Updated May 8, 2023

Introduction to Elasticsearch Java Client
The following article provides an outline for Elasticsearch Java Client. Elasticsearch is one of the distributed, free, open-source search and analytics engines for users to perform the textual, numerical, geographic, and both structured and unstructured data for Elasticsearch. It is based upon Apache, not known for Elastic. However, it also analyzes a huge amount of data easily known in real-time, and it’s back to the response in milliseconds to achieve a faster response.
What is Elasticsearch Java Client?
Java has different types like Low-Level REST Client; the Java High-Level REST Client is used. Its major objective is to expose the API-specific methods. They take the web page request objects as passed the arguments and return the response objects, allowing the web client to handle the request marshaling and response unmarshalling. For example, the Elasticsearch core project is mostly required by the Java High-Level REST Client. It takes and handles the same web request for all input types, and we get the same response objects as the TransportClient, which the server returns.
Elasticsearch Java Client Running
Suppose we have ever used Apache Lucene or Apache Solr. In that case, we may know how difficult it can be to handle this because we need to understand the rationale behind the Elasticsearch project, especially if we need to scale the Lucene- or Solr-based solution. Then Elasticsearch (based on Lucene) offers a high-performance full-text search engine with a simple-to-manage package that enables clustered scaling right out of the box. If we used Elasticsearch, that could be accessed via a standard REST API or client libraries for various programming languages. Generally, Splitting the client into two different components like the RestClient and the RestHighLevelClient is one of the basic fundamental ideas. It has the lower-level counterpart, which is in charge of connection, tracing, automatic node finding, and load balancing; At the same time, the higher-level counterpart it’s in charge of creating requests without requiring the user to submit JSON strings or byte-type arrays. Also, now the client is waiting and dependent on the Elasticsearch Core Project; however, there may be a long way to use this in future trends. Because the Elasticsearch client is built on the Apache HTTP Client, it may be used with Java 8 technology. Because the Apache HTTP client and its dependencies are so widely used, it might want to think about the darkening of the client. It has thread safety, and it is built into the client. A single instance we used across the web application should be good. Asynchronous and n number of blocking modes, which are used, and an asynchronous mode employing listeners, are all supported by the client.
Elasticsearch Java Client Application
If we have used Apache Lucene or Apache Solr, we may know how difficult it can be to handle Elasticsearch in java clients. We also understand the rationale behind the Elasticsearch project, especially if we needed to scale the Lucene- or Solr-based solution. The Elasticsearch is based on Lucene Apache, and it offers high-performance for full-text search in a simple-to-manage package that enables the clustered for scaling right out of the box. The Elasticsearch can be accessed via a standard REST API or Java client libraries for various programming languages. The most obvious thing is the initial option to use the native Elasticsearch client. There is no separate jar file containing the client API instead of integrating the entire Elasticsearch application. It is mainly due to the client part and its method for connecting the Elasticsearch instead of using the REST API. The cluster node is connected to each type of cluster and does not generally carry the data, but it is mainly aware of the cluster’s status.
Examples of Elasticsearch Java Client
Different examples are mentioned below:
Example #1
Code:
import java.io.IOException;
import java.util.Arrays;
import java.util.Map;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
public class FirstConnector {
@SuppressWarnings("deprecation")
public static void main(String[] args) {
@SuppressWarnings("deprecation")
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
SearchRequest Sr = new SearchRequest();
Sr.indices("Fetching First Record");
SearchSourceBuilder sr2 = new SearchSourceBuilder();
sr2.query(QueryBuilders.matchAllQuery());
Sr.source(sr2);
Map<String, Object> map=null;
try {
SearchResponse resp = null;
resp =client.search(Sr, RequestOptions.DEFAULT);
if (resp.getHits().getTotalHits().value > 0) {
SearchHit[] srch = resp.getHits().getHits();
for (SearchHit sh : srch) {
map = sh.getSourceAsMap();
System.out.println("map:"+Arrays.toString(map.entrySet().toArray()));
}
}
} catch (IOException es) {
es.printStackTrace();
}
}
}Sample Output:
![]()
In the above example, we used elasticsearch with the kibana tool to perform the java client search operation. It has nothing but the REST API client. We have to send the Request as the JSON format, and Response also we get JSON; in the above example, I used Elasticsearch with kibana UI,
The elasticsearch is running on the port localhost:9200,
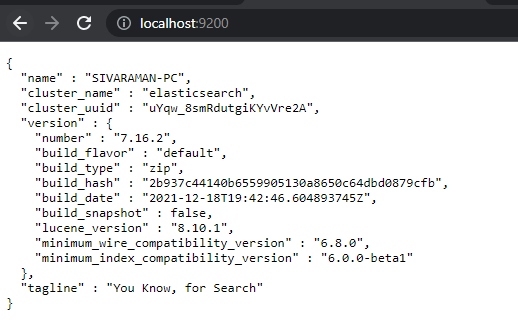
The kibana is running on the port called http://localhost:5601/app/dev_tools#/console,
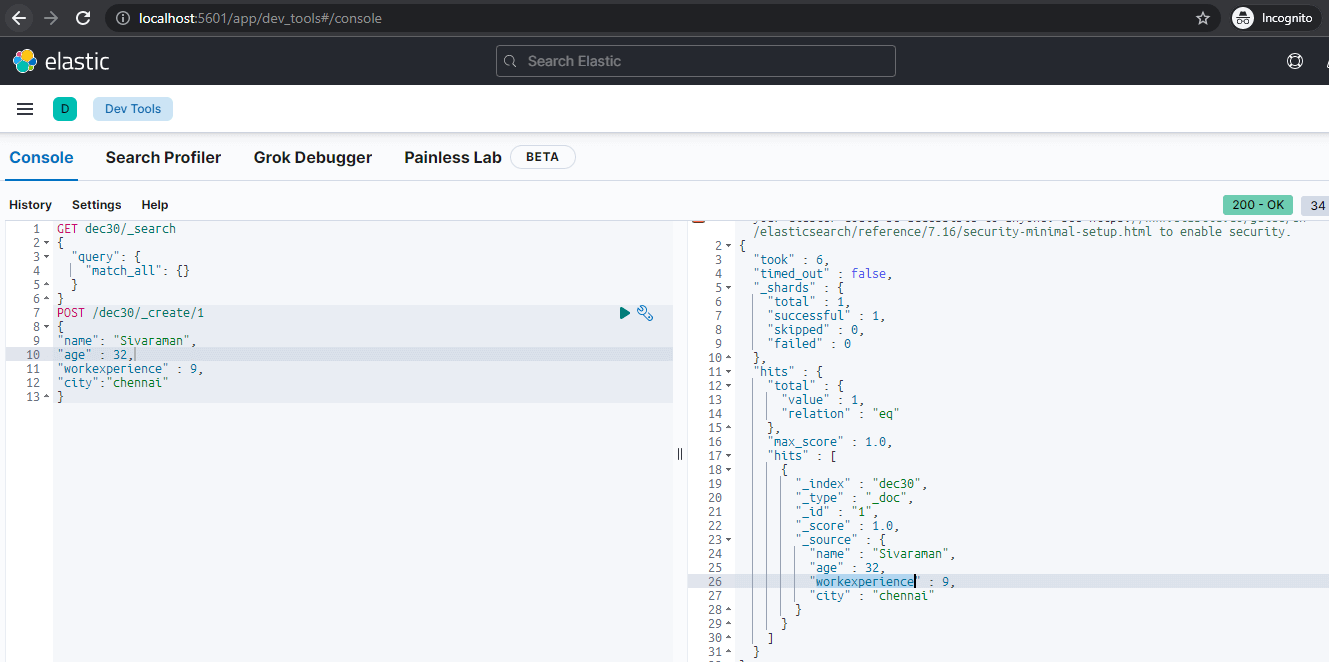
With the help of Dev tools, we can send the request using the POST method and Receive the response using the GET method. So that we can retrieve the data using the ElasticSearch Search API.
Example #2
Code:
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import org.apache.http.HttpHost;
import org.apache.lucene.index.Terms;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.mapper.ObjectMapper;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.builder.SearchSourceBuilder;
public class FirstConnector {
private static final String hst = "localhost";
private static final int prt1 = 9200;
private static final int prt2 = 9201;
private static final String sch = "http";
public static void main(String[] args) throws Exception{
RestHighLevelClient cl = new RestHighLevelClient(
RestClient.builder(new HttpHost("localhost", 9200, "http")));
SearchRequest sr = new SearchRequest();
sr.indices("Welcome");
SearchSourceBuilder srb = new SearchSourceBuilder();
srb.query(QueryBuilders.matchAllQuery());
srb.aggregation(AggregationBuilders.terms("Find the unique Distince values").field("second month. keyword"));
sr.source(srb);
Map<String, Object> mp=null;
try {
SearchResponse srp = null;
srp =cl.search(sr, RequestOptions.DEFAULT);
if (srp.getHits().getTotalHits().value > 0) {
SearchHit[] searchHit = srp.getHits().getHits();
for (SearchHit hit : searchHit) {
mo = hit.getSourceAsMap();
System.out.println("mp:"+Arrays.toString(mp.entrySet().toArray()));
}
}
Aggregations agt = srp.getAggregations();
List<String> ls=new ArrayList<String>();
Terms trm= agt.get("Unique Distince Values");
List<? extends Terms.Bucket> bucs = trm.getBuckets();
for (Terms.Bucket buc : bucs) {
list.add(buxc.getKeyAsString());
}
System.out.println("Find the unique distinct values:"+ls.toString());
} catch (IOException ex) {
ex.printStackTrace();
}
}
}Sample output:

In the above example, we performed Elasticsearch using a java client to fetch the unique list elements in the output console.
Conclusion
Elasticsearch utilized the conjunction with the sample java clients used to execute the Rest client and the execution aggregation. It takes to locate the distinct and unique set of elements and values in the dataset, including storing and retrieving the data operations.
Recommended Articles
This is a guide to Elasticsearch Java Client. Here we discuss the definition, Elasticsearch Java Client running, application, and an example and code implementation. You may also have a look at the following articles to learn more –
