Introduction
Convolutional Neural Networks (CNNs) have revolutionized image processing and computer vision by efficiently extracting hierarchical features, yet understanding their decision-making processes remains challenging. Deconvolutional Networks, a CNN offshoot, address this by visualizing and interpreting learned features. By reverse-mapping activations to the input space, they enhance model comprehension. This article explores Deconvolutional Networks, discussing their components like transposed convolutional layers and applications such as image segmentation. It also examines training challenges and proposes solutions, ultimately enhancing CNN interpretability and opening new research avenues in deep learning.
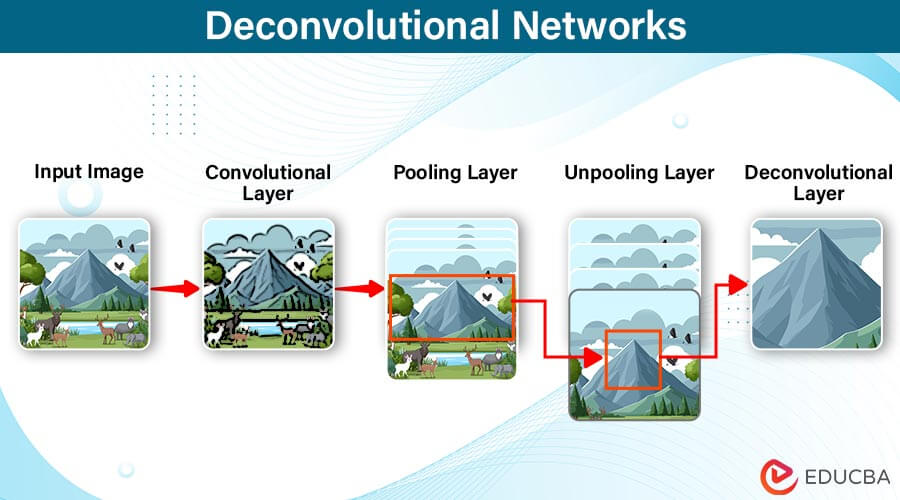
Table of Contents
What is Deconvolutional Networks
Deconvolutional Networks, transposed convolutional networks, or up-convolutional networks, uniquely complement Convolutional Neural Networks (CNNs). While CNNs excel at feature extraction, Deconvolutional Networks specialize in reverse mapping feature activations back to the input space, enhancing model interpretability. It is particularly beneficial in tasks like image classification and object detection. Visualizing learned features in the input space provides crucial insights into the model’s decision-making process. Ultimately, Deconvolutional Networks enhance the transparency of CNNs, instilling trust in the deep learning model. It is essential in domains where interpretability is critical, such as healthcare and autonomous driving, where the ability to understand and explain the model’s decisions is paramount.
Relationship to CNN
- It is closely tied to CNNs, sharing foundational convolution and feature learning principles.
- It act as the inverse of CNNs, reconstructing original input dimensions from learned feature representations.
- While CNNs reduce spatial dimensions and increase feature map depth, Deconvolutional Networks reverse this process for reconstruction.
- This inverse mapping reveals hierarchical feature structure learned by CNNs, aiding in visualizing decision-making processes.
Key Components and Operations
- Upsampling:
- Upsampling is a fundamental operation in Deconvolutional Networks, performed by transposed convolutional layers.
- It involves increasing the spatial dimensions of feature maps to match those of the input data.
- Upsampling is essential for reconstructing detailed spatial information lost during the downsampling process in CNNs.
- Fusion Operations:
- It often incorporates fusion operations, such as skip connections or concatenation, to combine information from multiple layers.
- These fusion operations enhance the fidelity of reconstructed features by leveraging information from different hierarchical levels within the network.
- Padding and Stride Adjustments:
- Padding and stride adjustments are critical parameters in transposed convolutional layers.
- The padding ensures that the output dimensions of transposed convolutional layers match the desired dimensions, preventing information loss.
- Stride adjustments control the step size of the convolution operation, influencing the output spatial resolution.
Transposed Convolution
Alternatively termed deconvolution or up-convolution, transposed convolution constitutes a cornerstone operation within Deconvolutional Networks. It functions as the converse process of standard convolution, pivotal for reconstructing the initial input dimensions from the acquired feature representations. Unlike standard convolution, which reduces feature map dimensions, transposed convolution expands them, reinstating the spatial resolution lost during downsampling. This operation is indispensable for restoring intricate spatial details within feature maps and is crucial for image reconstruction and generative modeling tasks.
How Transposed Convolution Works
- Transposed convolution is a vital operation within Deconvolutional Networks. It functions similarly to standard convolution by applying a filter to each position in the input feature map.
- Unlike standard convolution, transposed convolution expands output dimensions strategically by padding zeros between input elements and introducing zeros in the output feature map. It ensures the output feature map size is larger than the input, facilitating upscaling.
- During the convolution operation in transposed convolution, the filter moves across the input feature map, akin to standard convolution. However, due to the zero padding strategy, the filter activations spread across a larger area, resulting in an output feature map with increased spatial dimensions.
- This expansion of spatial dimensions is critical for reconstructing detailed features and restoring the original resolution lost during the network’s downsampling process by earlier layers.
- Transposed convolution allows the network to learn how to reconstruct high-resolution features from low-resolution representations, enabling tasks like image super-resolution, semantic segmentation, and generative modeling.
- By grasping the intricacies of transposed convolution, practitioners can effectively utilize Deconvolutional Networks to generate high-fidelity reconstructions and gain deeper insights into the learned representations within the network.
Unsampling in Deconvolution Network
- Upsampling is a critical element found in transposed convolutional layers of Deconvolutional Networks, designed to increase the spatial dimensions of feature maps to match those of the input data.
- Its primary function is to ensure the preservation of the information’s spatial integrity while expanding the dimensions of the feature maps.
- Achieved through transposed convolution operations, upsampling enlarges the feature map dimensions while conserving the spatial relationships between individual elements.
- Maintaining spatial information is crucial to ensure detailed spatial characteristics in the original input persist throughout the reconstruction process.
- Additionally, upsampling addresses the loss of detailed spatial information during the downsampling process in Convolutional Neural Networks (CNNs).
- In CNNs, the successive application of convolutional and pooling layers gradually reduces the spatial dimensions of feature maps, leading to a loss of fine-grained spatial details.
- Upsampling in Deconvolutional Networks mitigates this loss by reconstructing the finer spatial details, thereby enabling the generation of high-resolution output.
- Upsampling facilitates tasks such as image super-resolution, semantic segmentation, and generative modeling by restoring lost spatial information.
- These tasks often require preserving detailed spatial features to achieve high-quality results.
- Thus, incorporating upsampling operations within transposed convolutional layers improves the performance and effectiveness of Deconvolutional Networks across a range of computer vision tasks.
Application of Deconvolutional Networks
- Image Segmentation:
- Researchers extensively employ deconvolutional networks in image segmentation tasks, aiming to partition an image into distinct regions or segments.
- By leveraging the reconstruction capabilities of Deconvolutional Networks, researchers can generate pixel-level predictions, assigning each pixel to a specific class or category.
- Medical image analysis extensively utilizes this application, autonomous driving systems, and satellite image interpretation.
- Image Super-Resolution:
- It plays a pivotal role in image super-resolution, a task focused on enhancing the resolution and quality of low-resolution images.
- It enables the generation of visually pleasing and informative high-resolution images by reconstructing high-resolution details from low-resolution representations.
- This application is precious in domains such as digital photography, medical imaging, and video processing, where high-quality visual content is essential.
- Generative Modeling:
- It are integral to generative modeling frameworks like autoencoders and Generative Adversarial Networks (GANs).
- In autoencoders, Deconvolutional Networks facilitate the reconstruction of input data from compressed latent representations, enabling tasks such as image denoising and anomaly detection.
- Within GANs, Deconvolutional Networks serve as the generator component, transforming random noise into realistic images through adversarial training.
- These applications are widely used in image synthesis, style transfer, and data augmentation, among other fields, and have implications for fields like art, entertainment, and design.
- Semantic Image Synthesis:
- It contributes significantly to semantic image synthesis, a task that generates realistic images from semantic descriptions or sketches.
- By learning to map semantic representations to pixel-level details, Deconvolutional Networks enable the creation of visually coherent and contextually relevant images.
- This application has diverse applications, including virtual scene generation, augmented reality, and creative content creation, with potential implications for gaming, advertising, and virtual design industries.
Training Deconvolutional Networks
Challenges in Training
- Training Deconvolutional Networks presents challenges, including vanishing gradients, overfitting, and mode collapse.
- Vanishing gradients occur due to the deep architecture of Deconvolutional Networks, hindering the effective propagation of gradients during backpropagation.
- Overfitting can arise when the model learns to memorize training data rather than generalize to unseen examples, particularly in the presence of limited training data.
- Mode collapse, often encountered in generative modeling tasks, occurs when the generator fails to capture the full diversity of the data distribution, generating repetitive or low-quality samples.
Strategies for Training Deconvolutional Networks
- Techniques such as batch normalization, gradient clipping, and skip connections stabilize training by ensuring that gradients neither become too large nor too small. Batch normalization normalizes layer activations, while gradient clipping limits gradient magnitudes. Additionally, skip connections facilitate gradient flow by providing alternative paths through the network.
- Regularization techniques like dropout address overfitting, which randomly ignores neurons during training, preventing the model from memorizing noise in the data. Data augmentation is another strategy that increases dataset diversity by applying transformations to the training data, exposing the model to a wider array of scenarios. Early stopping monitors performance on a validation set, halting training when performance deteriorates, thus preventing excessive reliance on the training data.
- Diversity-promoting objectives penalize high-probability modes in the output distribution, encouraging the generation of diverse samples and discouraging mode collapse. Perceptual losses compare features extracted from generated and real samples, minimizing perceptual differences and ensuring generated samples are visually similar to real ones. These strategies collectively mitigate mode collapse and enhance sample quality during training.
Loss Function and Evaluation Metrics
- Loss Function Selection: The choice of loss function significantly impacts the training of Deconvolutional Networks. Popular loss functions comprise mean squared error (MSE), cross-entropy loss, and adversarial loss, each serving different purposes in guiding the optimization process.
- Evaluation Metrics for Image Segmentation: Evaluation metrics such as dice loss or intersection over union (IoU) are prevalent in image segmentation tasks. These metrics quantify the agreement between predicted segmentation masks and ground truth annotations.
- Metrics for Image Super-Resolution: Image super-resolution tasks often employ metrics like peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) to evaluate the fidelity and perceptual quality of the reconstructed images.
- Evaluation Metrics in Generative Modeling: For generative modeling tasks, Researchers commonly use evaluation metrics such as Inception Score (IS) and Fréchet Inception Distance (FID) to assess the diversity and realism of generated samples.
Future Directions and Challenges
- Advancements in Architecture: Future progress in Deconvolutional Networks might involve developing more intricate architectures utilizing attention mechanisms, graph convolutional layers, or memory-augmented structures. These advancements enhance the model’s capability to grasp long-range dependencies, contextual information, and semantic relationships within the data.
- Improving Robustness to Noisy Data: Deconvolutional Networks need to exhibit greater resilience to noisy and imperfect input data. Research efforts could prioritize the development of techniques for noise reduction, data augmentation, and domain adaptation to enhance model performance in real-world scenarios characterized by noisy or incomplete data.
- Interpretability and Transparency: With the rising deployment of Deconvolutional Networks in critical domains like healthcare and autonomous driving, there’s an increasing demand for interpretable and explainable models. Future investigations may concentrate on devising methods for visualizing and comprehending the learned representations in Deconvolutional Networks, thereby augmenting their interpretability and trustworthiness.
- Transfer Learning and Adaptability: Leveraging transfer learning and few-shot learning techniques could enable deconvolutional networks to better generalize new tasks and datasets with limited labeled data. Future research endeavors explore strategies for pre-training Deconvolutional Networks on extensive datasets and fine-tuning them for specific functions with limited data, enhancing their adaptability and performance.
- Enhancing Adversarial Robustness: Adversarial attacks pose substantial threats to the resilience and dependability of deep learning models, including Deconvolutional Networks. Future research directions might focus on devising defenses against adversarial attacks, such as robust optimization techniques, adversarial training, and methods for detecting adversarial examples, to bolster the model’s resilience to adversarial perturbations.
- Efficiency and Scalability Considerations: Deconvolutional Networks often demand substantial computational resources for training and inference, constraining their deployment on resource-limited devices or large-scale distributed systems. Future research endeavors could explore techniques for optimizing the efficiency and scalability of Deconvolutional Networks, encompassing strategies like model compression, quantization, and parallelization, to render them more accessible and practical for real-world applications.
Conclusion
Deconvolutional Networks are a formidable category of neural networks that find wide-ranging applications in image processing, computer vision, and generative modeling. Despite their efficacy, persistent challenges such as vanishing gradients, overfitting, and mode collapse underscore the ongoing need for research. Nevertheless, with strides in architecture design, resilience to noisy data, interpretability enhancements, and advancements in adversarial robustness, Deconvolutional Networks hold significant promise in tackling intricate real-world problems. Overcoming these obstacles and harnessing their capabilities, Deconvolutional Networks position themselves to drive substantial advancements across various machine learning and artificial intelligence domains.
Frequently Asked Questions (FAQs)
Q1. How can Deconvolutional Networks be made more efficient and scalable?
Answer: Techniques such as model compression, quantization, and parallelization can be employed to optimize the efficiency and scalability of Deconvolutional Networks, making them more suitable for deployment on resource-limited devices or in large-scale distributed systems.
Q2. Are there pre-trained models or libraries available for Deconvolutional Networks?
Answer: Indeed, numerous pre-trained models and libraries cater to Deconvolutional Networks. TensorFlow offers options like tf.keras.layers.Conv2DTranspose, while PyTorch provides torch.nn.ConvTranspose2d. Moreover, pre-trained models trained on extensive datasets such as ImageNet are accessible, facilitating transfer learning for targeted tasks.
Q3. How do Deconvolutional Networks manage various image data formats, like grayscale versus color images?
Answer: Deconvolutional Networks accommodate diverse image data formats, such as grayscale and color images, by adjusting their input and output channels accordingly. In grayscale images, the network usually operates on a single channel. In contrast, for color images like RGB, it processes multiple channels representing distinct color components such as red, green, and blue.

