Updated March 16, 2023

Introduction to Databricks Delta Lake
Databricks Delta Lake is an open-source storage layer that delivers security. It brings reliability to databricks data lakes and the performance of the user’s data lake, considering batch and stream operations. Delta lake enables building lake house architecture on top of the data lake. It adds optimized layouts and indexes to Databricks delta lake for fast, interactive queries.
Key Takeaways
The below points give an overview of Databricks Delta Lake, its key points, and its uses:
- Databricks Delta Lake helps cater to some of the main points that Big Data ETL tools like Spark, Hive, etc., cannot resolve.
- Delta lake also offers DML support, i.e., to update and insert in single steps using Merge and Delete the bad records.
- It offers Data versioning that enables data rollbacks, audit changes, and reproduction of reports.
- It has unified streaming and batch sink that enables ingestion of high-volume data into query tables directly.
- Delta lake uses optimize and z-order for query performance along with Schema evolution, enabling users to make changes to table schema that are automatically applied without any need for DDL statements.
- Delta lake uses Delta format to store data, and while porting delta data to Spark platforms, delta format needs replacement by Parquet format.
What is Databricks Delta Lake?
Databricks delta lake provides ACID (Atomic, Consistency, Isolation, Durability) transactions with scalable metadata handling. Delta lake runs on top of the existing data lake and is compatible with Apache API Spark; delta lake is also cost-effective as users can replace data silos with unstructured, semi-structured, and structured data. It automatically handles schema variations to prevent nasty record insertion during ingestion. It also enables rollbacks, historical audit trails, and reproducible machine learning experiments.
Delta Engine optimizations help Delta lake operations to be highly performant by supporting various workloads ranging from large-scale ETL processing to ad-hoc interactive queries.
How to Use Databricks Delta Lake Workspace?
Delta Lake Workspace requires access to Azure Databricks Workspace that helps perform structured streaming by using Delta Lake for batch jobs.
Step 1: A prerequisite to working with Delta Lake Workspace is to have an active Azure Account. Click on https://portal.azure.com/ to Sign Up/ Sign in (if existing user).
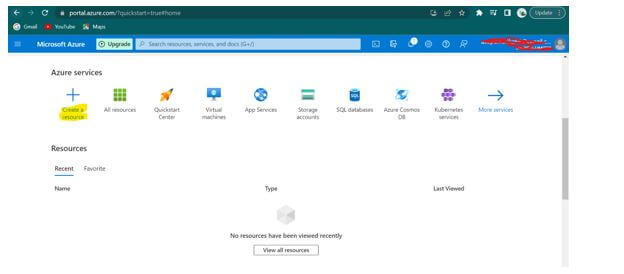
Step 2: Once signed in, click on + Create a Resource as shown below.
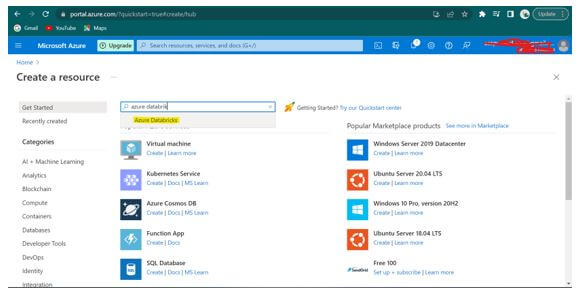
Step 3: In the screen below, search for “Azure Databricks” in the Marketplace Text Box and select.
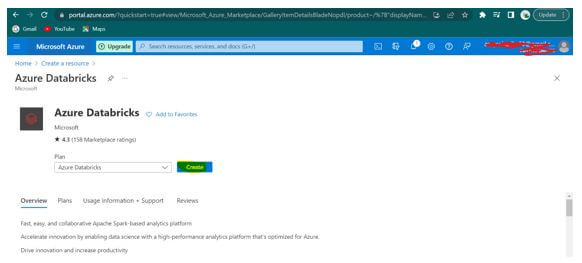
Step 4: Here in Azure Databricks, click “Create,” as shown below.
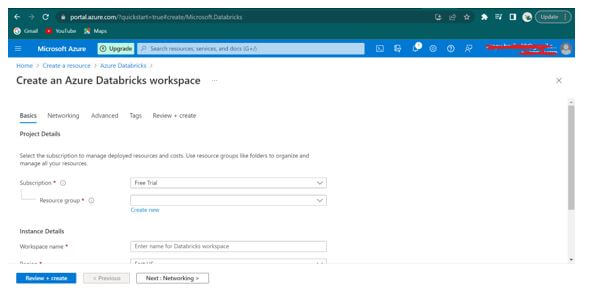
Step 5: In the above Azure Databricks Service blade form, fill the below details.
- Name of the workspace: awdbwsstudxx here, “xx” represent user initials.
Subscription: Select the subscription which the user uses in the Azure lab. - Resource Group Name: awrgstudxx; here, “xx” represents user initials.
- Location: East US.
- Pricing Tier: Trial (Premium – 14-Days free DBUs) (as shown in Azure Portal).
Select Review and Create.
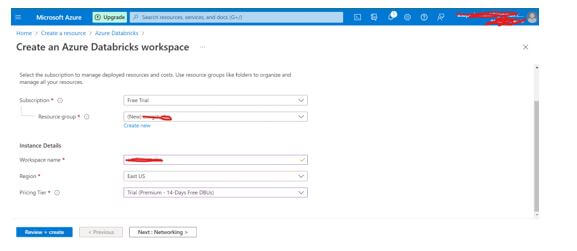
Step 6: Once you click on Review+Create, given details are Validated, and Azure Databricks Workspace is created.
Step 7: Click on “Create,” and the deployment starts.
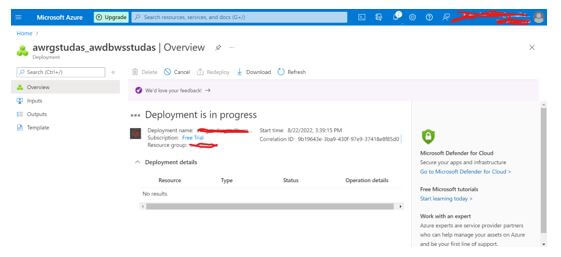
Step 8: Select “go to the resource” once the deployment is completed.
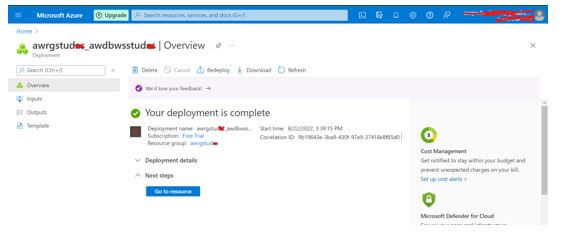
Step 9: Now, select Launch Workspace or Go to Resource, and open Databricks workspace in a new tab.
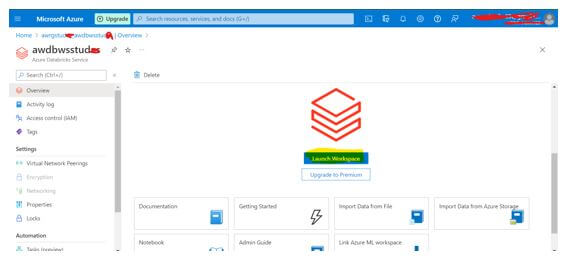
Step 10: In the left menu of Databricks Workspace, select Create Cluster.
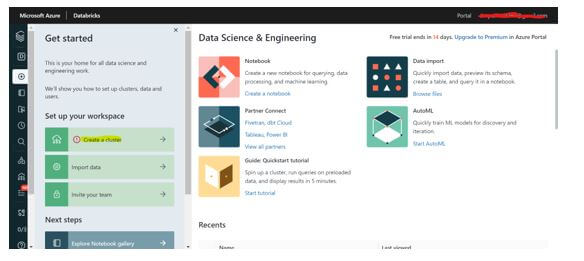
Step 11: Fill in the details as shown below; depending on the requirement, the user can select Single Node or Multi Node with the required Node Type and click on Create Cluster.
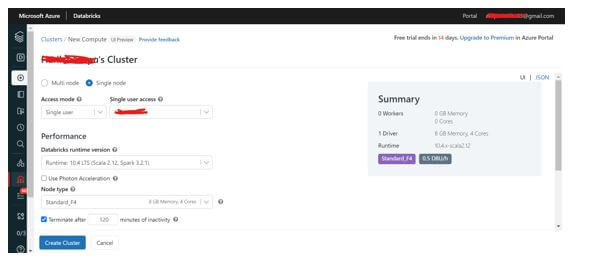
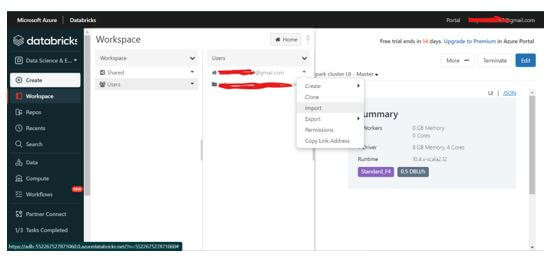
Step 12: Once the cluster is created, the user can perform Stream and Batch processing. Click on Workspaces – Users, select the required username, and click on Import.
Step 13: In the Import dialog box, paste the below URL(sample)
https://github.com/solliancenet/microsoft-learning-paths-databricks-notebooks/blob/master/data-engineering/DBC/11-Delta-Lake-Architecture.dbc?raw=true
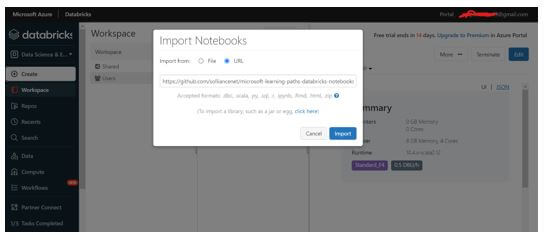
Open 11-Delta-Architecture Open 1-Delta-Architecture.
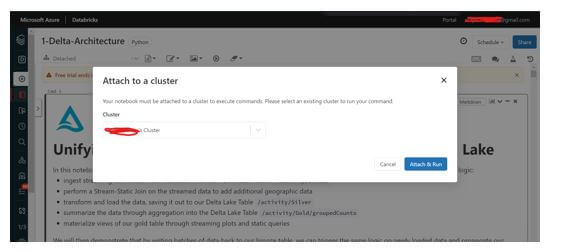
Step 14: Run all the Cells or Run each cell as shown below screenshot, and the output gets generated.
Databricks Delta Lake Architecture Diagram or Delta Lake Model
Let us see through the Delta Lake Architecture:
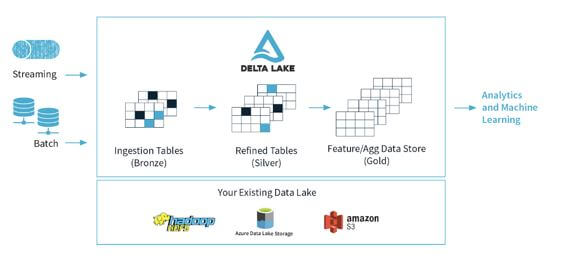
Delta lake Architecture is an improvement upon Lambda Architecture. At each stage shown above, the user can improve data through a connected pipeline which allows the user to combine batch and streaming workflows via a shared file store and ACID transactions.
As shown above, data in Delta lake is organized into folders or layers, i.e., Bronze, Silver, and Gold.
- Bronze: These tables have raw data ingested from sources such as JSON files, RDBMS data, IoT data, etc).
- Silver: These tables have a refined view of user data and can join fields from various bronze tables to update account status or improve streaming records.
- Gold: These tables provide business-level aggregates used for reporting and dashboarding. It includes weekly sales per store aggregations, gross revenue per quarter by department, or the daily active website users.
The output has actionable insights, reports of business metrics, and dashboards. Most of the IoT or sensor devices generate data across various ingestion paths. Batch data is ingested with Azure databricks or the Azure Data factory. Streaming data is consumed from IoT Hub or Event Hub. The data that is extracted and transformed is loaded to Delta Lake.
FAQ
FAQs are as mentioned below:
Q1. What are the DML and DDL statements that Delta does not support?
Answer:
Overwrite, Bucketing, specifying target partitions in the truncate table, and Specifying schema while reading a table are the DML statements that Delta does not support. Analyze Table, Load Data, Create table, and Alter table is the DDL statements that Delta does not support.
Q2. How is Delta lake related to Apache Spark?
Answer:
Databricks Delta lake sits on top of the Apache Spark. The compute and format layer helps simplify building big data pipelines and increase pipelines’ overall efficiency.
Q3. Can users stream data directly into and from the Delta Tables?
Answer:
Yes, users can use structured streaming to write data into delta tables directly and read.
Conclusion
With this, we conclude the topic “Databricks Delta Lake.” We have seen what Databricks Delta Lake means and how to use the Delta lake workspace with steps to work on the batch and streaming data, along with the Architecture and the Model of Delta Lake. We have also listed out the key takeaways of Delta Lake and have seen a few of the FAQs to help better.
Recommended Articles
This is a guide to Databricks Delta Lake. Here we discuss the introduction, model, and how to use Databricks delta lake workspace with FAQ. You may also have a look at the following articles to learn more –

