
Data cube aggregation is a data mining technique that involves summarizing and aggregating data along multiple dimensions to create a concise and informative data representation. It is commonly used in online analytical processing (OLAP) and data warehousing applications to provide quick and efficient access to multidimensional data.
For example, When you have sales data spanning multiple years, like All Electronics sales from 2018 to 2022, to find the yearly sales, you can group the sales recorded in each quarter for every year together. This grouping or aggregation helps condense the information, making it more manageable without losing important data. By doing this, you’re summarizing the quarterly sales into annual figures, which reduces the overall size of the data while retaining all the necessary details about yearly.
D. Data Compression
Data compression techniques reduce the size of the data files without losing any information. This can be useful when the dataset is huge and expensive to store or transmit. Standard data compression techniques include:
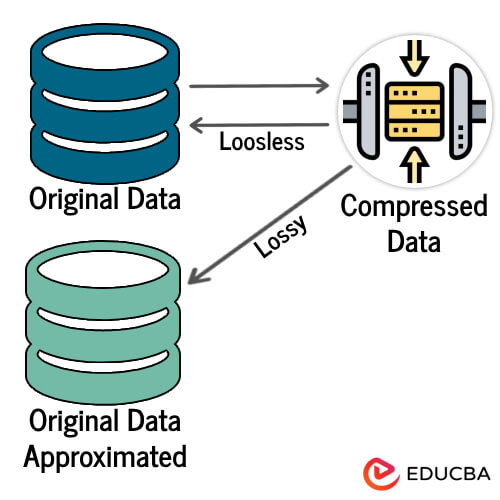
- Lossless compression: Lossless compression algorithms reduce the size of the data files without losing any information. This is typically done by using statistical techniques to identify patterns in the data.
- Lossy compression: Lossy compression algorithms reduce the size of the data files by discarding some of the information. This is typically done using perceptual techniques to identify information that is not noticeable to the human eye or ear.
E. Discretization Operation
Discretization is like organizing continuous data into groups or intervals, making it easier to understand and analyze. It’s like sorting a deck of cards into different piles based on their numbers.
- Top-down discretization: You start by picking one or a few points where you want to divide the data into intervals. Imagine you’re sorting a deck of cards by focusing on specific cards and creating different piles based on those cards’ values. Then, you keep doing this, creating smaller and smaller groups until you’ve organized all the cards into piles that make sense.
- Bottom-up discretization: You start by considering every value as a potential point to split the data into intervals. Then, you gradually combine nearby values into intervals, discarding some initial split points to create more meaningful groups. It’s like starting with each card as a separate pile and then merging nearby piles until you end up with a more manageable set of piles with similar values.
Illustrative Examples of Data Reduction Techniques
Example #1
Scenario: Marketing Campaign Data Analysis
Imagine a marketing analyst, Sarah, is tasked with analyzing the effectiveness of a recent email marketing campaign. The dataset includes information about thousands of email interactions, such as open rates, click-through rates, and conversion rates.
Data Reduction Technique: Clustering
Sarah decided to apply clustering to group similar email interactions based on customer behavior. By doing this, she reduces the dataset’s complexity while preserving the essential patterns.
Result:
- Instead of analyzing individual email interactions, Sarah now has clusters representing different customer responses (e.g., highly engaged, moderately engaged, less engaged).
- As a result, the marketing team may create more focused and successful marketing strategies by basing upcoming ads on the traits of each cluster.
Example #2
Scenario: Customer Feedback Analysis
Alex’s customer service manager receives a large dataset containing customer feedback from various channels, including online reviews and support tickets. The dataset has multiple attributes, such as customer ID, sentiment scores, and specific comments.
Data Reduction Technique: Feature Engineering
Alex creates a new “Overall Satisfaction” feature by combining sentiment scores from different channels. This reduces the dataset’s dimensionality while capturing each customer’s overall sentiment.
Result:
- The dataset now includes a simplified feature set with crucial information, such as customer ID, Overall Satisfaction, and specific comments.
- This condensed representation enables Alex to quickly assess the overall sentiment trends and focus on addressing specific issues mentioned by customers, improving the efficiency of customer service.
Example #3
Scenario: Summarizing Annual Returns for Management Analysis
Imagine that an accountant, Emily, is tasked with analyzing a company’s annual returns for presentation to the management team. The dataset contains information about the returns of different business units, investment portfolios, or products.
- Data: The annual returns dataset includes numerical values representing the returns for each business unit, portfolio, or product. It is a large dataset with potentially thousands of data points.
- Objective: The goal is to present a concise and easily understandable analysis of the annual returns to the management team, highlighting key performance trends.
- Binning Technique: Emily used the binning technique to categorize the annual returns into distinct groups. She creates three categories:
- Lowest Returns: This category includes business units, portfolios, or products with the lowest annual returns.
- Median Returns: The middle category represents entities with moderate or median annual returns.
- Highest Returns: This category includes those with the highest annual returns.
- Process:
- Data Preparation: Emily collects and organizes the annual returns data.
- Binning: She determines the thresholds for each category based on the distribution of annual returns. For example, the lowest 30% of returns could fall into the “Lowest Returns” category, the next 40% into the “Median Returns” category, and the top 30% into the “Highest Returns” category.
- Categorization: Emily assigns each business unit, portfolio, or product to one of the three categories based on its annual return.
- Summarization: Emily calculates summary statistics for each category, such as average or median returns. She may also create visualizations, such as bar charts or pie charts, to represent the distribution of returns across the categories.
- Result: The final output is a summarized analysis that provides management with a clear overview of the annual returns. By categorizing returns into “Lowest,” “Median,” and “Highest,” the management team can quickly understand the performance distribution and identify areas that may require attention or further investigation.
Methods of Data Reduction in Data Mining
In data mining, data reduction techniques are used to reduce the complexity and size of the dataset while retaining the essential information. Here are some commonly used methods of data reduction in data mining:
- Attribute Selection: This involves selecting a subset of the dataset’s relevant attributes (columns). It aims to eliminate redundant or irrelevant attributes that may not contribute significantly to the mining task. Techniques like information gain, correlation analysis, and feature importance can assist in attribute selection.
- Numerosity Reduction: This method reduces the dataset’s number of instances (rows). It includes techniques like sampling, where a representative subset of cases is selected, or instance-based pruning, where outliers or noisy instances are removed.
- Dimensionality Reduction: This technique aims to decrease the number of dimensions or variables in the dataset while preserving its essential information. Techniques such as Principal Component Analysis (PCA), Linear Discriminant Analysis (LDA), and t-SNE (t-distributed Stochastic Neighbor Embedding) can transform the dataset into a lower-dimensional space.
- Discretization: This process involves converting continuous variables into discrete ones by creating intervals or ranges. Discretization simplifies the data and can be particularly useful for specific algorithms with categorical or discrete data.
- Data Cube Aggregation: This method involves aggregating data at different levels of granularity, such as summarizing data at higher levels (e.g., months instead of days) to reduce the dataset’s size. This is often used in OLAP (Online Analytical Processing) and multidimensional data analysis.
- Sampling: Sampling techniques randomly select a subset of the dataset for analysis. Simple random, stratified, or systematic sampling can reduce the dataset’s size while maintaining statistical properties.
- Data Compression: Data compression algorithms reduce the size of the dataset by removing redundancy or applying encoding techniques. Employing compression methods such as ZIP compression, run-length encoding, or Huffman coding can reduce storage space.
Advantages of Data Reduction in Data Mining
- Improved Efficiency: Data reduction techniques reduce the size and complexity of datasets, leading to faster processing and analysis by data mining algorithms.
- Enhanced Accuracy: By eliminating irrelevant or redundant data, data reduction improves the quality of datasets, resulting in more accurate and reliable results in data mining.
- Storage Optimization: Data reduction reduces the storage requirements by eliminating unnecessary data, which is particularly beneficial when dealing with large datasets, saving storage space and costs.
- Overcoming Curse of Dimensionality: Dimensionality reduction techniques address the curse of dimensionality by reducing the number of variables or features, making the data mining process more manageable and effective.
- Noise Reduction: Data reduction techniques eliminate noisy or irrelevant data, improving the signal-to-noise ratio and enabling the focus on essential patterns and relationships within the dataset.
Disadvantages of Data Reduction in Data Mining
- Information Loss: Some data reduction techniques may result in the loss of specific information or details from the original dataset, which may impact the accuracy or completeness of the analysis.
- Complexity of Techniques: Implementing data reduction techniques can be complex and requires expertise in selecting appropriate methods and parameters for specific datasets and analysis goals.
- Subjectivity: The selection of features or data points to be reduced may involve subjective decisions, which could introduce biases or limitations in the data mining process.
- Trade-offs: Balancing data size reduction and potentially losing important information requires making trade-offs. Finding the ideal equilibrium is essential to ensure the retention of significant ideas.
Examples of Data Reduction in Data Mining
- Image Processing: Data reduction techniques can be utilized in image data to minimize image dimensionality while maintaining pertinent information; methods like image compression (such as JPEG or PNG) can reduce the storage space required for images without significant loss of visual quality. Additionally, feature extraction techniques, like edge detection or image segmentation, can reduce the complexity of image data by extracting essential features for analysis or classification.
- Speech Recognition: In audio or speech datasets, data reduction can be achieved through speech recognition. This involves converting speech signals to text, thereby reducing the dimensionality of the data and enabling subsequent analysis of the textual representation. This conversion allows for applying various NLP techniques, such as text mining or sentiment analysis, on the transcribed speech data.
- Natural Language Processing (NLP): NLP techniques can play a crucial role in data reduction for textual data. Text mining approaches, such as term frequency-inverse document frequency (TF-IDF) or word embeddings, can reduce text documents’ dimensionality while preserving crucial semantic information. NLP techniques also aid in topic modeling, summarization, or sentiment analysis, which helps summarize and reduce large amounts of text data into more manageable forms.
Challenges and Considerations
Indeed, here are some challenges and considerations associated with data reduction in data mining:
Challenges
- Information Loss: Aggressive reduction may result in losing critical details or patterns in the original dataset.
- Algorithm Compatibility: Reduced data might only suit some algorithms, potentially impacting the effectiveness of specific analytical methods.
- Bias and Sampling Errors: Sampling techniques could introduce biases or errors, affecting the representativeness of the reduced dataset.
- Difficulty in Validation: Reduced data might be more complex to validate, as it may not fully represent the diversity of the original dataset.
Considerations
- Balance Reduction and Preservation: Finding a balance between reducing data volume and retaining critical information is crucial for effective data reduction.
- Impact on Analysis: Understanding how different reduction techniques affect the outcome of analyses and models is essential for reliable results.
- Quality Assessment: Ensuring the reduced dataset maintains the original data’s quality, integrity, and relevance.
- Application Specificity: Tailoring data reduction methods to suit the specific requirements of the application or analysis being conducted.
- Ethical Implications: Considering ethical aspects regarding information loss or bias that might affect decision-making based on reduced datasets.
Future Trends and Innovations
Data reduction techniques in data mining will likely continue evolving, driven by technological advancements and new data challenges. Here are some potential trends and innovations to consider:
- Big Data Handling: As the volume, velocity, and variety of data continue to increase, data reduction techniques will need to adapt to handle big data efficiently. Innovations may include scalable algorithms, distributed computing frameworks, and parallel processing techniques to effectively process and reduce large-scale datasets.
- Streaming data reduction: As real-time data streams from various sources continue to proliferate, data reduction techniques need adaptation for handling streaming data. This involves developing algorithms that dynamically reduce and summarize data in real-time while preserving relevant patterns and relationships.
- Profound learning-based reduction: Deep learning models like autoencoders can learn complex data representations. Applying deep learning techniques for data reduction can help capture intricate patterns and relationships, enabling more effective reduction while preserving essential information.
- Privacy-preserving reduction: Privacy concerns are becoming increasingly important in data mining. Future data reduction techniques will likely incorporate privacy-preserving methods, such as differential privacy or secure multi-party computation, to reduce data while protecting sensitive information.
- Incremental data reduction: Instead of reducing the entire dataset simultaneously, total data reduction techniques will become more prevalent. These techniques update the reduced dataset incrementally as new data arrives, ensuring that the reduction stays current and relevant over time.
Conclusion
In data mining, data reduction strategies seek to minimize dataset size and complexity while maintaining essential patterns and relationships. It involves carefully considering information loss, scalability, biases, and domain knowledge. Future trends include extensive data handling, streaming data reduction, and profound learning-based reduction.
FAQ’s
Q1. Can data reduction techniques be applied to any dataset?
Answer: Many datasets can benefit from data reduction techniques; however, selecting these strategies is contingent upon the particular features and needs of the data. Different methods might work better depending on the kind of data streaming, unstructured or structured.
Q2. How can data reduction techniques affect data privacy?
Answer: Data reduction techniques can have implications for data privacy. Care must be taken to ensure that sensitive information is not compromised during the reduction process. Methods such as anonymization, encryption, and privacy-preserving algorithms can be employed to protect privacy while reducing data.
Q3. What are the challenges of data reduction in data mining?
Answer: Data reduction challenges in data mining include the risk of information loss, selection bias, scalability issues with large datasets, ensuring the reduction quality, handling data with skewed distributions, considering domain knowledge, and evaluating the effectiveness of reduction techniques.
Q4. How does data reduction impact data mining results?
Answer: Data reduction impacts data mining results by reducing computational requirements, improving efficiency, and allowing for more straightforward analysis. It helps to eliminate noise, irrelevant data, and redundancy, enabling more accurate modeling or research of the remaining dataset and resulting in better insights and decision-making.
Recommended Articles
We hope that this EDUCBA information on “Data Reduction in Data Mining” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

