Updated March 16, 2023

Introduction to Hadoop Distributed File System (HDFS)
HDFS is the Hadoop distributed file system, and it is like the data storage system Hadoop handles, and it is used to build the type of applications. It belongs to the big data type storage records, referred to as the Name node. Also, it comes under the data node, which is on the architecture to implement the distributed file system and increase the high-performance CPU usage in the clusters.
What is Hadoop Distributed File System?
Hadoop technology is mainly used for the HDFS system called the Hadoop distributed file system, and it is the primary storage file system used by the Hadoop application. Also, it is referred to as the NameNode and DataNode architecture for implementing the distributed file system that mainly provides the huge performance of the CPU that provided access to the global data for open source distributed processing framework that will manage the data processing software applications and its mainly called for data storage in the big-data application. Process any data that can be handled by using the client and submitting the server data to perform the data operations with the help of algorithms like MapReduce.
HDFS Architecture
The Hadoop file system uses both primary and secondary architecture that can be configured using the node clusters, and its mainly used in the primary data storage server system. It has the main central component system, mainly in the node name, which contains the name node to maintain and manage the file system and the namespace to provide the client with correct and exact security access permissions to the users. The user system also contains the DataNodes to manage the system storage for attached the nodes to use the exact file system namespace for enabled user datas in the file storage. The main feature of the HDFS is that the file system facilitates the big data, and it is more partitioning of the big data, which contains the HDFS to the multiple machines.
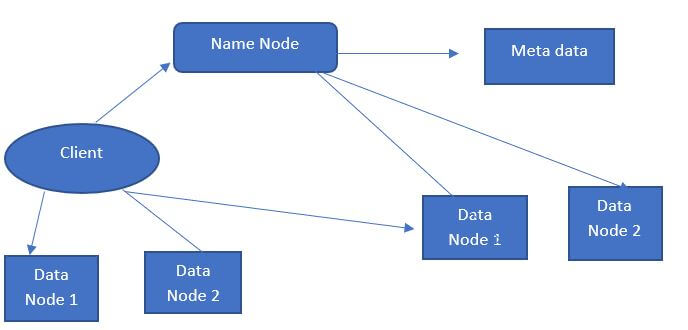
The above diagram is the architecture of the HDFS system; here, the name node and data node are the two types of nodes that contain the client and metadata as the parent node to execute the node operations in the HDFS system.
HDFS Alternatives
The HDFS has the big alternative and is mainly processed with big data processing and distributed with the Hadoop HDFS, including analytics.
Some of them are the HDFS alternatives are as follows:
Google BigQuery, Vertica, Snowflake, Cloudera, Microsoft SQL Server, etc. Some HDFS Alternatives have replaced the Map-Reduce or MapR’s that mainly offer better performance as the read and write file system using the native NFS.
- Google BigQuery: It’s fully managed, petabyte-scale with a low-cost enterprise data warehouse for big analytics. It’s a serverless infrastructure for managing the database administrator for focusing and analyzing the data with the familiar SQL.
- Snowflake: One of the cloud data platforms helps to use the shatters and barriers with the same organization for the valuable datas.
- Cloudera: It’s a modern big data platform that the Apache Hadoop powers at the main core of the application. It provides a central scalable, flexible, secure environment to handle workloads from batch processing to interactive real-time analytics.
- Microsoft SQL Server: In sql server management studio, we can create a server and linked connection for the Hadoop system with the following commands like Exec master.dbo.sp_addlinkedserver. With the help of the Microsoft Analytics Platform System(APS) will offer and access the Hadoop data sources through the polybase technology. It mainly includes the bidirectional access for Hadoop on the cloud-based services.
Example of Hadoop Distributed File System (HDFS)
Different examples are mentioned below:
Code:
Cross-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>Mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop-3.3.0/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop-3.3.0/data/datanode</value>
</property>
</configuration>Yarn-site.xml:
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>Output:
HDFS Command Example
Different HDFS Command examples are mentioned below:
1. Hdfs dfs -mkdir /may11hadoop.

2. Which is used to create the mkdir for the Hadoop file system on the specified location?
3. Hdfs dfs -ls -copyFromLocal filepath /may11hadoop.
4. The above hdfs command is used to copy the file path to the specified directory. The copyfromLocal is one of the hdfs commands mainly used to copy the file from the local file path system to the HDFS(Hadoop Distributed File System); it has the main option for switching replace the datas from the existing file in the system. It is configured to the system and updated to the specified file already present in the same folder and copied the same also; it throws the error through automatically.
5. CopyFromLocal command is like the put command in the HDFS system for the synonym in the hdfs dfs. It can take multiple parameters, and the set of arguments is specified in the source and target file location path. In contrast, the file is copied with the specified directory.
6. Hdfs dfs -ls /may11hadoop.

Here the may11hadoop directory does not contain any files, so it will not be shown any results while we execute the command.

We can check the specified directory permissions using the hdfs dfs -ls/command to get the directory chmod details. Moreover, we can change the chmod type with the help of features like chmod 777; based on the requirement, we can access and configure the file mode.
Conclusion
The hdfs file system is a distributed file system that shares the features that already created the nameNode and datanode in the Hadoop generating system. Using the format command, the Hadoop file system will generate the replica of the file data, and it is highly fault-tolerant with low-cost deployed hardware.
Recommended Articles
This is a guide to Hadoop Distributed File System (HDFS). Here we discuss the introduction, architecture, alternatives, and examples. You may also have a look at the following articles to learn more –
