Updated July 7, 2023

Definition of DataStage
DataStage is an ETL tool that is used to Extract data from different data sources, Transform the data as per the business requirement and Load it into the target database. The data source can be of any type, like Relational databases, files, external data sources, etc. Using the DataStage ETL tool; we provide quality data, which in return is used for Business Intelligence. Vmark first launched DataStage, and later it was acquired by IBM. DataStage was called earlier ‘Data Integrator.’
Why do we need DataStage?
Before going to the query ‘Why we need DataStage.’ Let us know about traditional batch processing.
1. Load data from source to Disk
2. Disk to perform transformations and then save to disk.
3. Disk to Target.
In the traditional batch, processing becomes impractical with big data volumes; very complex to manage lots of small jobs needed to achieve the requirement.
To overcome the above drawbacks, we needed batch processing that can be done parallelly. For this need, we got the ETL batch processing system to deal with large volumes of data parallel.
How does DataStage works?
Datastage usually undergoes below steps:
- We design jobs for extraction, transformation, and loading in a sequential job manner or Parallel manner.
- Schedule, run, and monitor the jobs.
- Create batch jobs.
Architecture of Datastage
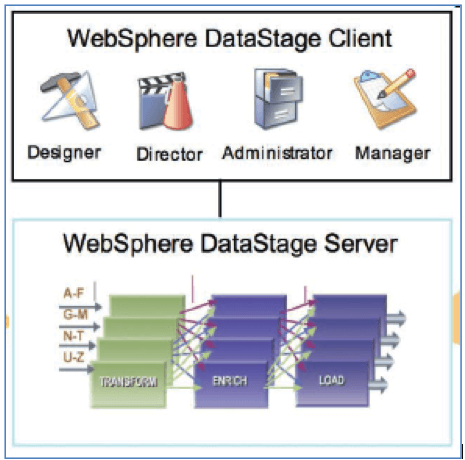
Datastage usually has different components that would help us achieve the overall extraction, transformation, and load.
- Administrator: – Manages the global settings and interacts with systems.
- Designer: – Here designer is used to create Datastage jobs, job sequences which in turn are compiled into executable programs. The designer is mainly for developers.
- Director: – This is used to monitor and manage the Datastage jobs. Used by DataStage support roles to monitor the jobs and fix job failures.
- Manager: – It is used to manage, browse, and edit the data warehouse repository.
The Terminology that we use is as below:
- Project
- Job
- Stage
- Link
Types of Jobs: – Parallel jobs, job sequences, and server jobs.
Parallel Jobs:
- Stages and links combined in a shared container.
- Reuse of instances of the shared container in various other parallel jobs. But the container can be used only within the job defined.
Server Jobs:
- Used to represent sources, conversion stages, or targets.
- We have two stages: – active and passive stages.
Links:
- Links various stages in a job and indicates the flow of data when the job is run.
Server Architecture
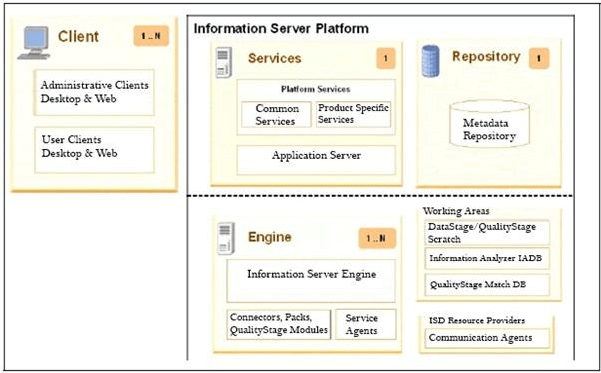
Processing Stage Types
Datastage job usually consists of stages, links, and transform. The stages are nothing but the flow of data from a data source to the target data source. The stage can have a minimum single data source as input or multiple data sources and one or more data output.
Let us discuss the various stages that we use in DataStage: In Job design, various stages you can use are:
- Transform stage
- Filter stage
- Aggregator stage
- Remove duplicates stage
- Join stage
- Lookup stage
- Copy stage
- Sort stage
- Containers
Advantages and Disadvantages of Datastage
| Advantages | Disadvantages |
| Connect to multiple types of data sources | We need to either install of connect to the server for the ETL work. |
| The large volume of data. Bulk transfer and complex transformation | No automated mechanism for error handling and recovery. |
| Refresh and synchronize data as much as needed. | We don’t have a UNIX Datastage client. |
| Reliable and Flexible to connect to different types of databases. | Affording the software might go expensive for small or mid-size companies. |
| Partitioning algorithms | |
| Easy integration and a single interface to integrate heterogeneous sources. | |
| Performs well in both Windows and Unix servers. |
Features of Datastage
- It supports the transformation of large-volume data.
- Real-time data integration, which enables connectivity between data sources and applications.
- Optimize hardware utilization.
- Supports collection and integration.
- Powerful, Scalable, Speed, flexible, and effective to build, deploy, update, and manage your data integration.
- Support big data and Hadoop.
Uses of DataStage in various fields or companies:
The fields or companies that use the DataStage are Cooper Companies, SAS, etc.
To know more about this, use the below link, which would give a picture:
https://enlyft.com/tech/products/ibm-infosphere-datastage
Career path for DataStage :
Current scenario, ETL tool usage is on the rise. And we can see that ETL is not confined to a particular industry. ETL is used in each and every industry to manage the data and make it a usable format.
We do have other tools called Informatica, Talend ETL tool, which is cheaper than DataStage.
To be more specific to the career path, we can learn data analytics which would be easier to handle and be a career milestone in the career path since you already have good knowledge of ETL tools.
Conclusion
Things that need to be remembered from the above session are the definition and flow of the DataStage job. The data source can be of any type, like Relational databases, files, external data sources, etc., Using the DataStage ETL tool.
It usually undergoes below steps:
- We design jobs for extraction, transformation, and loading in a sequential job manner or Parallel manner.
- Schedule, run, and monitor the jobs.
- Create batch jobs.
Key aspects as below: –
- Data transformation
- Jobs
- Parallel processing
It has four main components,
- Administrator
- Manager
- Designer
- Director
Refresh and synchronize data as much as needed. Reliable and Flexible to connect to different types of databases. Partitioning algorithms Easy integration and a single interface to integrate heterogeneous sources.
Recommended Articles
This is a guide to DataStage. Here we discuss the Definition, How it works? Features, Advantages, and Disadvantages. You can also go through our other suggested articles to learn more –
