Updated March 8, 2023

Introduction to dataset preprocessing
In the actual world, data is frequently incomplete: it lacks attribute values, specific attributes of relevance are missing, or it simply contains aggregate data. Errors or outliers make the data noisy. Inconsistent: having inconsistencies in codes or names. The Keras dataset pre-processing utilities assist us in converting raw disc data to a tf. data file. A dataset is a collection of data that may be used to train a model. In this topic, we are going to learn about dataset preprocessing.
Why use dataset pre-processing?
By pre-processing data, we can:
- Improve the accuracy of our database. We remove any values that are wrong or missing as a consequence of human error or problems.
- Consistency should be improved. The accuracy of the results is harmed when there are data discrepancies or duplicates.
- Make the database as complete as possible. If necessary, we can fill up the missing properties.
- The data should be smooth. We make it easier to use and interpret this manner.
We have few Dataset pre-processing Utilities:
- Image
- Text
- Time series
Importing datasets pre-processing
Steps for Importing a dataset in Python:
- Importing appropriate Libraries
We’ll need to import NumPy and Pandas every time we construct a new model. Pandas is used to import and handle data sets, while NumPy is a library that contains mathematical operations and is used for scientific computing.
import matplotlib.pyplot as mpt
- Import Datasets
The datasets are in the.csv format. A CSV file is a plain text file that consists of tabular data. A data record is represented by each line in the file.
dataset = pd.read_csv('Data.csv')
We’ll use pandas’ iloc (used to fix indexes for selection) to read the columns, which has two parameters: [row selection, column selection].
x = Dataset.iloc[:, :-1].values
Let’s have the following incomplete datasets
| Name | Pay | Managers |
| AAA | 40000 | Yes |
| BBB | 90000 | |
| 60000 | No | |
| CCC | Yes | |
| DDD | 30000 | Yes |
As we can see few missing cells are in the table. To fill these we need to follow a few steps:
from sklearn.preprocessing import Imputer
Next By importing a class
Using not a number (NAN)
A=pd.DataFrame(np.array())
// Using Missing Indicator to fit transform.
Splitting a dataset by training and test set.
Installing a library:
from sklearn.cross_validation import train_test_split
A_train, A_test, B_train, B_test = train_test_split(X, Y, test_size = 0.2)
Feature Scaling
from sklearn.preprocessing import StandardScaler
scale_A = StandardScaler()
A_train = scale_A.fit_transform(A_train)
A_test = scale_A.transform(A_test)
Example #1
# importing libraries
from sklearn.preprocessing import StandardScaler
import pandas
import NumPy# link for the required dataset
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data"
# parameters
names = ['sno', 'sname', 'age', 'Type', 'diagnosis', 'in', 'out', 'consultant', 'class']
dataframe = pandas.read_csv(url, names = names)
array = dataframe.values
//Array element for inputs
X = array[:, 0:8]
Y = array[:, 8]
scaler = StandardScaler().fit(X)
rescaledX = scaler.transform(X)
numpy.set_printoptions(precision = 3)
print(rescaledX[0:6,:])
Explanation
All of the data preprocessing procedures are combined in the above code.
Output:
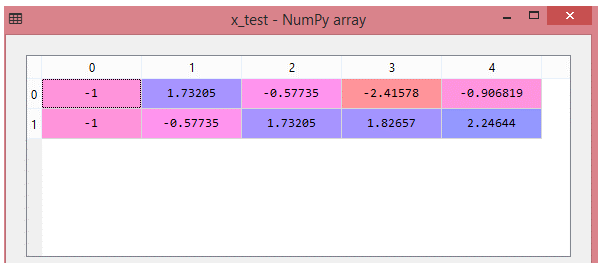
Feature datasets pre-processing
- Outliers are removed during pre-processing, and the features are scaled to an equivalent range.
Steps Involved in Data Pre-processing
- Data cleaning: Data can contain a lot of useless and missing information. Data cleaning is carried out to handle this component. It entails dealing with missing data, noisy data, and so on. The purpose of data cleaning is to give machine learning simple, full, and unambiguous collections of examples.
a) Missing Data: This occurs when some data in the data is missing. It can be explored in many ways.
Here are a few examples:
Ignore the tuples: This method is only appropriate when the dataset is huge and many values are missing within a tuple.
Fill in the blanks: There are several options for completing this challenge. You have the option of manually filling the missing values, using the attribute mean, or using the most likely value.
b) Noisy Data: Data with a lot of noise
The term “noise” refers to a great volume of additional worthless data.
Duplicates or semi-duplicates of data records; data segments with no value for certain research; and needless information fields for each of the variables are examples of this.
It can be dealt with in the following ways:
Method of Binning:
This approach smoothes data that has been sorted. The data is divided into equal-sized parts, and the process is completed using a variety of approaches.
Regression:
Regression analysis aids in determining which variables do have an impact. To smooth massive amounts of data, use regression analysis. This will help to focus on the most important qualities rather than trying to examine a large number of variables.
Clustering: In this method, needed data is grouped in a cluster. Outliers may go unnoticed, or they may fall outside of clusters.
- Data Transformation
We’ve already started modifying our data with data cleaning, but data transformation will start the process of transforming the data into the right format(s) for analysis and other downstream operations. This usually occurs in one or more of the following situations:
- Aggregation
- Normalization
- Selection of features
- Discretization
- The creation of a concept hierarchy
- Data Reduction:
Data mining is a strategy for dealing with large amounts of data. When dealing with bigger amounts of data, analysis faces quite a complication. We employ a data reduction technique to overcome this problem. Its goal is to improve storage efficiency and reduce analysis expenses. Data reduction not only simplifies and improves analysis but also reduces data storage.
The following are the steps involved in data reduction:
Attribute selection: Like discretization, can help us fit the data into smaller groups. It essentially combines tags or traits, such as male/female and manager, to create a male manager/female manager.
Reduced quantity: This will aid data storage and transmission. A regression model, for example, can be used to employ only the data and variables that are relevant to the investigation at hand.
Reduced dimensionality: This, too, helps to improve analysis and downstream processes by reducing the amount of data used. Pattern recognition is used by algorithms like K-nearest neighbors to merge similar data and make it more useful.
Conclusion – dataset preprocessing
Therefore, coming to end, we have seen Dataset processing techniques and their libraries in detail. The data set should be organized in such a way that it can run many Machines Learning and Deep Learning algorithms in parallel and choose the best one.
Recommended Articles
This is a guide to dataset preprocessing. Here we discuss the Dataset processing techniques and their libraries in detail. You may also have a look at the following articles to learn more –

