What is a Generative Adversarial Network?
Generative Adversarial Networks (GANs) represent a cutting-edge approach to generative modeling within deep learning. They are essentially frameworks for accomplishing unsupervised learning tasks.
GANs consist of two neural networks locked in an adversarial training dynamic. This means they function like a zero-sum game where one network’s gain comes at the expense of the other. These two networks are:
- Generator Network: This network acts as the data producer. It takes random noise as input and utilizes its understanding of the training data to transform it into novel instances that closely resemble real-world data from the training set.
- Discriminator Network: This network functions as a verifier or critic. Its objective is to discern between real data (sampled from the training set) and the synthetic data produced by the generator.
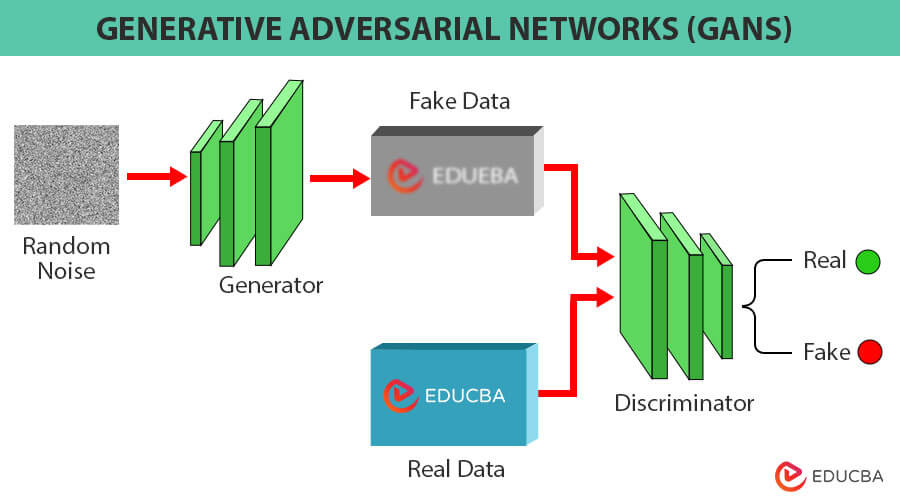
Table of Contents
Fundamentals of GANs
The Players:
- Two Neural Networks: GANs consist of two neural networks in an adversarial relationship:
- Generator Network (G): This network acts like an artist, taking random noise as input and using its knowledge of the training data to create new, realistic data (like images, text, or music).
- Discriminator Network (D): This network acts like a critic, trying to distinguish between the real data (from the training set) and the fake data generated by the generator.
The Training Process (The Adversarial Game):
- Generator’s Turn: The generator takes random noise and creates new data.
- Discriminator’s Turn: The discriminator receives both real data (from the training set) and the generated data. It then tries to determine which is which.
- Feedback and Improvement: Both networks update based on the discriminator’s success or failure using a process known as backpropagation.
- Generator Learns: When the discriminator is frequently fooled, the generator succeeds in creating increasingly realistic data.
- Discriminator Learns: If the discriminator successfully identifies fakes, it gets better at spotting them. However, if it’s fooled too easily, it needs to adjust to become more discerning.
The Outcome:
Through this ongoing competition, both networks become increasingly skilled. The generator gets better at creating data that appears real, while the discriminator hones its ability to detect forgeries. Ideally, this results in a system producing high-quality, realistic data that closely mirrors the training data.
GANs are unsupervised and use a zero-sum game framework to learn. For example, GANs can generate human faces that look very realistic. But they do not belong to any real person.
Types of GANs
There are various types of GANs, as shown below.
1. Vanilla Gan
It is the basic type of GAN. It has a generator and a discriminator. It provided training in generating realistic data samples
2. Conditional GAN (CGAN)
These GANs have conditional information about the training process. Therefore, Data sample generation relies on specific input features and labels.
3. Deep Convolutional GAN (DCGAN)
These are popular and successful implementations of GAN. They use convolutional neural networks (ConvNets) instead of multi-layer perceptrons, and the layers are not completely connected.
4. Progressive GAN
Progressive GANs sequentially generate higher-resolution images. These start with low resolution and then increase image complexity during training.
5. CycleGANs
CycleGANs specialize in unpaired image-to-image translation tasks. So, images can be transformed from one domain to another without paired examples for training.
6. StyleGANs
StyleGANs control the style and appearance of the generated images.
7. Least Square GAN (LSGAN)
LSGANs introduce a least squares loss function. This loss is also known as the L2 loss. LSGAN has more stable training and improved convergence properties.
8. Laplacian Pyramid GAN (LAPGAN)
LAPGANs use a multi-scale approach to generate high-resolution images. These decompose the image generation process into multiple stages.
9. Super-Resolution GAN (SRGAN)
SRGANs are utilized for single-image super-resolution tasks, enhancing the resolution and quality of low-resolution input images.
Application Of Generative Adversarial Networks
There are various applications of GANs, as shown below.
1. Image Generation
You can generate pictures of fake people. For example, they can generate photographs of human faces, generate cartoon characters, generate examples for image datasets, etc.
2. Text Generation
You can generate text, articles, songs, and poems.
3. Music Generation
GANs can generate music by using a clone voice.
4. Super-resolution
You can create high-resolution images from lower-resolution images.
5. Image editing
GANs find applications in image editing.
6. Medical image analysis
GANs find utility in classification and segmentation tasks, enabling the detection and diagnosis of diseases and disorders.
7. Cybersecurity
You can generate adversarial examples to identify malware even when other systems would have failed.
Other applications of GANs include:
- Image-to-Image Translation
- Face Frontal View Generation
- New human poses
- Photos to Emojis
- Face Aging
- Clothing Translation
Architecture of GANs
The GAN architecture has two components: Generator and Discriminator. The explanation for these is as follows.
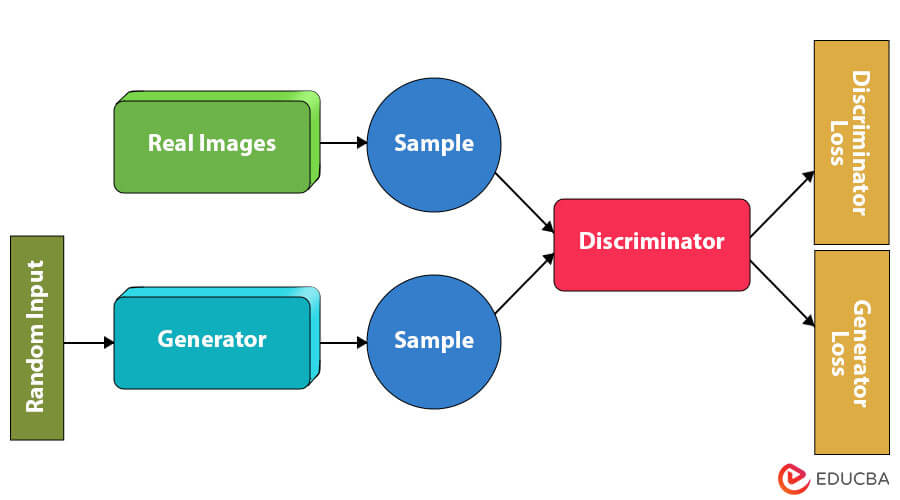
You can assume the generator is the thief and the discriminator is the police. Both use backpropagation to reduce loss during training.
1. Generator
The generator is a convolutional neural network. It learns to generate synthetic data that the discriminator can train. The generator aims to create outputs that could be mistaken for real data. It takes a fixed-length random vector carrying noise as input and generates a sample. The initial data of the generator is likely to be random noise because it starts with little knowledge about the true data distribution. Over time, as the GAN undergoes training. The generator learns to produce data that approximates the real data distribution.
There are important parts of the generator in the training phase:
- Noisy input vector. It is input provided to the generator.
- Generator network. It transforms the random input into a data instance.
- Discriminator network. It classifies the generated data as real or fake.
- Generator loss. It penalizes the generator for producing data for which the discriminator fails to correct output.
Backpropagation adjusts each weight in the correct direction.
Generator Loss
The generator’s purpose is to fool the discriminator, so it should minimize its losses to achieve this goal. Thus, you need to maximize the log probability to accomplish this. Thus, the discriminator can be deceived, classifying the generated samples as real. Below is the generator’s loss function.
![]()
Where D has log probability, D(G(z)) measures its likelihood of classifying generated data from G as authentic.
2. Discriminator
The discriminator is a deconvolutional neural network. It receives real and generated data samples as input and distinguishes between the two categories. It identifies real and generated data. The discriminator learns to model the probability of real or fake examples based on the input features. Its output probabilities are classification labels.
The discriminator connects to two loss functions but actively uses only the discriminator loss. The discriminator classifies both real data and fake data from the generator. It penalizes the discriminator for misclassifying real data as fake or fake data as real. The discriminator then updates its weights through backpropagation of the discriminator loss through the discriminator network.
Discriminator Loss
The discriminator’s purpose is to label the output correctly. The discriminator aims to correctly classify fake images as fake and original images as original. Hence, it should minimize the likelihood of a negative log. Below is the provided loss function.
![]()
Also, the minimax loss formula for the discriminator is given below.
![]()
Given a distribution, p(z) represents normal/uniform random noise with generator and discriminator, respectively, being G and D. D(x) represents the ability to identify real data, and D(G(z)) measures the likelihood of classifying generated data from G as authentic. The x is the actual data sample.
How does a GAN work?
The working principle of a GAN is grounded in the generator’s objective. It involves a competitive learning process between the generator and discriminator:
1. Initialization
In the first step, you must provide random weights to initialize the generator and discriminator.
2. Training Iterations
In each iteration, the generator generates samples. The discriminator, on the other hand, classifies both real and fake samples.
3. Adversarial Learning
The generator updates its weights to produce more convincing samples. It generates samples to fool the discriminator. Meanwhile, the discriminator adjusts its weights to improve classification accuracy.
4. Convergence
The training continues until an equilibrium is reached. At that point, the generator generates samples indistinguishable from real data, and the discriminator cannot reliably differentiate between real and fake samples.
Implementation of GAN
Code:
# Step-1 : Import necessary libraries
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
# Set device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Step-2: Define data transformations
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# Step-3: Load and preprocess the dataset
train_dataset = datasets.CIFAR10(root='./data',\
train=True, download=True, transform=transform)
dataloader = torch.utils.data.DataLoader(train_dataset, \
batch_size=32, shuffle=True)
# Step-4: Set up model parameters
latent_dims = 100
learning_rate = 0.0002
beta_1 = 0.5
beta_2 = 0.999
num_epochs = 5
# Step-5: Create Generator class
class Generator(nn.Module):
def __init__(self, latent_dims):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(latent_dims, 128 * 8 * 8),
nn.ReLU(),
nn.Unflatten(1, (128, 8, 8)),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128, momentum=0.78),
nn.ReLU(),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64, momentum=0.78),
nn.ReLU(),
nn.Conv2d(64, 3, kernel_size=3, padding=1),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
return img
# Step-6: Create Discriminator class
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1),
nn.LeakyReLU(0.2),
nn.Dropout(0.25),
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),
nn.ZeroPad2d((0, 1, 0, 1)),
nn.BatchNorm2d(64, momentum=0.82),
nn.LeakyReLU(0.25),
nn.Dropout(0.25),
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(128, momentum=0.82),
nn.LeakyReLU(0.2),
nn.Dropout(0.25),
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256, momentum=0.8),
nn.LeakyReLU(0.25),
nn.Dropout(0.25),
nn.Flatten(),
nn.Linear(256 * 5 * 5, 1),
nn.Sigmoid()
)
def forward(self, img):
validity = self.model(img)
return validity
# Step-7: Build the Generative Adversarial Network architecture
generator = Generator(latent_dims).to(device)
discriminator = Discriminator().to(device)
# Loss function
adversarial_loss = nn.BCELoss()
# Optimizers
optimizer_G = optim.Adam(generator.parameters()\
, lr=learning_rate, betas=(beta_1, beta_2))
optimizer_D = optim.Adam(discriminator.parameters()\
, lr=learning_rate, betas=(beta_1, beta_2))
# Step-8: Train the GAN model
# Training loop
for epoch in range(num_epochs):
for i, batch in enumerate(dataloader):
# Convert list to tensor
real_images = batch[0].to(device)
# Adversarial ground truths
valid = torch.ones(real_images.size(0), 1, device=device)
fake = torch.zeros(real_images.size(0), 1, device=device)
# Configure input
real_images = real_images.to(device)
# ---------------------
# Train Discriminator
# ---------------------
optimizer_D.zero_grad()
# Sample noise as generator input
z = torch.randn(real_images.size(0), latent_dims, device=device)
# Generate a batch of images
fake_images = generator(z)
# Measure discriminator's ability
real_loss = adversarial_loss(discriminator\
(real_images), valid)
fake_loss = adversarial_loss(discriminator\
(fake_images.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
# Backward pass and optimize
d_loss.backward()
optimizer_D.step()
# -----------------
# Train Generator
# -----------------
optimizer_G.zero_grad()
# Generate a batch of images
gen_images = generator(z)
# Adversarial loss
g_loss = adversarial_loss(discriminator(gen_images), valid)
# Backward pass and optimize
g_loss.backward()
optimizer_G.step()
# ---------------------
# Progress Monitoring
# ---------------------
if (i + 1) % 100 == 0:
print(
f"Epoch [{epoch+1}/{num_epochs}]\
Batch {i+1}/{len(dataloader)} "
f"Discriminator Loss: {d_loss.item():.4f} "
f"Generator Loss: {g_loss.item():.4f}"
)
# Save
if (epoch + 1) % 5 == 0:
with torch.no_grad():
z = torch.randn(16, latent_dims, device=device)
generated = generator(z).detach().cpu()
grid = torchvision.utils.make_grid(generated,\
nrow=4, normalize=True)
plt.imshow(np.transpose(grid, (1, 2, 0)))
plt.axis("off")
plt.show()Output:

Note that as defined above, there will be 5 Epoch in this training. Moreover, the model will be saved in the Data directory:
In our case, the final output image is

Explanation
In the above code, we have implemented GAN using PyTorch. It will generate images resembling those in the CIFAR-10 dataset. It is a complete explanation of the above code.
1. Imports
Firstly, it imports all required libraries like PyTorch, torchvision, matplotlib, numpy, etc.
2. Set Device
It checks if CUDA (GPU support) is available. If so, sets the device accordingly.
3. Data Transformations
It defines transformations to apply to the dataset. For example, converting images to tensors and normalization.
4. Load and Preprocess Dataset
It downloads the CIFAR-10 dataset. Then it defines transformations. It creates a dataloader for batching and shuffling.
5. Model Parameters
It defines parameters like latent dimensions, learning rate, epochs, etc.
6. Generator Class
It defines the architecture of the generator neural network.
7. Discriminator Class
It defines the architecture of the discriminator neural network.
8. Build GAN Architecture
It instantiates generator and discriminator models. It has a loss function (Binary Cross Entropy Loss) and optimizers (Adam).
9. Training Loop
It iterates over epochs and batches. In each iteration, it trains the discriminator and generator alternately.
10. Progress Monitoring
It prints discriminator and generator losses at certain intervals during training.
At the end of every 5th epoch, it generates sample images using the generator and displays a grid of these images.
Advantages and Disadvantages of Generative Adversarial Network
| Advantages | Disadvantages |
| It creates realistic images with diverse data samples. | It has computational resources. |
| It is unsupervised learning. So, it can learn from data with little or no label information. | It may have an overfitting problem. So, it can produce synthetic data too similar to training data. |
| It is easy to train and often converges faster. | Its competitive nature can lead to training instability. |
| It is versatile in data generation. | It requires high storage and power budgets. |
| It has data argumentation and anomaly detection. | It has a sensitivity to hyperparameters. So, it requires careful tuning. |
Challenges and Limitations
Training GANs present various challenges and limitations. These include
1. Model can collapse
The generator may produce similar output images while taking different input features.
2. Non-convergence
GANs may fail to converge.
3. Instability
Optimization can be tricky and unstable in GAN
4. Lack of diversity
It can generate unrealistic, blurry, and less diverse images.
5. Stability and balancing between generator and discriminator
The discriminator should be flexible. The generator produces a particular output, which the discriminator then learns to always reject.
6. Positioning of objects
Problems in determining the positioning of objects.
7. Global objects
It needs to understand the global structure. It is similar to the problem of perspective.
8. Lack of proper evaluation metric
It is tough to estimate the likelihood of GANs.
Researchers have proposed many variants of GANs to overcome these challenges. For example, redesigning network architecture, changing the form of objective functions, altering optimization algorithms, etc.
Future of GANs
Despite the challenges, GANs improved over time. Their quality amazes us now. If accepted, GANs will continue to be important. It is still exploring what GANs can do.
- GANs can create music, code, video, and more. The future of GANs looks promising.
- Developers will soon implement GANs across diverse industries. These are most successful in visual works.
- GANs are also helping in medical research. Dental crowns can be made faster with GANs. These improve augmented reality visualizations.
- These prepare training data for machine learning.
Many research topics on GAN are still important for data privacy. The past year saw several GAN advancements.
Conclusion
Generative Adversarial Networks (GANs) are a kind of neural network. As the name suggests, it has three parts: Generative, Adversarial, and Networks. GAN has a generator and discriminator. The generator generates new data. The discriminator network tries to identify which data is real or fake. This competition between the two components goes on until a level of perfection is achieved. It means the generator wins, and the discriminators fail. It is unsupervised learning. It also has disadvantages like computational cost, Overfitting, training instability, etc. But, GANs are important in AI and have various use cases like image generation, text generation, etc.
Frequently Asked Questions (FAQs)
Q1: How are GANs evaluated for their performance?
Answer: GANs use evaluation metrics like Inception Score (IS), Frechet Inception Distance (FID), Precision and Recall, etc. These metrics assess the generated samples’ quality, diversity, and realism compared to real data distribution.
Q2: How does GANsl handle multi-modal data generation?
Answer: Multi-modal GANs generate data with multiple modalities. For example, images can be generated from text descriptions and vice versa.
Q3: Can GANs be used for anomaly detection in datasets?
Answer: Yes. It first trains on normal data and then identifies anomalies as data points that deviate from the learned distribution. However, this approach may require modifications to standard GAN architectures and loss functions to detect anomalies effectively.
Recommended Articles
We hope this EDUCBA information on “Generative Adversarial Network” benefited you. You can view EDUCBA’s recommended articles for more information,

