Updated June 23, 2023

Introduction to Deep Learning Interview Questions
The following article provides an outline for Deep Learning Interview Questions. Today Deep Learning has been seen as one of the fastest-growing technologies with a vast capability to develop an application that was seen as brutal some time back. Speech recognition, image recognition, finding patterns in a dataset, object classification in photographs, character text generation, self-driving cars, and many more are just a few examples where Deep Learning has shown its importance.
You have finally found your dream job in Deep Learning but are wondering how to crack the 2023 Deep Learning Interview and what could be the probable Deep Learning Interview Questions. Every Interview is different, and the job scope is different too. Keeping this in mind, we have designed the most common Deep Learning Interview Questions and Answers to help you get success in your Interview.
Below are a few Deep Learning Interview questions that are frequently asked in Interviews and would also help to test your levels:
Part 1 – Deep Learning Interview Questions (Basic)
This first part covers basic Deep Learning Interview Questions and Answers:
Q1. What is Deep Learning?
Answer:
The area of machine learning focuses on deep artificial neural networks, which are loosely inspired by brains. Alexey Grigorevich Ivakhnenko published the first general on working Deep Learning networks. Today it has applications in various fields, such as computer vision, speech recognition, and natural language processing.
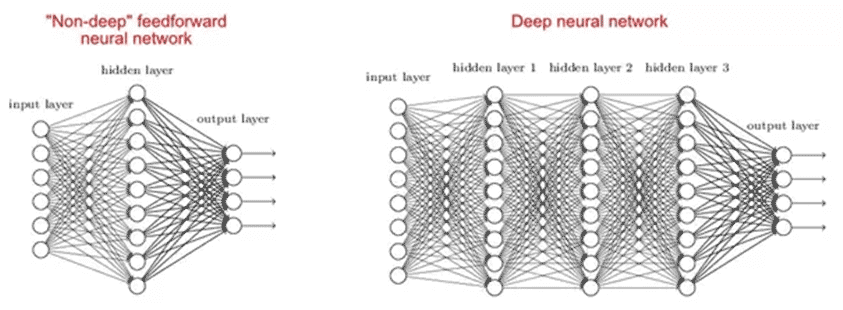
Q2. Why are Deep Networks better than shallow ones?
Answer:
Some studies say shallow and deep networks can fit any function, but deep networks have several hidden layers, often of different types. Hence, they can build or extract better features than shallow models with fewer parameters.

Q3. What is the Cost Function?
Answer:
A cost function is a measure of the accuracy of the neural network with respect to the given training sample and expected output. It is a single value, nonvector, as it gives the performance of the neural network as a whole.
It can be calculated as below Mean Squared Error function:
Where Y^ and desired value Y are what we want to minimize.
Q4. What is Gradient Descent?
Answer:
Gradient descent is basically an optimization algorithm that is used to learn the value of parameters that minimizes the cost function. It is an iterative algorithm that moves in the direction of the steepest descent as defined by the negative of the gradient. We compute the gradient descent of the cost function for a given parameter and update the parameter by the below formula:
Where Θ – is the parameter vector, α – learning rate, J(Θ) – is a cost function.
Q5. What is Backpropagation?
Answer:
Backpropagation is a training algorithm used for a multilayer neural network. In this method, we move the error from an end of the network to all weights inside the network and thus allow efficient computation of the gradient.
- Forward propagation of training data to generate output.
- Then we backpropagate for computing the derivative of the error with respect to output activation on the previous and continue this for all the hidden layers.
- Using previously calculated derivatives for output and all hidden layers, we calculate error derivatives with respect to weights.
- And then, we update the weights.
Q6. Explain the following three variants of gradient descent: batch, stochastic, and mini-batch.
Answer:
- Stochastic Gradient Descent: Here, we use only a single training example for the calculation of gradient and update parameters.
- Batch Gradient Descent: Here, we calculate the gradient for the whole dataset and perform the update at each iteration.
- Mini-batch Gradient Descent: It’s one of the most popular optimization algorithms. It’s a variant of Stochastic Gradient Descent, and here instead of a single training example, a mini-batch of samples is used.
Part 2 – Deep Learning Interview Questions (Advanced)
Let us now have a look at the advanced Deep Learning Interview Questions:
Q7. What are the benefits of Mini-Batch Gradient Descent?
Answer:
Below are the benefits of mini-batch gradient descent:
- This is more efficient compared to stochastic gradient descent.
- The generalization by finding the flat minima.
- Mini-batches allow help to approximate the gradient of the entire training set, which helps us to avoid local minima.
Q8. What is Data Normalization, and why do we need it?
Answer:
Data normalization is used during backpropagation. The main motive behind data normalization is to reduce or eliminate data redundancy. Here we rescale values to fit into a specific range to achieve better convergence.
Q9. What is Weight Initialization in Neural Networks?
Answer:
Weight initialization is one of the very important steps. A bad weight initialization can prevent a network from learning, but good weight initialization helps give a quicker convergence and a better overall error. The rule for setting the weights is to be close to zero without being too small.
Q10. What is an Auto-Encoder?
Answer:
An autoencoder is an autonomous Machine learning algorithm that uses the backpropagation principle, where the target values are set to be equal to the inputs provided. Internally, it has a hidden layer that describes a code used to represent the input.
Some key facts about the autoencoder are as follows:
- It is an unsupervised ML algorithm similar to Principal Component Analysis.
- It minimizes the same objective function as Principal Component Analysis.
- It is a neural network.
- The neural network’s target output is its input.
Q11. Is it ok to connect from a Layer 4 output back to a Layer 2 input?
Answer:
Yes, this can be done considering that layer 4 output is from the previous time step like in RNN. Also, we need to assume that the previous input batch is sometimes- correlated with the current batch.
Q12. What is the Boltzmann Machine?
Answer:
Boltzmann Machine is used to optimize the solution of a problem. The work of the Boltzmann machine is basically to optimize the weights and the quantity for the given problem.
Some important points about Boltzmann Machine are as follows:
- It uses a recurrent structure.
- It consists of stochastic neurons, consisting of one of the two possible states, 1 or 0.
- The neurons in this are either in an adaptive (free state) or clamped (frozen state).
- If we apply simulated annealing on a discrete Hopfield network, then it would become Boltzmann Machine.
Q13. What is the Role of the Activation Function?
Answer:
The activation function introduces non-linearity into the neural network, helping it learn more complex functions. Without this, the neural network would be only able to learn linear function, which is a linear combination of its input data.
Recommended Articles
We hope that this EDUCBA information on “Deep Learning Interview Questions” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
