Updated June 19, 2023
Differences Between Data Warehouse vs Hadoop
In Data Warehouse, Data is arranged in an orderly format under a specific schema structure, whereas Hadoop can hold data with or without standard formatting. This makes Hadoop data to be more varied and more consistent compared to a Data Warehouse. Although a Hadoop system can hold scrap data, it facilitates business professionals to store all kinds of data, which is impossible with a Data warehouse, as its clean organization is its key feature. However, for effective decision-making, both Hadoop and Data Warehouse play influential roles in the organizations.
What is Hadoop?
Who hasn’t heard of Big Data lately? With hundreds of terabytes of data generated daily from different sources, it is clear that today’s modern world is big data.
When you start talking about Big Data, you will soon begin discussing the hottest topic of the Big data world: Hadoop – but what exactly is it?
Hadoop is an open-source, Java-based programming framework that supports the processing and storing of extremely large data sets in a distributed computing environment.
The 4 Modules of Hadoop –
Hadoop is made up of 4 modules –
- Distributed File-System
Distributed File System allows data to be stored in an easily accessible format across many linked storage devices.
- Map Reduce
Map Reduce combines two operations – reading data from the database and putting it into a format suitable for analysis (map) and performing mathematical operations (reduce).
- Hadoop Common
Hadoop Common provides the tools needed for the data stored in HDFS (Hadoop Distributed File System)
- YARN
YARN manages the resources of the systems storing the data and running the analysis.
What is a Data Warehouse?
A data warehouse is a relational database designed for query and data analysis. It usually contains historical data derived from different sources.
The data warehouse environment includes:
- ETL solutions.
- An online analytical processing (OLAP) engine.
- Client analysis tools.
- Other applications that manage to analyze data and deliver it to business users.
Let’s summarize what a data warehouse is –
Subject-oriented
A data warehouse can analyze subjects like sales, finance, and inventory. Each subject area contains detailed data.
Integrated
A data warehouse integrates data from multiple data sources. For example, dates are in the same format, and male/female codes are consistent. In a data warehouse, there will be only a single way of identifying a product, and they use the same customer record, not copies.
Non-volatile
Data is stored in the data warehouse unmodified and will not change. So, historical data in a data warehouse should always remain the same.
Time-variant
One can retrieve data from 3 months, 6 months, 12 months, or even older data from a data warehouse.
Not virtual
The data warehouse is a physical, persistent repository.
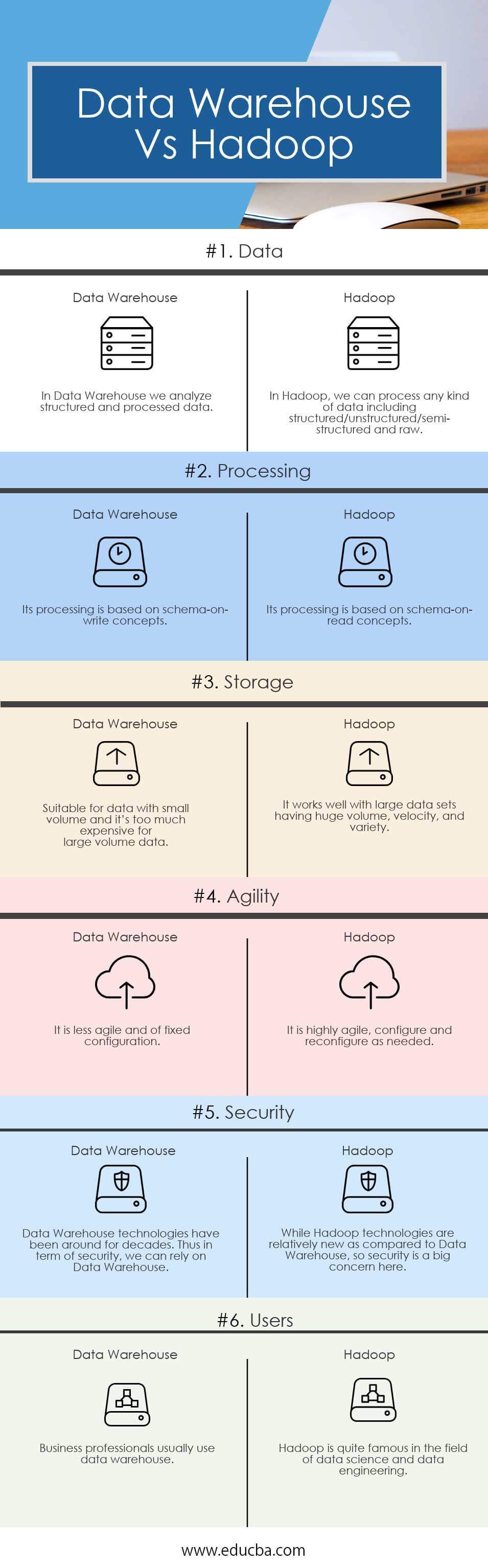
Head to Head Comparison Between Data Warehouse and Hadoop (Infographics)
Below are the Top 6 Comparisons between Data Warehouse and Hadoop:
Data Warehouse vs Hadoop –Which One to Use?
- If you have clean, consistent, and high-quality data, then you should go for Data Warehouse because Hadoop lacks data quality in some of its solutions.
- If you have Raw, Unstructured Data, then you should go for Hadoop because Hadoop works well with unstructured/raw data, but Data Warehouse works only with structured data.
- For Low Latency and Interactive Reports, you should go for Data Warehouse.
- For OLTP/Real-time/ Point Queries, you should go for Data Warehouse because Hadoop works well with batch data.
- For large-volume data sets, you should go for Hadoop because Hadoop is designed to solve Big data problems.
Data Warehouse vs Hadoop Comparison Table
Below is the list of points describing the Comparisons Between Data Warehouse and Hadoop.
| Basis For Comparison | Data Warehouse | Hadoop |
| Data | In Data Warehouse we analyze structured and processed data | In Hadoop, we can process any kind of data, including structured/unstructured/semi-structured and raw |
| Processing | Its processing is based on schema-on-write concepts | Its processing is based on schema-on-read concepts |
| Storage | Suitable for data with small volumes and it’s too much expensive for large-volume data | It works well with large data sets having huge volumes, velocity, and a variety |
| Agility | It is less agile and of fixed configuration | It is highly agile, configure and reconfigures as needed |
| Security | Data Warehouse technologies have been around for decades. Thus in terms of security, we can rely on Data Warehouse. | While Hadoop technologies are relatively new as compared to Data Warehouse, so security is a big concern here. |
| Users | Business professionals usually use a data warehouse | Hadoop is quite famous in the field of data science and data engineering |
Conclusion
Now we know about Data Warehouse and Hadoop both, let’s go back and examine the question that we asked at the start of this Data Warehouse and Hadoop article –
1) if you have big data, do you need a Data warehouse?
Answer – as long as your organization needs reliable, believable, and accessible data, then you need a data warehouse.
2) Will Hadoop Replace the Data Warehouse?
Answer – Comparing Data Warehouse vs Hadoop is like comparing apples and oranges. Both Data Warehouse and Hadoop have their own benefits in different use case scenarios. In some cases, we are still dependent on traditional Data Warehouse techniques, but as time changes, we are more focused on Hadoop Framework to handle Big Data problems.
3) Is this a death of the traditional Data Warehouse era?
Answer – As you can see, this is not really a simple question and therefore does not lend itself well to a simple answer. It’s true that big data is going to change the traditional data warehousing approach in the coming next few years. Still, it will not obsolete the concepts and practice of data warehousing.
Recommended Articles
We hope that this EDUCBA information on “ReactJs Interview Questions” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
